[Elasticsearch] 검색어 오타 감지 (fuzzy)
엘라스틱서치의 검색 쿼리들은 기본적으로 오타에 대한 대응 기능이 활성화되어있지 않다.
그래서 정확히 일치하는 텍스트에 대해서는 잘 찾아주지만
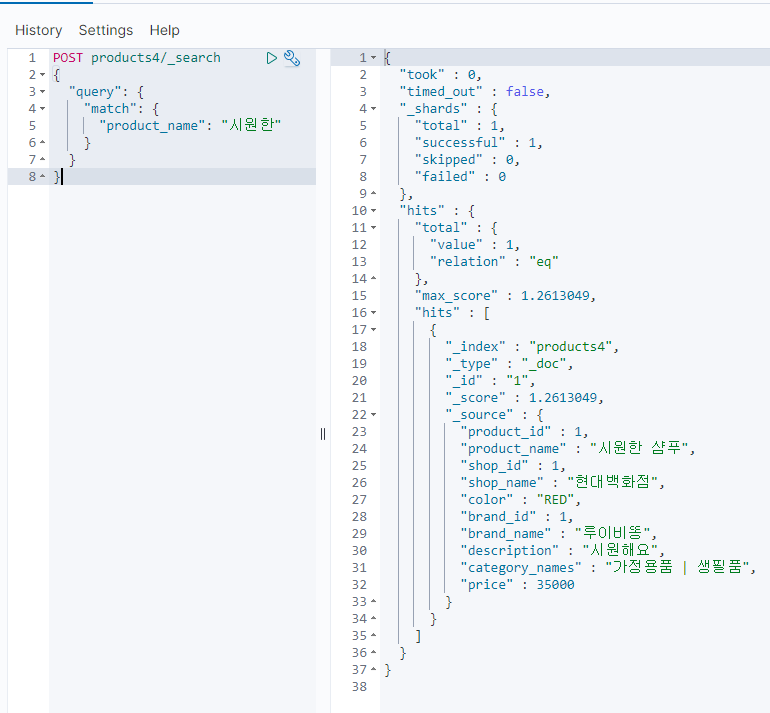
하나라도 틀리면 매칭이 되지 않는다.
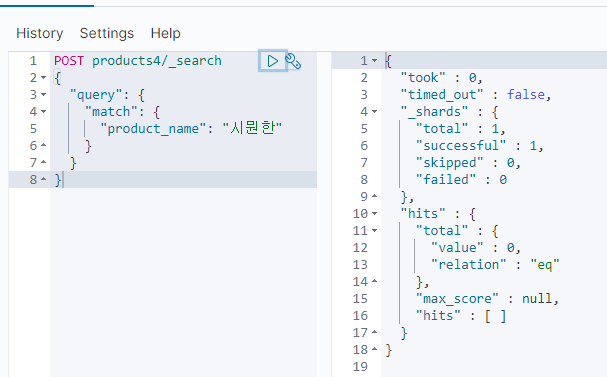
fuzzy 쿼리
이럴 때 사용할만한 것이 fuzzy 쿼리다.
이건 기본적으로 term과 유사하게 동작한다. match처럼 문장 단위의 검색은 불가능하더라.
아무튼, fuzzy는 오타를 감안한 검색을 가능케 해준다.
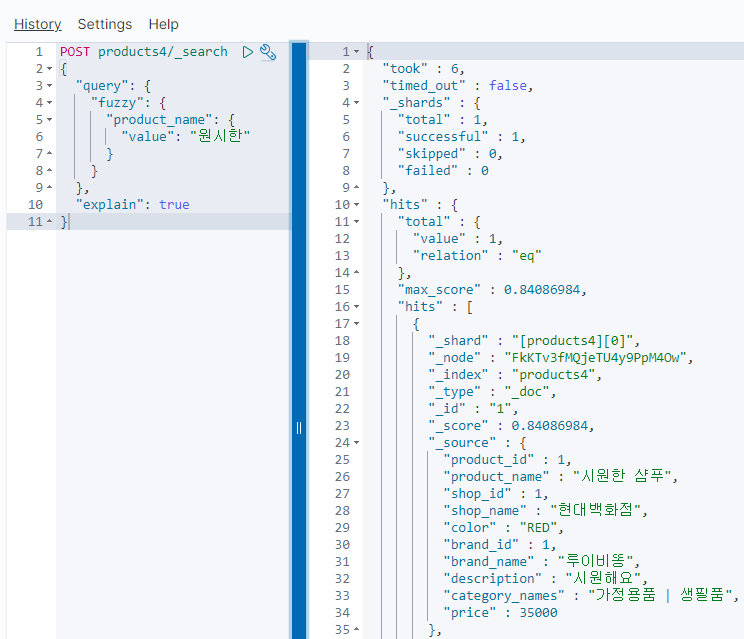
이걸 사용하면 이제 "시뭔한"이라 치더라도
