[Kafka] 기본 사용법
일단 구조부터 짚고 넘어가자.
카프카는 메세지 브로커(broker)라고 말하는데, 말 그대로 중개자를 뜻한다.
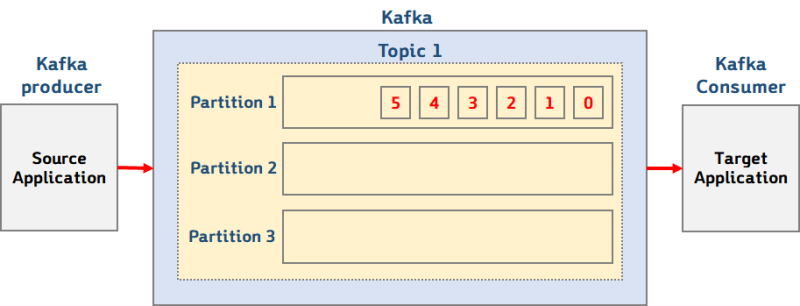
카프카 브로커는 다음과 같이 하나 이상의 토픽을 가지고, 토픽을 통해서 메세지의 입력과 출력을 중개한다.
 출처 https://cobajiyoung.tistory.com/68
출처 https://cobajiyoung.tistory.com/68
하나의 토픽은 하나 이상의 파티션으로 분할되어 보다 효율적인 분산처리를 가능케 할 수 있다.
저 그림에서 프로듀서와 컨슈머는 카프카와 별개의 소스 프로그램으로 작성할 수 있다.
토픽부터 만들어보자.
토픽 생성
먼저 토픽을 하나 생성해주도록 하겠다.
다음 셸코드를 실행하면 된다.
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic 토픽명 --create --partitions 3 --replication-factor 1
topic 목록은 --list 옵션으로 확인할 수 있다.
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
콘솔로 메세지 주고받기
미리 제공된 셸코드들을 사용하면 프로그램 작성 없이도 프로듀서와 컨슈머를 테스트용으로 사용해볼 수 있다.
프로듀서는 이렇게
./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test_topic
컨슈머는 이렇게 켤 수 있다.
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic
그럼 프로듀서에서 한줄을 입력할때마다
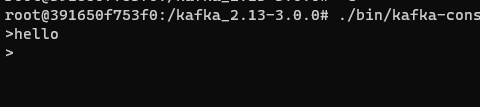
컨슈머에서 그것을 확인할 수 있을 것이다.

프로듀서 작성
언어는 node.js를 사용하겠다.
다른걸 사용해도 큰 차이는 없을 것이다.
카프카용 클라이언트 모듈을 다운받는다.
 다운수가 비슷한걸로 kafka-node가 있는데, 이게 그것보다는 업데이트가 최근이라 이걸 골랐다.
다운수가 비슷한걸로 kafka-node가 있는데, 이게 그것보다는 업데이트가 최근이라 이걸 골랐다.
코드는 다음과 같이 작성할 수 있다.
const { Kafka } = require("kafkajs");
async function main() {
const kafka = new Kafka({
clientId: "test-producer",
brokers: ["localhost:9092"],
});
const producer = kafka.producer();
// 접속
await producer.connect();
// 메세지 전송
await producer.send({
topic: "test_topic",
messages: [
{ value: JSON.stringify({ user_id: 1, message: "안녕하세요" }) },
],
});
// 메세지 전송
await producer.send({
topic: "test_topic",
messages: [{ value: JSON.stringify({ user_id: 2, message: "foobar" }) }],
});
}
main();생성할 때 사용하는 clientId는 누가 메세지를 주고, 누가 받았는지를 식별하기 위한 값이다. 특별한 제약조건은 없다.
그리고 전송할 때는 전송할 토픽과 값을 지정해서 보내면 되는데, value 값에 문자열이나 버퍼 형태로 넣어주면 된다. 보통은 JSON으로 직렬화해서 문자열을 보내는 것이 편리할 것이다.
