[Elasticsearch] 형태소 분석기 Nori (with Elastic Cloud)
형태소 분석도 검색구현에 있어서 가장 중요한 것 중 하나다.
엘라스틱서치는 기본적으로 조건당 가중치를 붙이고, 빠르게 인덱싱을 해오는게 다지, 언어적인 수준에서의 분석기능은 제공하지 않기 때문이다.
그래서 띄어쓰기같은걸 매끄럽고 유연하게 처리하기 위해서는 언어에 맞는 형태소 분석기를 붙여줘야 한다.
형태소 분석기는 토크나이저로 구현되는데, 잘 모른다면 토크나이저와 analyze에 대해서도 알아두는 것이 좋다.
https://blog.naver.com/sssang97/222436348987
나는 여기서 Nori라는 분석기를 사용할 것이다. 이건 엘라스틱서치를 직접 구축하거나, Elastic Cloud를 사용할 때만 사용이 가능하다.
AWS의 Elasticsearch에서는 사용이 불가능하다. 그래서 AWS ES는 강력하게 비추천한다.
형태소 분석기 설치
먼저 Nori를 깔아주자.
프로젝트 관리페이지에 들어가서 Edit Deployment를 누른다.

그리고 저기서 세팅&플러그인을 누르면
이렇게 추가할 수 있는 플러그인 목록이 뜬다.
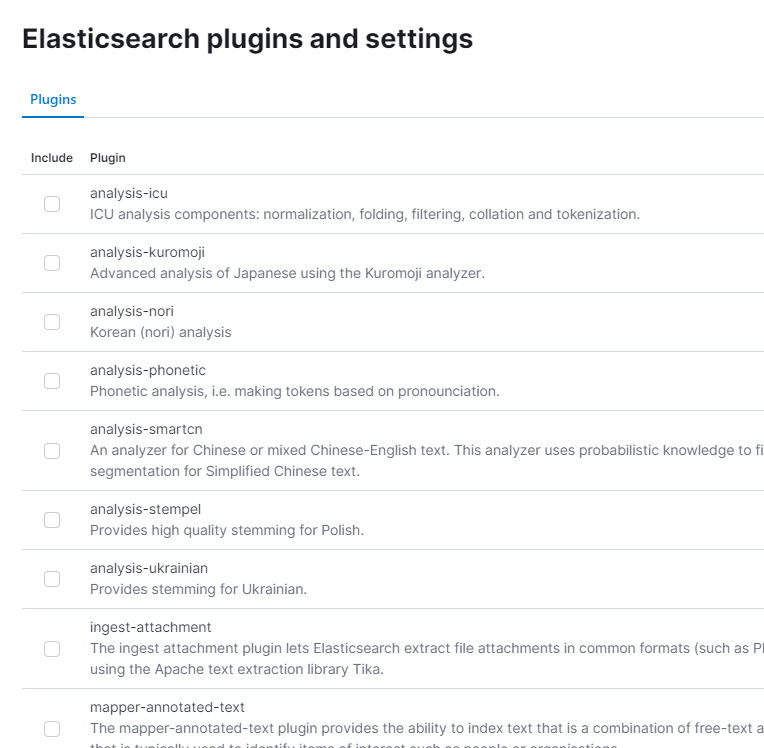 일본어도 있고 한국어도 있고, 우크라이나어도 있는데, 나는 당연히 nori를 선택했다.
일본어도 있고 한국어도 있고, 우크라이나어도 있는데, 나는 당연히 nori를 선택했다.
잘 고른다음에 저장하기만 하면 된다.
좀 걸린다.
설치가 잘 됐다면, 이제 nori_tokenizer라는 이름으로 nori를 갖다쓸 수 있을 것이다.
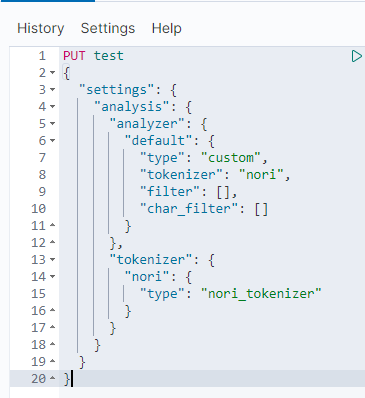 하나씩 테스트해보면서 대략적인 사용법을 소개해보겠다.
하나씩 테스트해보면서 대략적인 사용법을 소개해보겠다.
