[PostgreSQL] 쿼리 최적화: 인덱스 태우기
초심자들이 흔히 하는 실수가 인덱스만 깔아두면 알아서 빠르게 잘 찾아올 것이라 생각하는 것이다.
일단 테이블부터 깔고 시작하겠다.
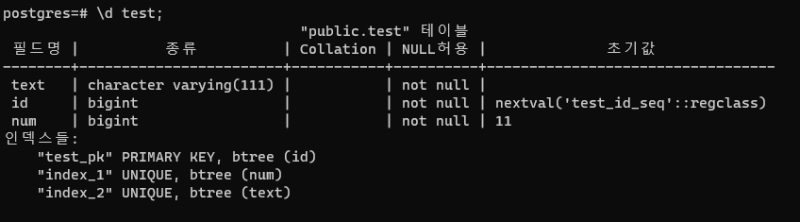 num와 text에 인덱스가 깔린 단순한 테이블이다.
num와 text에 인덱스가 깔린 단순한 테이블이다.
값은 10만개 정도만 들어있다.
여기서 검색을 한번 해보자.
select num, text from test where num = 11;이 쿼리는 어떻게 동작할까?
아무 문제가 없어보인다. 딱 인덱스 컬럼 num에 동등 비교를 했으니 인덱스를 잘 탈 것이다.
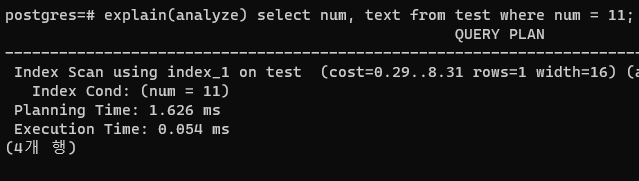 실제로도 그렇다.
실제로도 그렇다.
최적화 원칙1: 인덱스 컬럼 건드리지 마라
쿼리들을 보면 이런 식으로 인덱스 컬럼에 함수를 씌우거나 더하거나 빼는 등의 조건절을 짜는 경우가 많다.
select num, text from test where num+1 = 12;이런식으로 짜두면
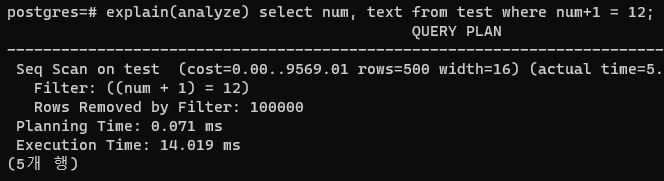 db가 인덱스를 태울 수가 없다.
db가 인덱스를 태울 수가 없다.
인덱스값을 완전히 바꿔버리는데 이걸 어떻게 찾겠는가.
그래서 여기서도 인덱스를 태우지 못하고 풀스캔을 때린 다음, 인덱스 컬럼에 연산을 가하는 조건절을 수행한다.
캐스팅도 마찬가지다.
select num, text from test where num::TEXT = '11';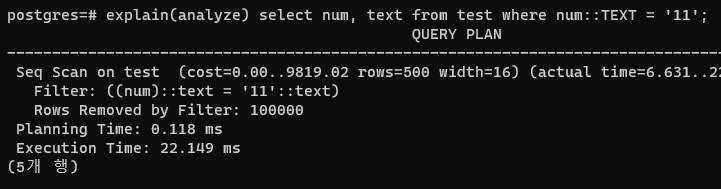
like 사용시
like에 아무개 패턴 %을 사용하는 경우에도 인덱스 스캔을 유도하기 어렵다.
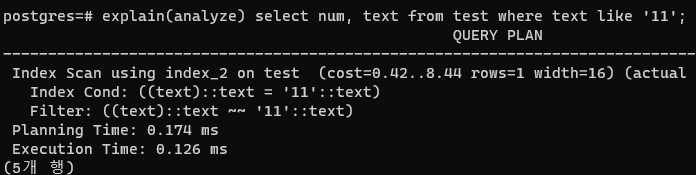 패턴 없이 쓰면 당연히 아무 문제가 없지만
패턴 없이 쓰면 당연히 아무 문제가 없지만
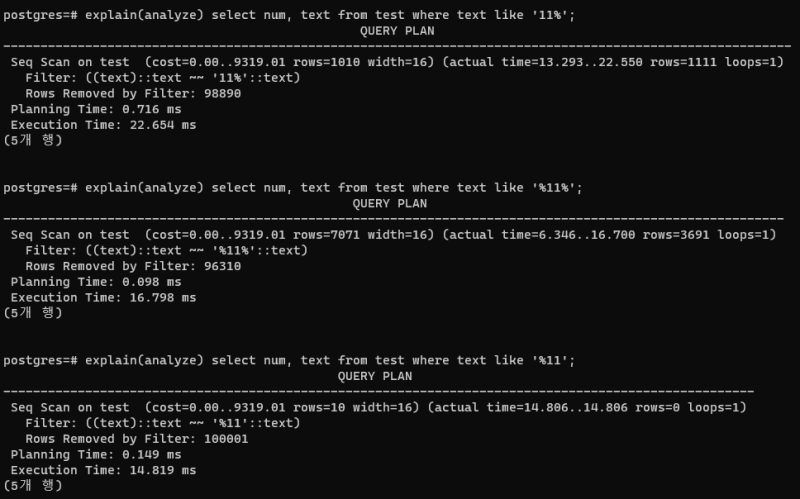 패턴이 들어가면 인덱스 스캔이 깨진다.
