[PostgreSQL] 최적화: 실행 계획 분석 -1
대다수의 RDB들과 마찬가지로, postgres 또한 비용 기반의 쿼리 최적화 기능을 구현한다.
특정 연산들에 경험을 통한 비용 점수를 매겨놓고, 가장 낮은 비용의 실행이 되도록 쿼리를 구체화하는 것이다.
예를 들어 seq scan 방식으로 블록을 하나 읽는건 1점이고, index scan 방식으로 읽는건 4점이다.
그럼 옵티마이저는 seq과 index를 선택할 수 있는 상황이라면 seq을 사용하는 방향으로 최적화를 수행할 것이다. (물론 여기엔 여러가지 변수가 있다.)
postgres에서는 explain 명령을 통해 특정 쿼리의 비용을 계산할 수 있다.
기본적으로 이건 실제로 쿼리를 수행하지는 않고 비용만 계산한다.
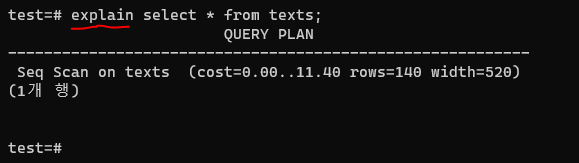 첫번째 숫자 0.00은 첫번째 레코드를 fetch하는 데 드는 비용.
첫번째 숫자 0.00은 첫번째 레코드를 fetch하는 데 드는 비용.
두번째 11.40는 마지막까지 fetch하는 데 드는 비용이다.
물론 이건 postgres에서 임의로 정해놓은 비용 점수라서 실제와는 다를 수 있다.
실제로 실행해서 시간을 보고 싶다면 analyze 명령을 추가하면 된다.

비용 계산해보기: 단순 조회
기본 명령어 사용법은 됐고, 한번 비용계산 구조를 역산해보자.
넉넉한 테스트를 위해 좀 든든한 양의 데이터를 만들겠다.
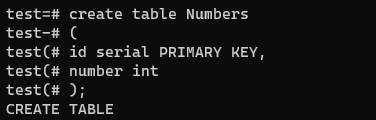
 간단한 테이블을 만들고 1000000개의 데이터를 삽입했다.
간단한 테이블을 만들고 1000000개의 데이터를 삽입했다.
그리고 실행 계획을 보면
 14425.50로 나왔다.
14425.50로 나왔다.
여기서의 비용 계산과정을 더듬어보면, seq scan으로 블록을 읽어오는 IO 비용과 모든 Row를 추출하는 CPU 비용을 합산한 값이라고 할 수 있다.
그리고 내부 테이블인 pg_class를 보면 그것들을 대략 유추할 수 있다.
 relpage가 블럭의 개수고, reltuple이 Row 데이터 개수다.
relpage가 블럭의 개수고, reltuple이 Row 데이터 개수다.
따라서 위의 비용은 44251(seq_scan) + 10000000.01(cpu_tuple 조회) + a의 합산으로 생각할 수 있다.
이번엔 where절로 조건을 달고 측정해보자
기본키인 id로 검색을 해봤다.
 그럼 탐색하는 개수만큼 비용이 줄어든 것을 확인할 수 있다.
그럼 탐색하는 개수만큼 비용이 줄어든 것을 확인할 수 있다.
근데 이건 기본키만 그런거고, 키가 아닌 목록으로 조건을 달 때는 얘기가 달라진다.
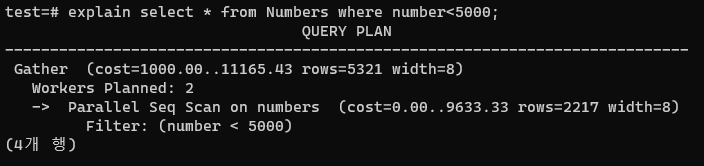 비용이 크게 줄지 않았다!
비용이 크게 줄지 않았다!
seq scan은 기본적으로 모든 레코드를 읽어오는 녀석이라 그렇다.
그리고 거기에 더해 레코드에 비교를 수행하는 개수만큼의 필터링비용(0.0025)이 추가된다.
그리고 조건이 추가될때마다 레코드*필터링비용이 계속 더해지는 것이다.
그래서 내가 참고한 책에 따르면 이전의 비용 14425보다 오히려 더 증가해야 할텐데.. 뭔가 달라진게 있거나 변수가 있는 것 같다.
일단 여기서 끊고 다음 포스트에서 이어나가도록 하겠다.
참조
"김시연&최두원 저, 『PostgreSQL 9.6 성능 이야기』, 시연아카데미(2017)"
https://postgresql.kr/docs/9.6/sql-explain.html