어근 전달 방식
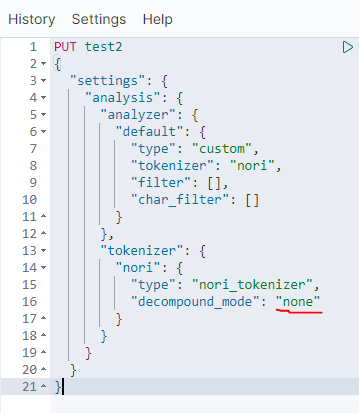
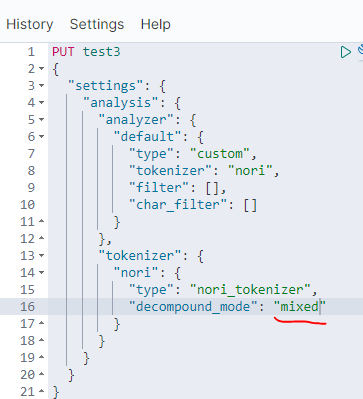
decompound_mode라는 옵션이 있는데, 이걸 사용하면 어근을 어떻게 잘라서 보낼지를 설정할 수 있다.
기본값은 discard고, 이건 전부 잘라서 보내는 것이다.
그래서 따로 설정을 하지 않으면 다음과 같은 문장이
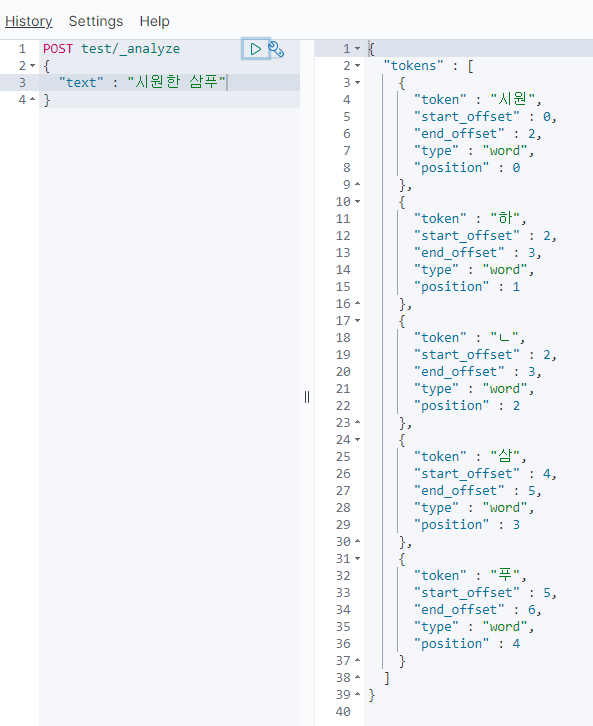 정말 어근단위로 토막나서 전달된다.
정말 어근단위로 토막나서 전달된다.
이런걸 바라지 않는다면 'none'으로 꺼둬야 한다.
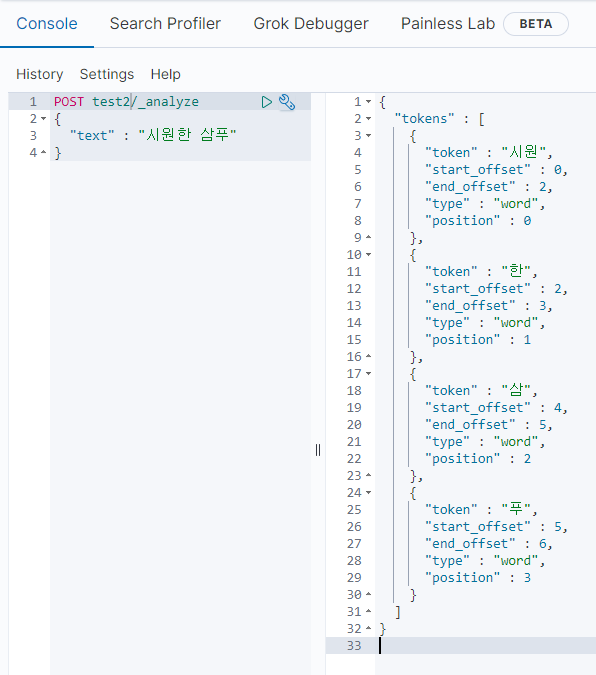
둘다 섞어서 받고 싶으면 mix로 주면 되고
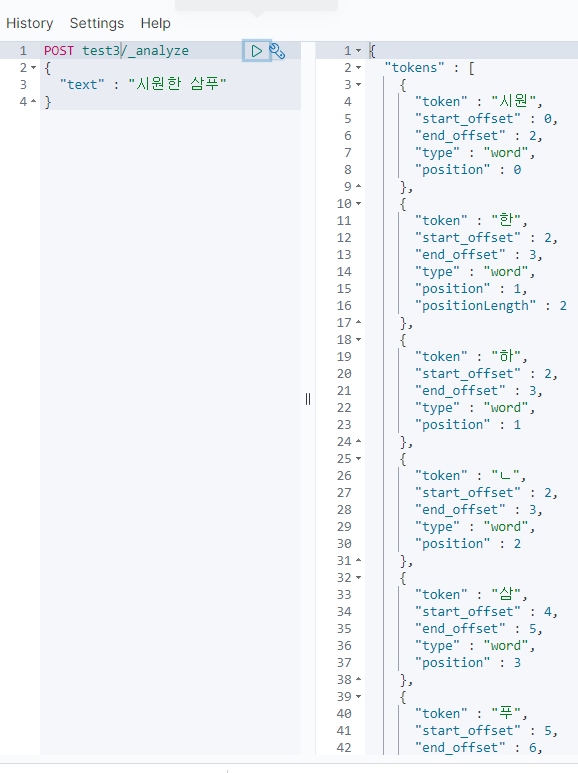
품사 제거
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori-speech.html
nori는 품사 단위로 단어를 전부 빼버릴지 말지를 정의할 수 있다.