패턴이 들어가면 인덱스 스캔이 깨진다.
다른 DBMS들의 경우에는 %이 앞에 들어가지 않고 'text%' 같은 식이면 인덱스를 탄다고 하는데, postgres는 다른 것 같다. 인덱스 생성시에 연산자 클래스라는 것을 지정해줘야 한다.

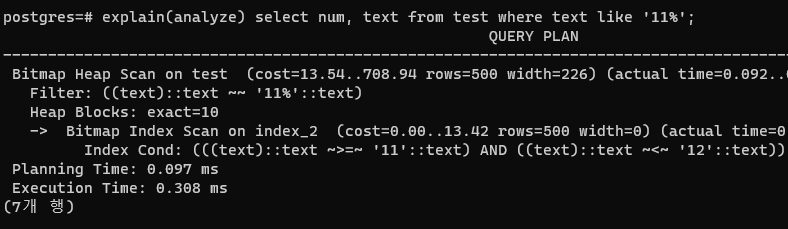 그럼 후행 와일드카드의 경우에는 인덱스를 이용할 수 있다.
그럼 후행 와일드카드의 경우에는 인덱스를 이용할 수 있다.
비트맵이긴 하지만
와일드카드가 앞에 붙는 건 여전히 안된다. 다른 방법을 사용해야 한다.
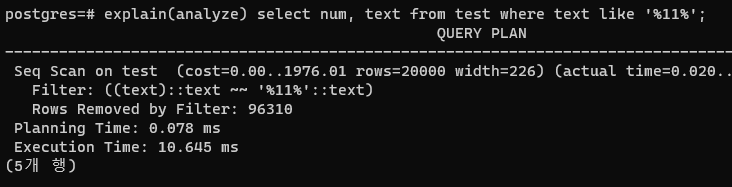
그리고 gin이나 gist, 연산자 클래스 등을 사용하면 이런 처리를 보다 쉽게 할 수 있다고 하는데, 이는 차후 정리해보겠다.
인덱스 추가설정
앞서 언급했듯이, 인덱스 컬럼에 함수를 씌우는 건 자제해야 한다.
그래서 아래와 같이 소문자로 바꿔서 비교를 한다든지 하면
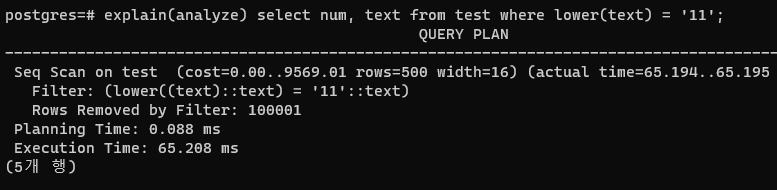 인덱스 스캔을 하지 못한다.
인덱스 스캔을 하지 못한다.
그런데 인덱스에 함수 등의 연산을 가해도 인덱스 스캔이 수행될 수 있도록 하는 방법이 있다.
 인덱스 생성 시에 해당 컬럼에 함수를 씌워버리는 것이다.
인덱스 생성 시에 해당 컬럼에 함수를 씌워버리는 것이다.
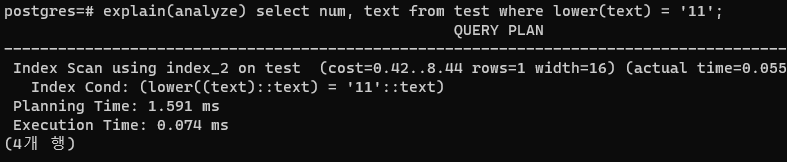 그럼 인덱스를 탄다!!
그럼 인덱스를 탄다!!
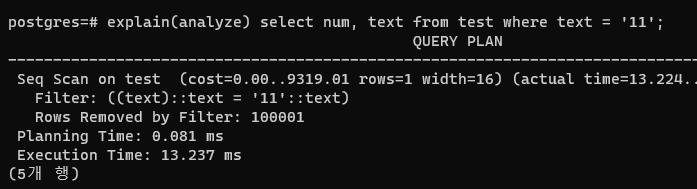 그대신 함수를 함께 사용하지 않으면 인덱스를 타지 않는다는 한계가 있다.
그대신 함수를 함께 사용하지 않으면 인덱스를 타지 않는다는 한계가 있다.
참조
https://www.postgresql.org/docs/9.1/indexes-expressional.html