[Javascript] 퍼펫티어(puppeteer)로 크롤링 해보기
퍼펫티어는 일종의 Headless Browser를 제공하는 Node.js 라이브러리다.
헤드리스 브라우저란 간단하게 말하자면 UI가 없는 브라우저다. 불필요한건 전부 날리고 브라우저의 기능 자체에만 집중해둔 것이다.
진짜로 브라우저를 띄워버려서 겁나게 느린 셀레니움과는 다르게, 어느정도의 성능 효율은 나오고, 그래서 크롤링에 많이 쓰인다.
먼저 설치해보자. 기본설정은 너무나 간단하다.
그냥 깔기만 하면 된다.
스크린샷 찍어보기
퍼펫티어로 네이버에 접속해서 스크린샷 하나 찍어보는 코드를 작성해보겠다.
별거없다.
goto로 페이지에 접속한 후, 스크린샷 메서드를 사용하면 된다.
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch(); // 브라우저 실행
const page = await browser.newPage(); // 페이지 창 하나 생성
await page.goto("https://naver.com"); // 네이버 페이지로 접속
await page.screenshot({ path: "foo.png" }); // 화면 스크린샷으로 찍기
await browser.close();
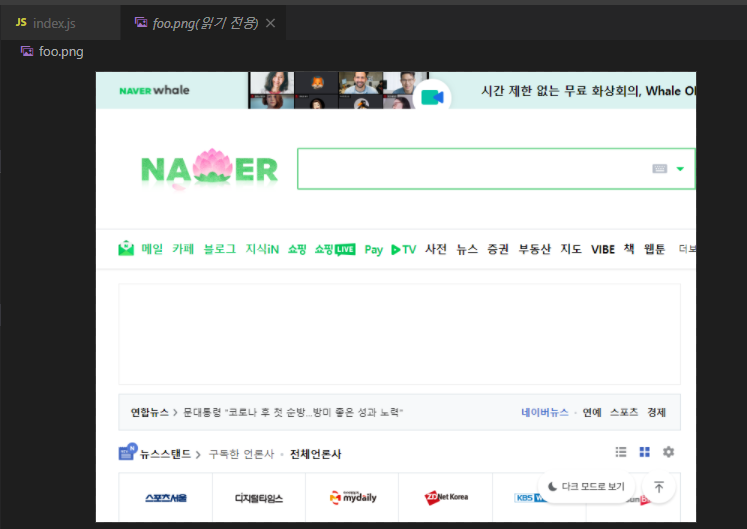
})();그럼 이렇게 잘 찍힐 것이다.
지연시간 걸어주기
그런데 위의 스크린샷은 좀 부족한 면이 있다.
실제 네이버 페이지는 이렇게
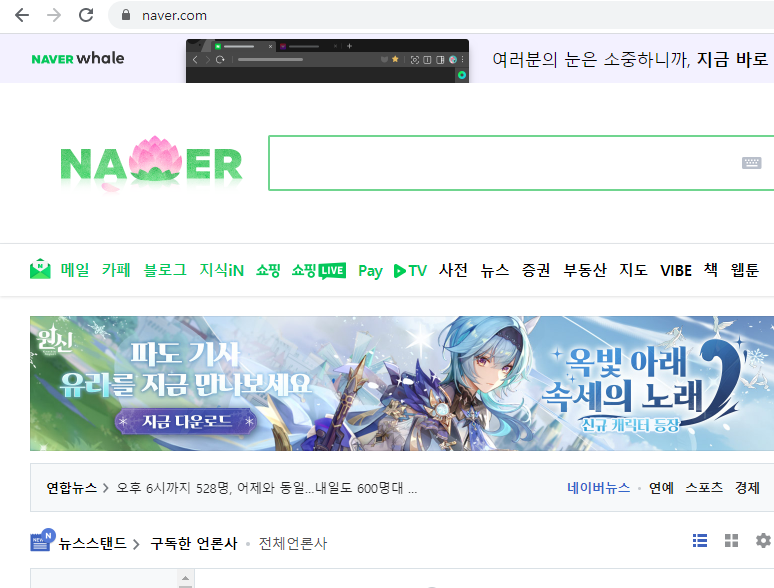 광고까지 다 렌더링이 되는데, 저 스크린샷에는 찍히지 않았기 때문이다.
