패스워드 암호화
웹서비스 등에서 패스워드는 당연히 암호화의 대상이다. 혹여라도 DB가 털리면 다 작살나는게 아닌가.
가끔 페이스북같은 정신나간곳은 하지 않지만, 패스워드는 암호화를 해서 저장하는게 기본이다.
그럼 어떻게 암호화를 하는가?
개인정보같은건 서버 입장에서 그 값 자체를 유효하게 사용할 수 있다. 그래서 복호화가 가능한 방법으로만 암호화를 한다.
하지만 패스워드는 굳이 원본값을 알 필요가 없다. 사용자가 패스워드를 동일하게 날렸는지 아닌지만 확인하면 되는 것이다.
그래서 패스워드 저장에는 복호화를 할 수 없는 "단방향 암호화" 기법들을 주로 사용한다.
말은 어려운데 그냥 해싱하는거다. 해싱 기반으로 엄청나게 복잡한 다양한 방법들을 사용해서 꼬아놓는 것이다.
그렇게 서버에서 해싱을 해서 저장해두면. DB가 털리더라도 해싱된 패스워드값으론 뭘 할 수가 없다.
해싱 알고리즘으로는 sha256, sha512, bcrypt 등을 사용하는 것을 추천한다.
해싱의 취약점
근데 단순히 해싱을 한번 때리는 것만으론 좀 부족하다.
해싱은 기본적으로 입력값이 같으면 출력값이 항상 같다는 성질을 갖고있다.
그리고 sha256 rainbow table이라고 검색해보면 해커들이 시도해봤던 패스워드와 해싱값의 테이블목록이 있다.
그렇다... 테이블에 있는 전형적인 암호들은 그냥 털릴 수가 있는 것이다.
그럼 이걸 어떻게 또 돌려막아야 할까?
일반적으로 사용되는 기법은 2가지가 있다.
1. 해싱 두번 때리기(key stretching)
이러면 경우의 수가 기하급수적으로 늘어나기 때문에
해커들의 입장에서 브루트포스를 날리기 아주 힘들어진다.
근데 근본적인 해결은 아니라 그닥 아름답게 느껴지진 않는다.
2. salt
또 하나의 방법은 패스워드를 해싱하기 전에 임의의 랜덤문자열을 붙여놓고 해싱을 돌리는 것이다.
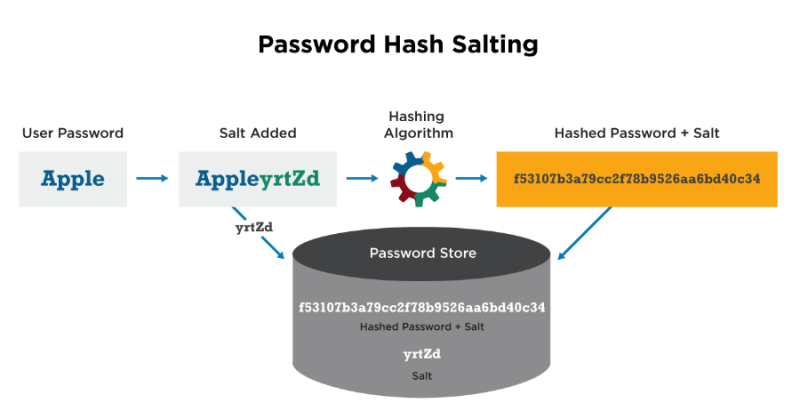 이걸 소금을 친다(salting)고 표현한다.
이걸 소금을 친다(salting)고 표현한다.
붙이는 랜덤값이 소금이다.
그리고 랜덤값은 사용자 정보 DB에 함께 보관해둔다.
다시 패스워드를 검증할 때는 보관해둔 랜덤값을 가져와서 비교하면 된다.
이러면 해커 입장에서는 해싱된 패스워드를 획득하더라도.. 뭘 어떻게 하기가 난감해지는 것이다. 랜덤값으로 해싱된걸 무슨 수로 추측하겠는가.
대충 그렇다.
참조
https://st-lab.tistory.com/100
https://starplatina.tistory.com/m/entry/%EB%B9%84%EB%B0%80%EB%B2%88%ED%98%B8-%ED%95%B4%EC%8B%9C%EC%97%90-%EC%86%8C%EA%B8%88%EC%B9%98%EA%B8%B0-%EB%B0%94%EB%A5%B4%EA%B2%8C-%EC%93%B0%EA%B8%B0
https://cyberhoot.com/cybrary/password-salting/