stoptags로 사용하지 않을 품사명을 적어주면 그건 토큰 리스트에서 다 빼버린다.
품사 리스트는 아래 링크에서 확인할 수 있다.
http://kkma.snu.ac.kr/documents/?doc=postag
조금 싱크가 안맞고 없는게 있긴 한데.. 공식문서에서 제공하는게 저거밖에 없다.
그리고 stoptags의 기본값은 다음과 같다고 한다.
"stoptags": [
"E", "IC", "J", "MAG", "MAJ",
"MM", "SP", "SSC", "SSO", "SC",
"SE", "XPN", "XSA", "XSN", "XSV",
"UNA", "NA", "VSV"
]그리고 어떤 단어가 어떤 품사인지 쉽게 체크하려면 explain 옵션을 켜고 보면 좋다.
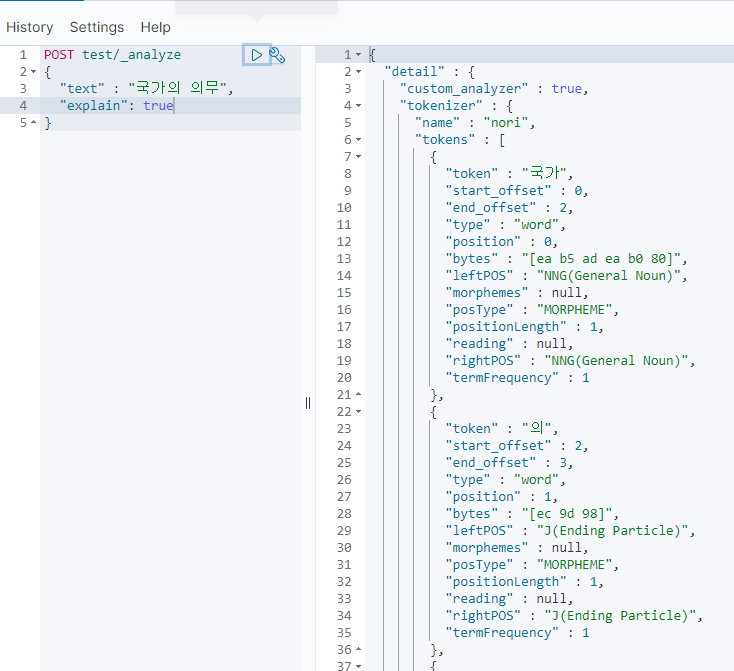
사용자 사전
검색엔진을 구축하는 데 있어서 가장 중요한 것 중 하나가 또 사전을 구축하는 것이다.
기본 사전에도 어지간한게 다 들어있긴 하지만, 그래도 모든 케이스를 처리할 정도로 충분한 것은 아니기 때문이다.