광고까지 다 렌더링이 되는데, 저 스크린샷에는 찍히지 않았기 때문이다.
이건 페이지로 들어가자마자 후딱 찍어버려서 그렇고, 이런걸 처리하고 싶다면 waitUntil로 지연시간을 걸어주면 된다.
networkidel0 값을 옵션으로 넣어주면, 네트워크 통신이 더는 일어나지 않는다고 판단할 때까지 좀 기다려준다. 판단 시간 기준은 500ms다. 통신 다 됐으면 렌더링도 다 됐다고 봐도 되니까...
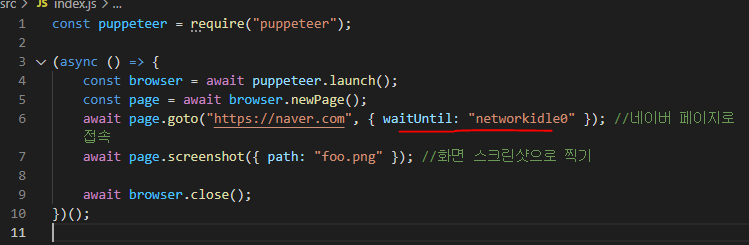
그럼 이제 제대로 찍힐 것이다.
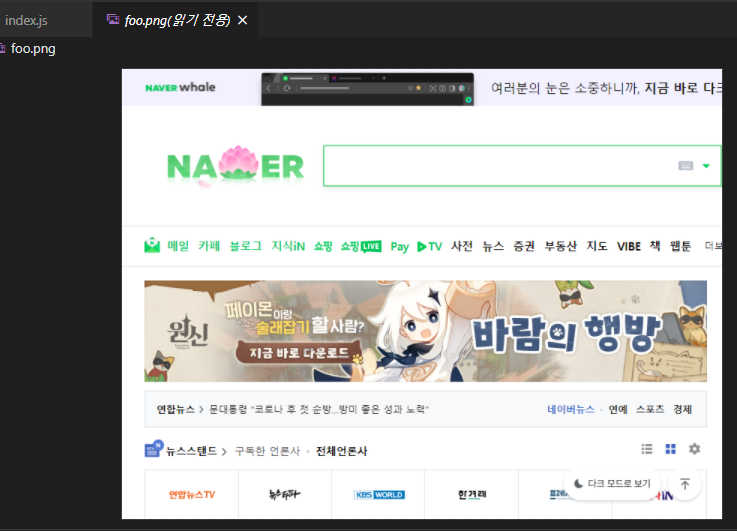
클릭하기
이번엔 네이버 메인페이지에서 버튼을 클릭해서 이동하는 것을 적용해보도록 하겠다.
