[Elasticsearch] 클러스터 구성
이런 종류의 DB 시스템들을 사용하다보면 반드시 필요한 것 중 하나가 클러스터링이다.
클러스터링은 간단히 말해 머신을 병렬로 연결하는 것이다.
스펙을 올릴때 무조건 머신을 좋은걸로만 바꿀 수는 없으니, 비슷한 성능의 머신을 여러개 구해서 "스케일 아웃"을 수행하는 것이라 할 수 있다.
그리고 Elasticsearch는 클러스터링이 손쉽고, 잘 지원되는 편이다.
Elasticsearch의 클러스터는 다음과 같은 구조를 가진다.
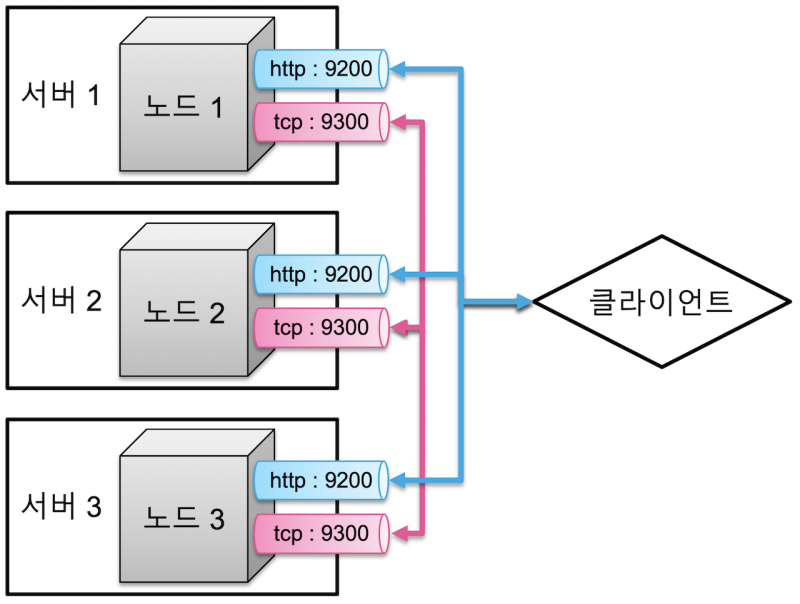 별로 특별할 것은 없다.
별로 특별할 것은 없다.
외부 api는 9200포트로 받고, 자기들끼리의 동기화 등은 tcp 소켓 9300포트로 주고받는다.
클러스터 설정하기
기존의 설정파일을 열어서 클러스터명과 노드명을 지정해준다.
sudo vi /etc/elasticsearch/elasticsearch.yml클러스터링을 위해 추가할 옵션은 대략 다음과 같다.
cluster.name: test_cluster # 클러스터명
node.name: master_node # 현재 노드명
node.master: true # 마스터 노드로 사용할 것인지
node.data: true # 데이터 노드로 사용할 것인지
discovery.seed_hosts: ["34.64.75.172"] # 마스터 노드 후보 주소 (현재 주소)
cluster.initial_master_nodes: ["master_node"] # 마스터 노드 후보클러스터명은 반드시 같아야 하고, 노드명은 반드시 다 달라야 한다.
그리고 마스터 노드를 반드시 하나 이상은 지정해줘야 한다.
그리고 재실행한다.
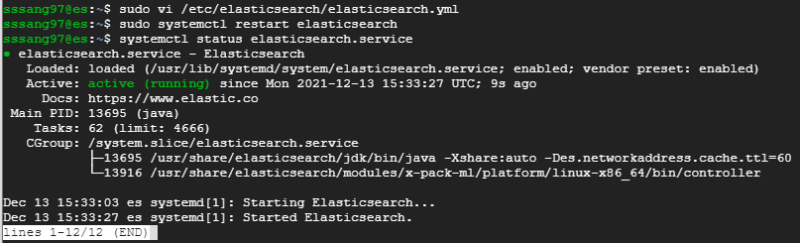
이번엔 데이터 노드를 하나 추가해보자.
