[AWS] RDS: 복제본 만들기 (Aurora)
본 포스트에서는 AWS RDS Aurora에서 복제본을 만들고 사용하는 법을 간단히 다뤄본다.
개발과 시스템의 운영을 동시에 하다보면, 개발환경과 서비스환경의 분리가 중요해진다.
개발환경에서는 당연히 이런저런 시도나 변경사항들이 빈번하게 일어나는 법인데, 이런 일들은 당연히 서비스의 입장에서는 위험천만한 일들이기 때문이다.
다행스럽게도 RDS Aurora는 이런 상황을 위해서 이런저런 편리한 기능들을 잘 갖춰놓은 편이다.
다만 Aurora가 아닌 일반 RDS는 이런 기능이 따로 없어서 좀 번잡한 절차를 걸쳐야 한다. S3에 스냅샷을 뽑고, 그 스냅샷으로 다시 RDS를 만들어주고...
그래서 가급적이면 오로라를 쓰는 것을 권장한다.
테스트 환경은 Aurora MySQL이나, PostgreSQL도 사용법은 별 차이가 없다.
 일단 메인 DB를 하나 만들어주겠다.
일단 메인 DB를 하나 만들어주겠다.
내 돈은 소중하기 때문에 가장 낮은 t2.small로 인스턴스를 생성했다.
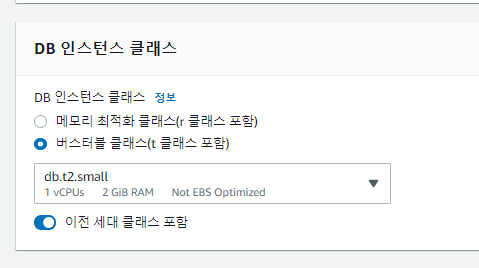
그리고 아래와 같이 간단한 테이블 하나와 데이터를 좀 넣어줬다.
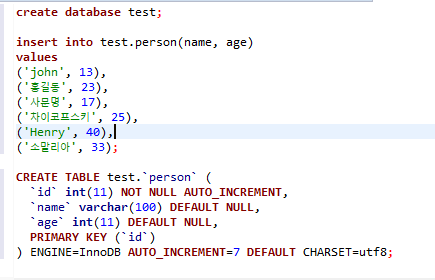
create database test;
insert into test.person(name, age)
values
('john', 13),
('홍길동', 23),
('사문명', 17),
('차이코프스키', 25),
('Henry', 40),
('소말리아', 33);
CREATE TABLE test.`person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;복제본 생성
그럼 이제 저 DB에 대한 개발&테스트용 복제본을 만들어보자.
복제할 DB를 선택하고 복제본 생성을 누른다.

그럼 다음과 같이 데이터베이스 생성창이 뜨는데
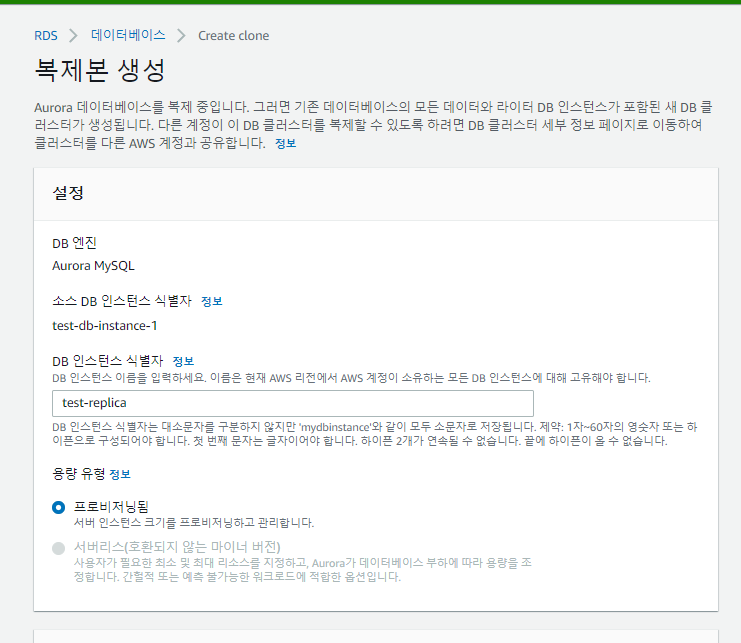 그냥 DB를 만들때와 옵션이 거의 동일하다.
그냥 DB를 만들때와 옵션이 거의 동일하다.
필요한대로 맞춰주고 생성한다.
그럼 아래와 같이 인스턴스가 새로 만들어질 것이다.
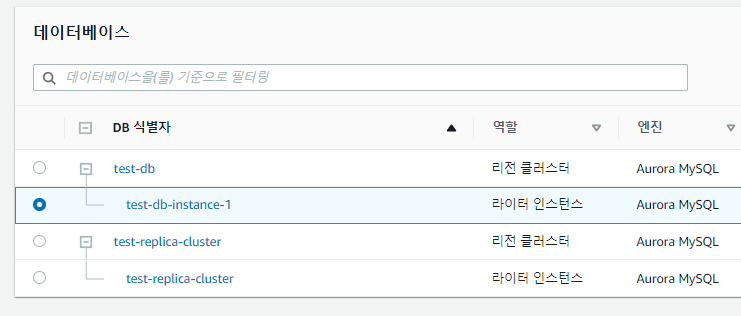
열어서 안을 들여다보면
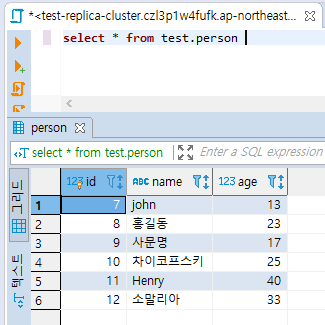 원본의 데이터가 그대로 옮겨져있다.
원본의 데이터가 그대로 옮겨져있다.
그리고 이 복제본은 복제를 한 시점에서 원본과 격리되어있기 때문에, 뭘 쓰더라도 그게 원본에 영향을 주지는 않는다.
복제에 데이터를 넣고
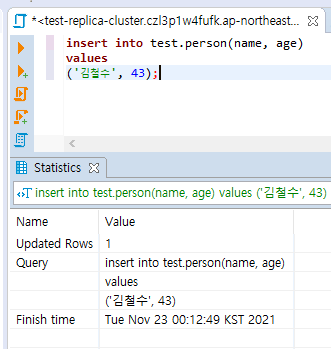
원본을 보더라도, 그게 동기화되어있지는 않을 것이다.
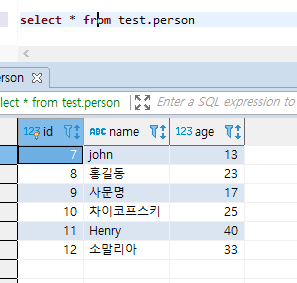 반대도 마찬가지다.
반대도 마찬가지다.
참조
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html