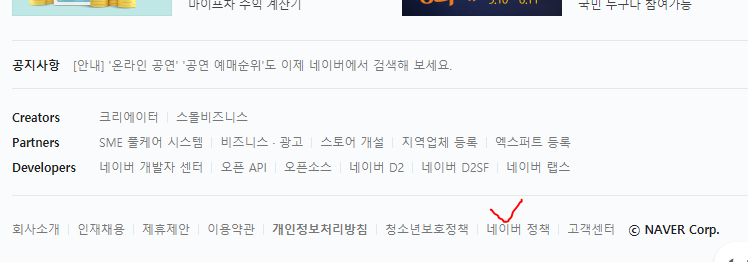
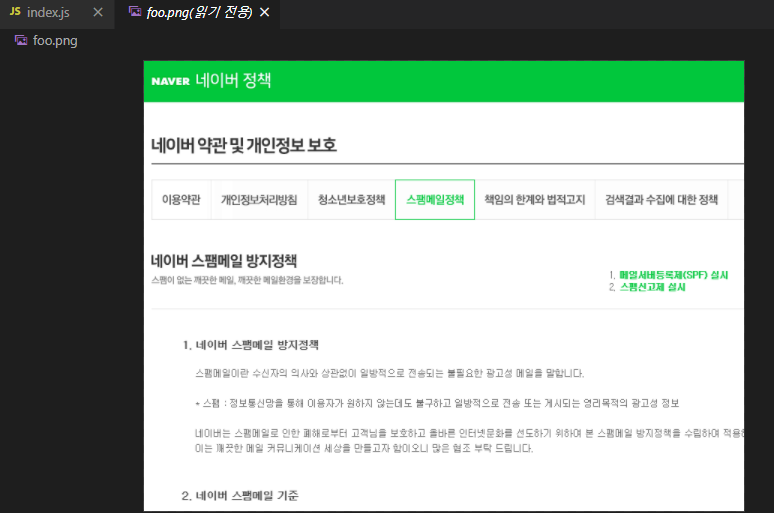
저기 아래에 있는 네이버 정책으로 한번 들어가보겠다.
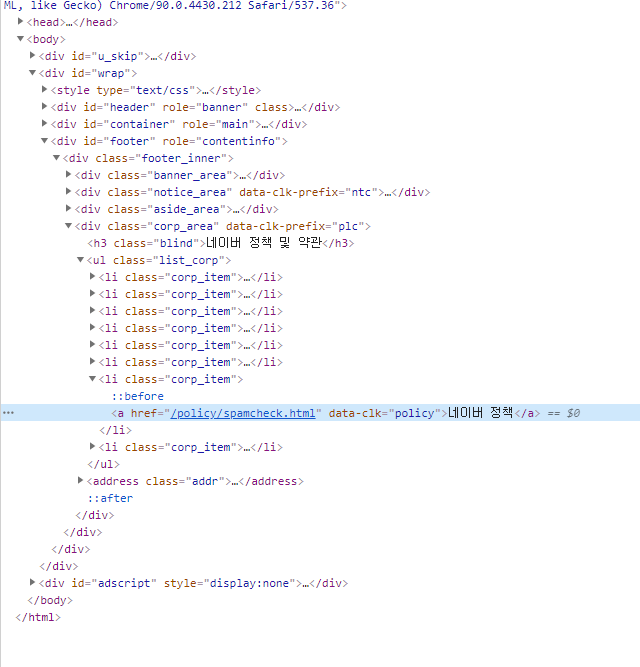
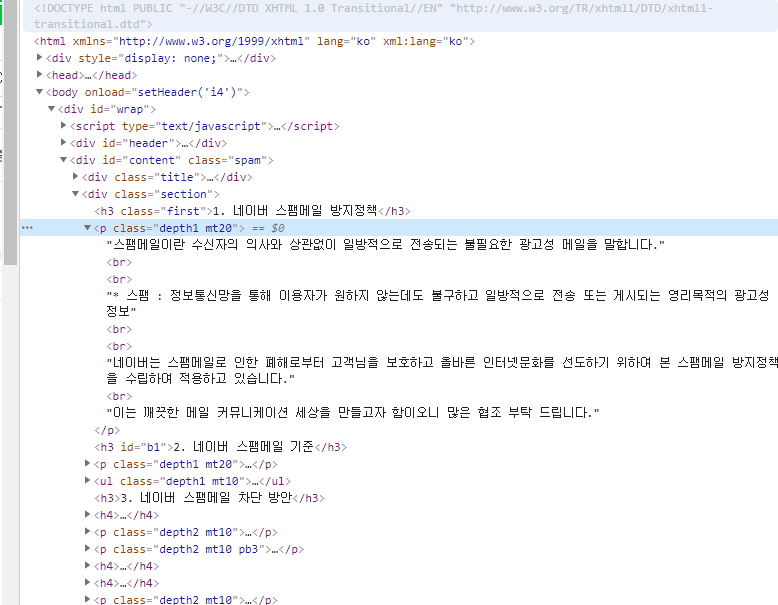
개발자도구로 소스를 뜯어보고, 버튼을 누를 요소의 css selector를 잘 추출해낸다.