컴퓨터 환경을 추가로 하나 마련하고, 이전과 같이 elasticsearch를 설치 구성했다.
대충 아래와 같이 사용할 수 있다.
cluster.name: test_cluster # 클러스터명
node.name: node-1 # 현재 노드명
node.master: false # 마스터 노드로 사용할 것인지
node.data: true # 데이터 노드로 사용할 것인지
discovery.seed_hosts: ["34.64.75.172"] # 마스터 노드 후보 주소
cluster.initial_master_nodes: ["master_node"] # 마스터 노드 후보별로 다를 것은 없다.
이렇게 해서 똑같이 실행시키고, 별다른 오류가 발생하지 않는다면, 잘 올라간 것이다.
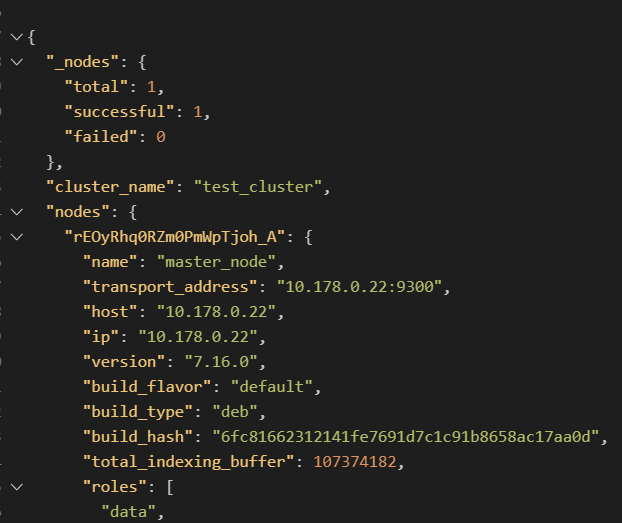
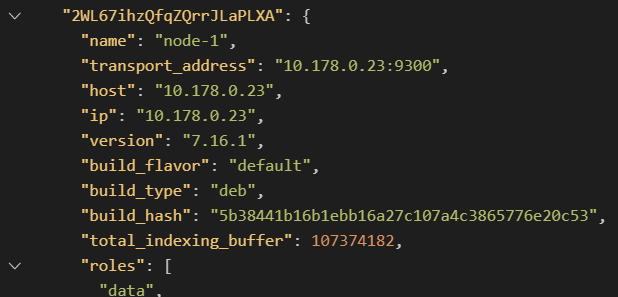
마스터 노드와 데이터 노드
다시 정리해보자면, 마스터 노드는 말 그대로 전반적인 관리를 담당하는 노드를 말한다.
클러스터에는 반드시 하나의 마스터 노드가 있어야 하고, 마스터 노드는 클러스터에 대한 관리와 작업 분할 등을 총괄한다.
그래서 노드가 2개 이상 있다면, 마스터 노드는 관리만을 담당하고 실제 데이터의 저장 등은 기타 데이터 노드에서만 처리하게 된다.
그리고 만약 마스터 노드가 죽더라도 다른 마스터 노드 후보가 있다면, 그 자리를 물려받게 된다.
이런저런 이유 때문에 마스터 노드 후보는 최소 3개 이상, 홀수개로 사용하는 것이 권장된다.
근데 그렇다고 마스터 노드 후보가 무조건 많은 것도 좋지는 않다. 마스터노드 후보가 있으면 마스터노드가 정보를 후보들과 항상 공유해야 하기 때문이다.
참조
https://esbook.kimjmin.net/03-cluster/3.1-cluster-settings
https://blog.naver.com/PostView.naver?blogId=theswice&logNo=222198334587&parentCategoryNo=&categoryNo=66&viewDate=&isShowPopularPosts=false&from=postView
https://esbook.kimjmin.net/03-cluster/3.3-master-and-data-nodes