[MySQL] 쿼리 최적화
MySQL은 다른 RDB들에 비해서 옵티마이저의 최적화 능력이 많이 부실한 편이다.
그래서 쿼리를 짤때마다 신경을 좀 많이 써줘야 한다.
테스트에 사용할 테이블은 다음과 같다.
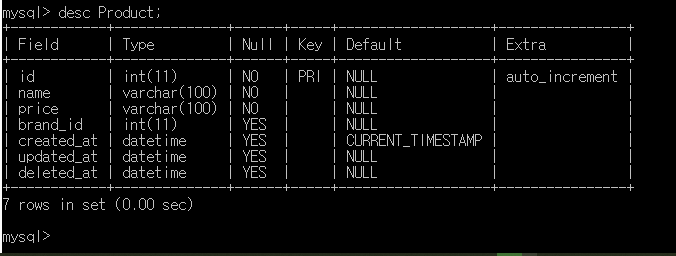 상품 테이블. 아래 Brand의 참조키인 brand_id를 가진다.
상품 테이블. 아래 Brand의 참조키인 brand_id를 가진다.
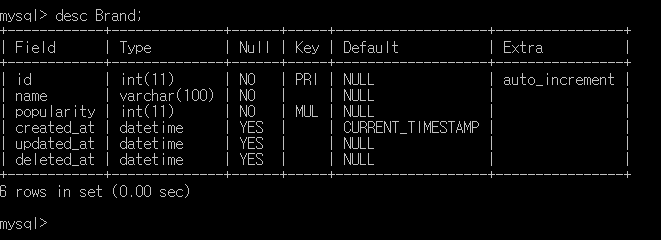 브랜드 테이블.
브랜드 테이블.
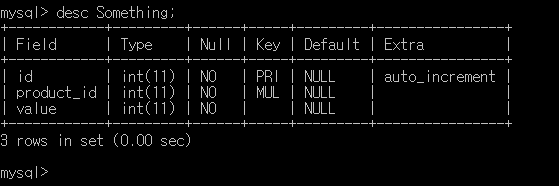 그리고 상품 테이블에 1:1 대응되는 아무개 테이블.
그리고 상품 테이블에 1:1 대응되는 아무개 테이블.
정렬에 사용할 것이다.
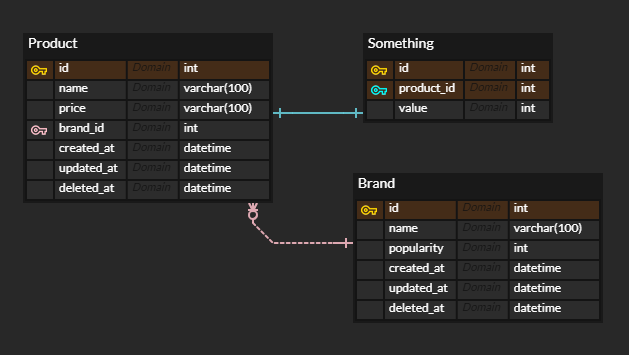
그리고 이것들을 이용해서 대강 다음과 같은 쿼리가 사용된다고 가정한다.
select a.*, b.name as brand_name
from Product a
join Brand b
on a.brand_id = b.id
join Something c
on a.id = c.product_id
order by c.value
limit 100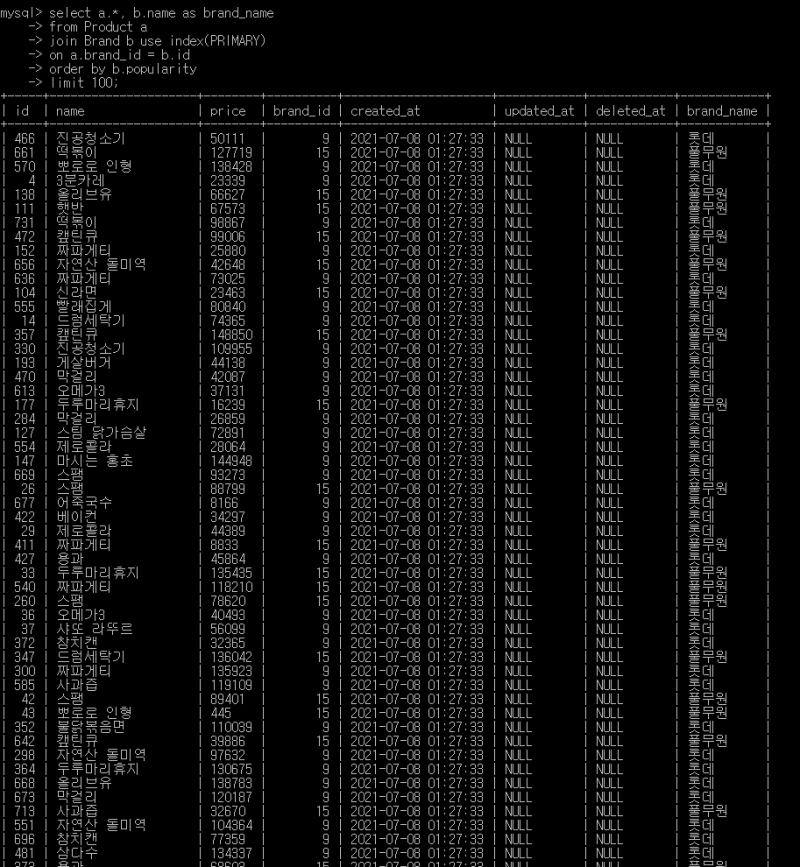
쿼리플랜 보기
쿼리플랜은 explain 키워드를 앞에다 붙이면 볼 수 있다.