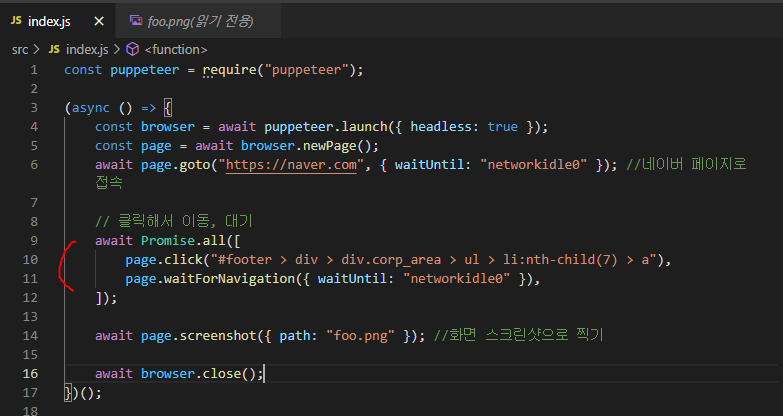
그리고 아래와 같이 작성하면 된다.
click 메서드에 클릭할 요소의 selector를 넣고, waitForNavigation으로 렌더링을 기다려주면 된다.
그럼 잘 가져올 것이다.
HTML 텍스트 읽기
이번에는 텍스트를 한번 읽어오도록 해보자.
저기 스팸메일 뭐시기 하는부분을 가져와보도록 하겠다.
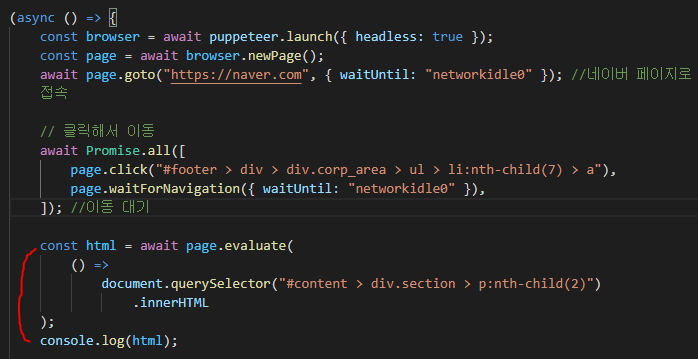
page.evaluate 함수에 select를 반환하는 클로저를 전달해주면 된다.
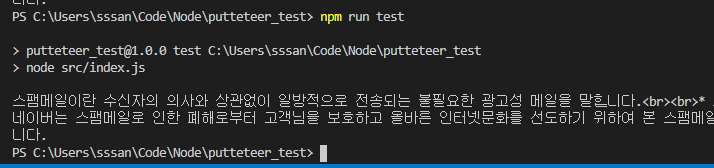
그럼 그 요소값을 잘 읽어올 것이다.
실 브라우저로 테스트해보기
퍼펫티어는 기본적으로 headless 브라우저지만, head를 가진 상태로도 사용할 수가 있다.
headless은 직접 확인하면서 테스트하는 것이 불편하다는 단점이 있기 때문에.. 가끔은 유용할 떄가 있을 것이다.
방법은 어렵지 않다. 그냥 launch할때 headless 옵션값을 false로 주면 된다.
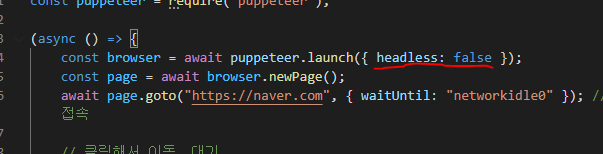
그럼 실제 동작과 동시에 브라우저에서 돌아가는 모양이 그대로 보일 것이다.
그렇다.
참조
https://www.npmjs.com/package/puppeteer
https://engineering.linecorp.com/ko/blog/using-headless-chrome-with-chatbots/