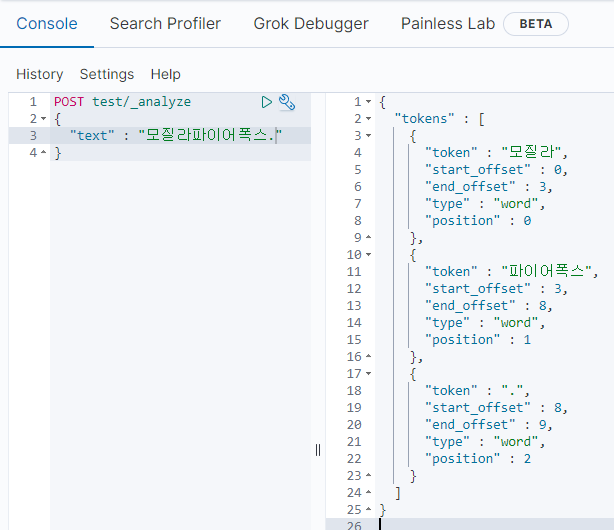
그래서 다음과 같이 "모질라파이어폭스"를 치면 "모질라"와 "파이어폭스"로 구분되기를 기대하지만
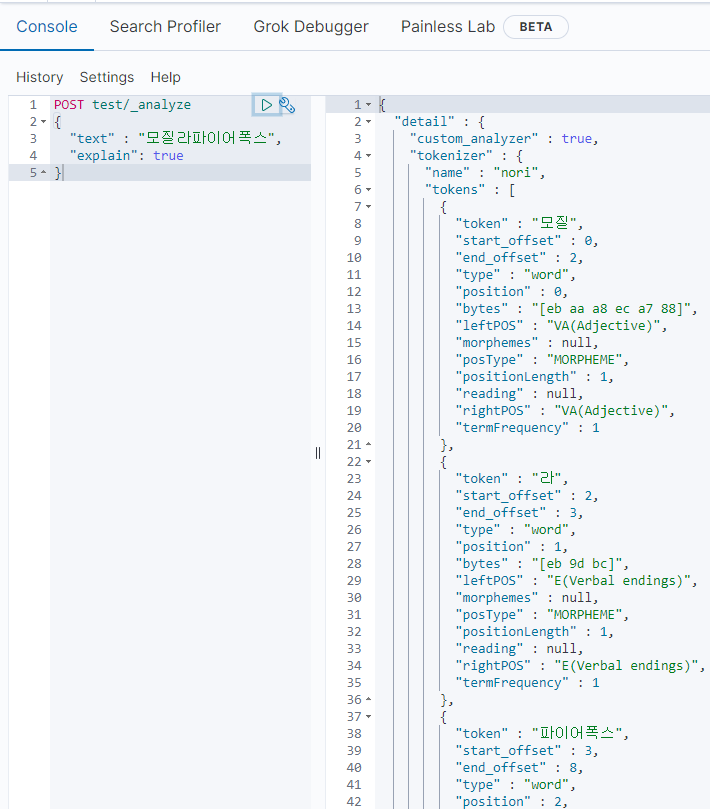 nori는 모질라를 알지 못한다.
nori는 모질라를 알지 못한다.
그래서 이런 케이스들은 사용자 사전에 정리해서 넣어주는 작업을 해야 한다.
이거는 뭐 쉽고 빠른 방법은 없고, 전부 100% 쌩 노가다다.
본인에게 필요한 상황에 맞춰서 단어들을 충분히 수집해서 넣어줘야 한다.
데이터 기반으로 긁어와서 정리해도 되고.
이게 손이 생각보다 엄청 많이 가는 작업이라서, 이것만 따로 외주를 주기도 한다고 한다.
아무튼 일단 우리는 가볍게 테스트만 하는 정도니, 가볍게만 훑어보고 지나가도록 하자.