 전송하면 이렇게 간다.
전송하면 이렇게 간다.
컨슈머 작성
이번에는 컨슈머를 작성해보자.
const { Kafka } = require("kafkajs");
async function main() {
const kafka = new Kafka({
clientId: "test-consumer",
brokers: ["localhost:9092"],
});
const consumer = kafka.consumer({ groupId: "test-group" });
// 접속
await consumer.connect();
// 구독
await consumer.subscribe({ topic: "test_topic", fromBeginning: false });
// 실행
await consumer.run({
// 메세지가 들어올 때마다 호출됨
eachMessage: async ({ topic, partition, message }) => {
console.log(`# topic ${topic}, partition ${partition}`);
console.log({
value: message.value.toString(),
});
},
});
}
main();프로듀서와는 다르게 groupId라는 것을 받는다.
이건 부하 분산의 측면에서 존재하는 옵션이라고 할 수 있다. 하나의 groupId는 토픽의 파티션에서 데이터를 처리할 책임을 공유한다.
예를 들어 파티션이 10개 있고, 같은 그룹ID를 가진 컨슈머가 2개 있다면, 그 컨슈머는 각각 파티션을 5개씩 맡아서 처리할 것이다.
반대로 파티션이 10개 있고, 다른 그룹 ID를 가진 컨슈머가 하나씩 해서 총 2개 있다면, 그 컨슈머들은 각각 파티션을 10개 전체를 다 맡아서 따로따로 처리할 것이다.
그리고 구독할때 fromBeginning이란 옵션이 있는데, 이걸 true로 주면 컨슈머가 시작된 시점에서 들어온 메세지만 받을 것이다.
반대로 false를 주면 컨슈머가 시작되기 전부터 쌓여있던 메세지들을 읽어온다.
메세지를 받아올 때는 eachMessage에 콜백을 줘서 처리한다.
topic이 여러개 있다면 그걸로 분기를 주면 될 것이다.
저대로 실행시킨다면, 이런식으로 값을 받아올 것이다.
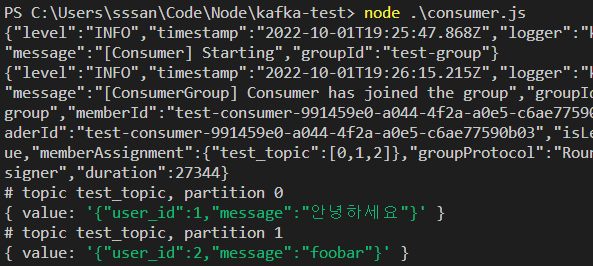 근데 여기서 좀 흥미로운 점이 있는데, 컨슈머가 켜져있는 상태에서 받는 메세지는 FIFO로 받지만
근데 여기서 좀 흥미로운 점이 있는데, 컨슈머가 켜져있는 상태에서 받는 메세지는 FIFO로 받지만
꺼져있던 상태에서 fromBeginning: false로 실행했을때 들어오는 메세지는 LIFO로 들어온다는 것이다.
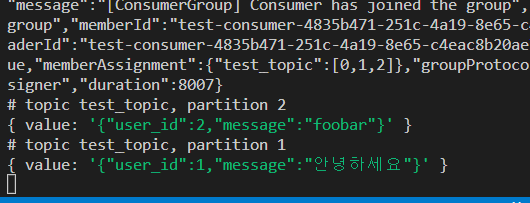 이건 좀 주의해야할 부분인 것 같다.
이건 좀 주의해야할 부분인 것 같다.
물론 이것도 새로 들어오는 메세지들은 FIFO로 들어온다.
참조
https://dorumugs.tistory.com/entry/Kafka%EC%9D%98-%EC%9D%B4%ED%95%B4%EC%99%80-%EC%84%A4%EC%B9%98-%EA%B7%B8%EB%A6%AC%EA%B3%A0-%EC%82%AC%EC%9A%A9%EB%B2%95
https://cobajiyoung.tistory.com/68