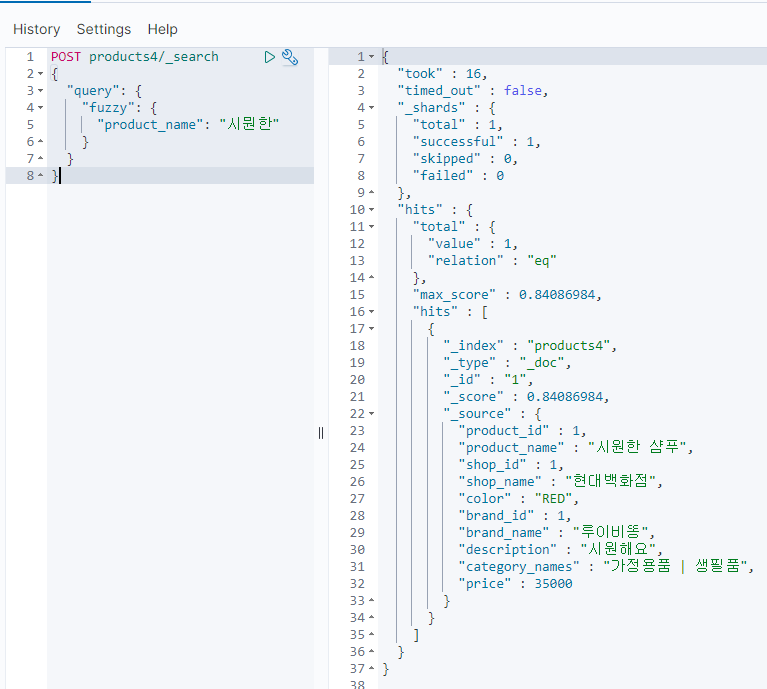 "시원한"이 충분히 검색된다.
"시원한"이 충분히 검색된다.
하지만 여기엔 단점이 좀 있는데,
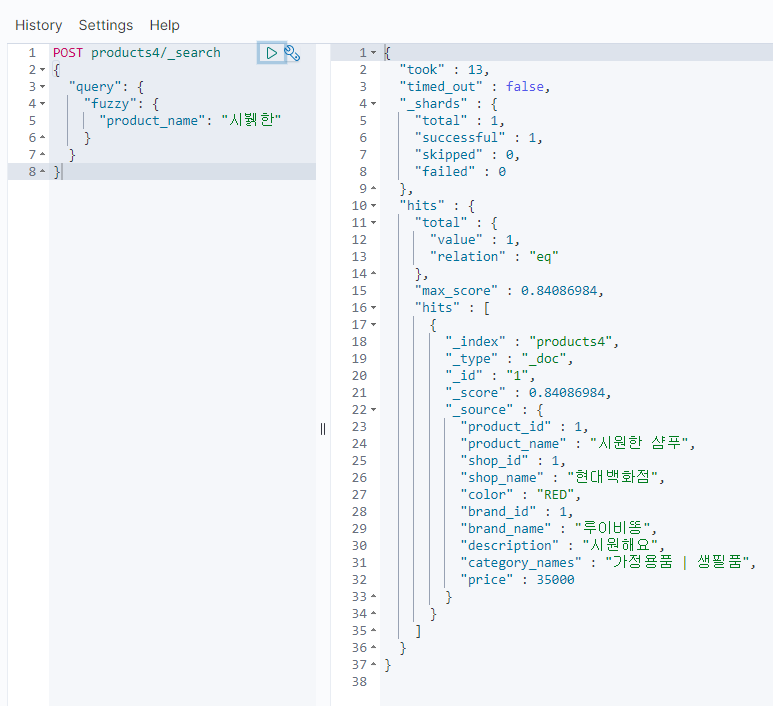 영어의 경우에는 한글자 한글자의 중요도가 한글보단 낮아서, 글자 하나 다른 정도는 충분히 오타로 칠 수가 있다.
영어의 경우에는 한글자 한글자의 중요도가 한글보단 낮아서, 글자 하나 다른 정도는 충분히 오타로 칠 수가 있다.
하지만 한글은 한글자 한글자의 중요도가 훨씬 높아서, 오타라고 생각할수 없는 경우도 오타로 감지되기가 매우 쉽다는 것이다.
엘라스틱서치의 fuzzy 기능은 한글의 자모까지 쪼개서 "뭔"과 "원"이 비슷한지를 보는게 아니라, 그냥 한글자 한글자 단위로만 본다. 그래서 "원"과 "뷁"도 같은 글자로 취급되고 마는 것이다.