실제로 쿼리가 어떤 방식으로 동작하고, 각각의 단계에서 비용이 얼마나 발생하는지를 알 수 있다.
explain
select a.*, b.name as brand_name
from Product a
join Brand b
on a.brand_id = b.id
join Something c
on a.id = c.product_id
order by c.value
limit 100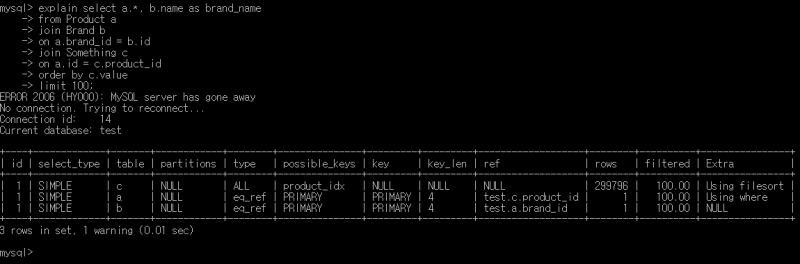 여기서의 플랜을 보면,
여기서의 플랜을 보면,
첫번째 항목은 Something이다. using filesort는 정렬을 한다는 것이고, rows를 보면 근 30만개나 가져온다.
이 쿼리에서는 정렬이 가장 비싼 동작이라서 먼저 Something을 긁어온 다음에 정렬하고, 베이스 테이블로 사용하는 것이다.
두번째 항목은 Product다. 사용된 키는 PRIMARY라고 되어있으니, Something의 product_id로 Product의 id를 인덱싱해온다.
세번째 항목은 Brand다. 마찬가지로 기본키로 인덱스가 잡혀있고, Product의 brand_id로 Brand의 id를 인덱싱해온다.
이 쿼리플랜 자체는 별다른 문제가 없다.
인덱스 힌트 (use index)
앞서 말했듯, MySQL의 옵티마이저는 좀 멍청해서 직접 인덱스를 집어줘야 하는 경우가 많다.
위의 경우에는 테이블 조인도 별로 없고, 인덱스도 별로 없어서 별 문제가 없었지만, 실 디비 작업을 하다보면 문제가 비 온 뒤의 대나무처럼 튀어나온다.
특히 인덱스가 많을수록 분간을 못하는 게 많은 것 같다.
예를 한번 들어보자. 아래 쿼리에서
select a.*, b.name as brand_name
from Product a
join Brand b
on a.brand_id = b.id
order by b.popularity
limit 100Brand의 조인은 Brand의 기본키인 id를 조건으로 한다.
그러니 당연히 기본키 인덱스를 잡는 것이 가장 빠르고, 효율적이다.
근데 이런 당연한걸 못잡을 때가 많다. 더 탐색률이 좋은 복합인덱스를 두고 구린 인덱스를 잡는다든지...
그럴 때는 다음과 같이 사용할 인덱스를 명시해줘야 한다.
select a.*, b.name as brand_name
from Product a
join Brand b use index(PRIMARY) -- Brand의 기본키를 사용하라
on a.brand_id = b.id
order by b.popularity
limit 100기본키는 다 PRIMARY로 쓰는데, 임의로 만든 인덱스면 그 인덱스 이름을 써주면 된다.
근데 USE INDEX는 기본적으로 '권장'을 하는 것이지 강제를 하는건 아니다.
강제로 인덱스를 고정해주고 싶다면 FORCE INDEX를 사용해야 한다.
select a.*, b.name as brand_name
from Product a
join Brand b force index(PRIMARY) -- Brand의 기본키를 사용하라 (강제)
on a.brand_id = b.id
order by b.popularity
limit 100쓸일이 잦지는 않지만 use index/force index 뒤에 추가로 힌트를 더 달아줄 수도 있다.
select a.*, b.name as brand_name
from Product a
join Brand b force index for join(PRIMARY) -- join용으로 인덱스를 잡아라
on a.brand_id = b.id
order by b.popularity
limit 100
select a.*, b.name as brand_name
from Product a
join Brand b force index for order by(PRIMARY) -- order by용으로 인덱스를 잡아라
on a.brand_id = b.id
order by b.popularity
limit 100
select a.*, b.name as brand_name
from Product a
join Brand b force index for group by(PRIMARY) -- group by용으로 인덱스를 잡아라
on a.brand_id = b.id
order by b.popularity
limit 100조인 순서 고정 (Straight_Join)
Straight_Join은 조인의 순서를 고정시키는 특수 키워드다.
원래 옵티마이저는 조인문을 받으면 그걸 그대로 돌리는게 아니라, 아까 위에서 봤듯이 최대한 빠르게 돌릴 수 있는 방향으로 조인 순서를 막 뒤섞는다.
그리고, 조인쿼리를 짜다보면 위의 Product 같은 베이스 테이블이 아니라 이후에 이어붙인 테이블의 컬럼으로 정렬조건을 사용할 일이 매우 잦다. 이럴 때는 인덱스만 있으면 알아서 최적화를 잡아줘야 하는데... 디비가 못해줄 때가 있다.
내가 그럴때 가끔 사용한 방법은
- 조인 순서를 바꾸지 못하게 고정시킨 다음에,
- 정렬조건으로 사용할 컬럼의 테이블을 먼저 select해서 정렬해오고,
- 그 정렬을 유지시키는 것이다.
보기 좋은 방법은 아니지만 이걸로 괜찮은 효과를 좀 봤다.
select straight_join a.*, b.name as brand_name
from
(
select *
from Brand
order by popularity /* 먼저 정렬해서 읽어오기 */
) b
join Product a
on a.brand_id = b.id
order by b.popularity
limit 100