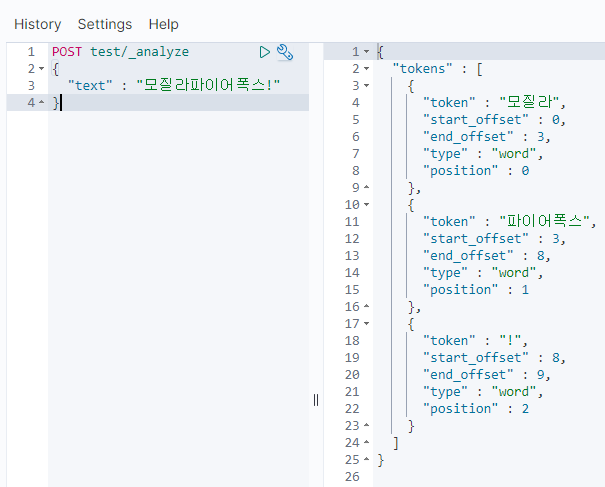
다음과 같이 사용자 단어를 추가하면
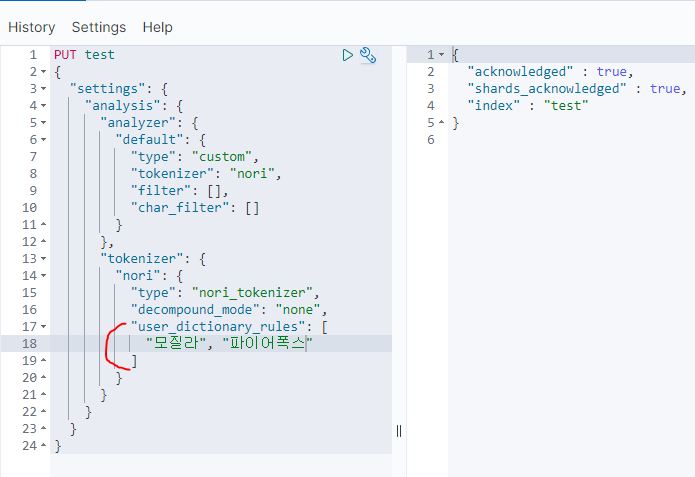
기대한대로 잘 동작한다.
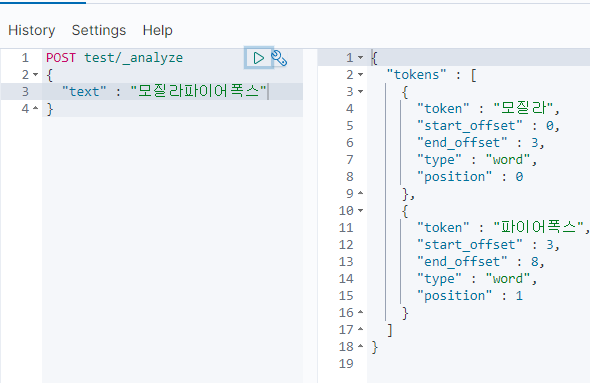
위에서는 user_dictionary_rules로 간단하게 처리했지만, 당연히 수천수만개가 넘는 단어를 저렇게 보낼 수는 없고, 보통 텍스트파일을 업로드해서 user_dictionary로 경로를 지정한다.
 사용자사전 파일은 개행으로 구분된 텍스트기만 하면 된다.
사용자사전 파일은 개행으로 구분된 텍스트기만 하면 된다.
문장부호 필터링
discard_punctuation 옵션을 사용하면 문장부호를 뺄지 말지를 지정할 수 있다.
true면 빼버리는건데, 기본값이 true다.
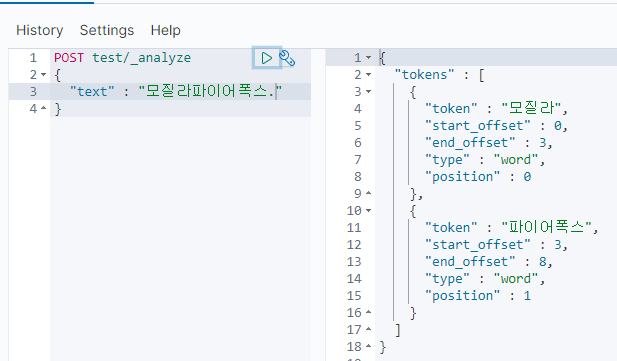
false로 하면
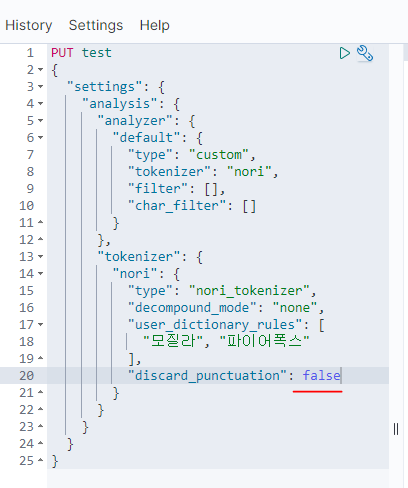
필터링되지 않을 것이다.
참조
https://www.elastic.co/guide/en/cloud-enterprise/current/ece-add-plugins.html
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori-tokenizer.html