그래서 한국어로 된 검색에는 적극적으로 추천하진 못하겠다. 부작용이 좀 있다.
오타 글자 개수
그리고 fuzziness라는 옵션값으로 오타 감지율을 조정할 수 있다. 다만 선택지는 "AUTO", 0, 1, 2밖에 없긴 하다.
AUTO는 그냥 자동으로 처리하는 디폴트값이고, 1는 한글자까지 오타로 감지, 2는 두글자까지 오타로 감지하는 것이다. 0은 처리를 안하고.

글자 순서 변경
단순 글자가 하나 바뀌는 것뿐만 아니라, 글자의 순서가 서로 바뀐 것도 오타로 감지할지 아닐지를 결정할 수 있다.
기본값은 감지하는 것이다.
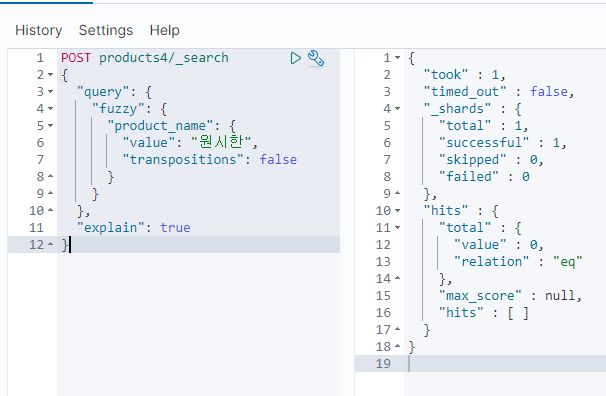
그래서 "원시한"으로 검색했을 경우에도 "시원한"이 검색이 된다.
 이게 왜 기본값인지 모르겠다.
이게 왜 기본값인지 모르겠다.
부작용이 좀 많은데
transpositions 값을 false로 해두면 끌 수 있다.
match 쿼리들
fuzzy 쿼리문은 term처럼 동작해서 텍스트 검색에 쓰기는 힘들다고 했었다.
그래서 match류의 기능들(match, multi_match...)에는 다 fuzzy에 대한 기능 옵션이 존재한다.
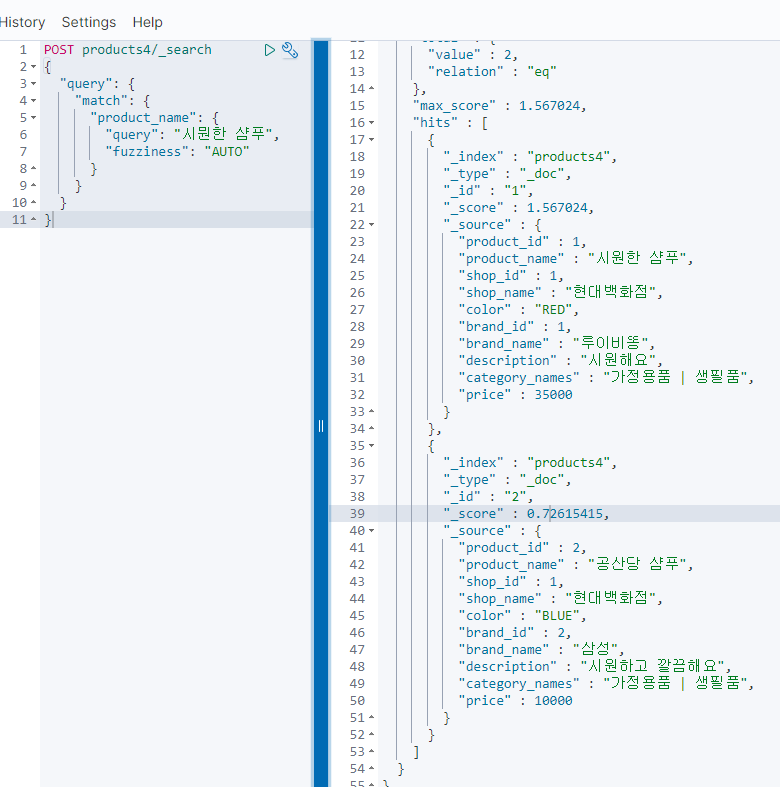 대충 이런식으로 써먹으면 된다.
대충 이런식으로 써먹으면 된다.
간단한 케이스들은 fuzzy로만 대처가 가능할 수 있지만, 정말 고품질의 오타교정 기능을 원한다면 따로 플러그인을 꽂거나 직접 구현하는 등의 노고가 필요할 것 같다.
참조
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html