[PostgreSQL] copy를 이용한 대량 삽입 (bulk insert)
아주 방대한 데이터를 다루는 시스템의 경우에는, 대량으로 데이터를 삽입하는 경우 또한 많다.
그럴때는 항상 엄청난 시간을 잡아먹는데... 그 소요시간을 좀 줄여볼 방법이 있다.
copy 명령어를 사용하는 것이다.
이걸 사용하면 삽입할 데이터들을 텍스트파일에다 저장해놓고, 그걸 그대로 가져올 수 있다.
데이터파일의 형식은 기본적으로 한 줄당 한 데이터를 뜻하며, 컬럼을 구분하는 글자는 직접 지정할 수 있다.
copy는 아래의 구조를 가진다.
copy 테이블명(컬럼명, ...) from '...파일경로' with delimiter '컬럼 구분자'테스트할 테이블은 이렇게 생겼다.
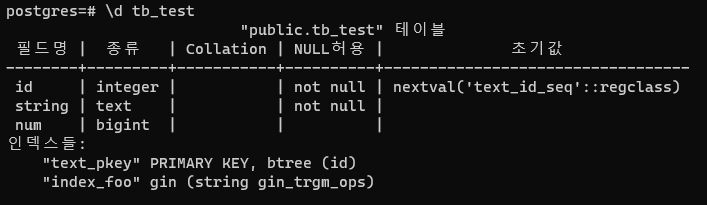 별거없다.
별거없다.
한번 테스트데이터를 만들어서 돌려보자
나는 아래와 같은 자동화 코드로 쿼리와 데이터파일을 생성했다.
데이터는 100만개고 코드는 Rust다.
use rand::Rng;
fn main() {
let values_nums: Vec<String> = (1..=10000000)
.map(|_| {
let mut rander = rand::thread_rng();
let num: i64 = rander.gen();
format!(r#"('NO.{}', {})"#, num, num)
})
.collect();
let text_nums: Vec<String> = (1..=10000000)
.map(|_| {
let mut rander = rand::thread_rng();
let num: i64 = rander.gen();
format!(r#"'NO.{}', {} "#, num, num)
})
.collect();
let values = values_nums.join(", ");
let query = format!(
r#"
explain analyze
insert into tb_test(string, num)
values {}
"#,
values
);
let text = text_nums.join("\n");
std::fs::write("query.sql", query).expect("쓰기 실패");
std::fs::write("just_text.txt", text).expect("쓰기 실패");
}그래서 삽입 쿼리는 이런식으로 만들고

copy할 데이터는 이렇게 만들었다.
일단 기존의 방식대로 그냥 insert를 사용해보자
 분석시간 약 약 3초 + 실행시간 약 194초가 걸렸다.
분석시간 약 약 3초 + 실행시간 약 194초가 걸렸다.
거의 197초가 걸린 셈이다.
그리고 copy를 사용해봤다.
윈도우의 경우에는 데이터파일을 public 경로에 둬야만 읽어올 수 있으니 유의바란다.
 copy는 쿼리도 아니고 실행계획같은게 없어서 explain은 못했는데, 스톱워치로 직접 재본 결과로는 185초 정도가 걸렸다.
copy는 쿼리도 아니고 실행계획같은게 없어서 explain은 못했는데, 스톱워치로 직접 재본 결과로는 185초 정도가 걸렸다.
그리고 데이터의 크기가 커질수록 copy의 성능이 더 좋아진다고 한다. 잡다한 체크같은게 없이 무작정 집어넣기만 하기 때문이란다. 실행계획 계산도 안하고.
근데 뭐.. 일반적인 상황에는 활용할 일이 딱히 없는게, 수가 엄청 많은게 아니면 그렇게 막 빠른 것도 아니다.
돌려보니까 10만개까지는 성능이 거의 비슷하고, 100만개부터 성능이 좀 벌어졌다.
데이터가 거의 억단위로 가면 확 벌어진다고 한다.
참조
https://www.postgresql.org/docs/9.5/sql-copy.html
https://stackoverflow.com/questions/758945/whats-the-fastest-way-to-do-a-bulk-insert-into-postgres
https://warpgate3.tistory.com/entry/Postgresql-Bulk-Insert-From-File