[Clickhouse] Clickhouse Cloud로 시작해보기
 클릭하우스는 OLAP 전용 데이터베이스 시스템 서비스다. 2016년에 나왔다.
클릭하우스는 OLAP 전용 데이터베이스 시스템 서비스다. 2016년에 나왔다.
오픈소스라서 직접 깔아다 쓸 수도 있고, 오픈소스그룹에서 관리하는 managed 서비스를 쓸 수도 있다.
여기서는 서비스를 쓰겠다.
보통의 상용 RDB들은 OLTP에 최적화되어있어서, 복잡한 OLAP 쿼리들은 느릴 뿐더러 메인서비스에 과부하까지 줄 수가 있다. 그래서 여러가지 OLAP를 수행할 필요가 있을 때는 데이터만 복사해서 좀더 전문적인 DB에 넣고 돌리곤 하는데, 이게 딱 그걸 위한 서비스다.
row-base인 일반 RDB와 다르게 column-base의 구조를 갖고 있고, MergeTree라는 구조로 인덱스를 관리한다.
페타바이급의 데이터도 1초 안에 처리하는데 성공했다고 한다..
같은 포지션의 다른 메이저 서비스로는, GCP BigQuery, AWS RedShift 등이 있다.
벤치마크 좀 찾아보니까 빅클라우드 기술들에도 꿇리지 않는 것 같다.
비용
서버리스 시스템이라서 딱 쓰는만큼만 비용을 뜯어간다.
비용은 리전마다 다르고, 스토리지와 컴퓨팅 2가지 방식으로 뜯는다.
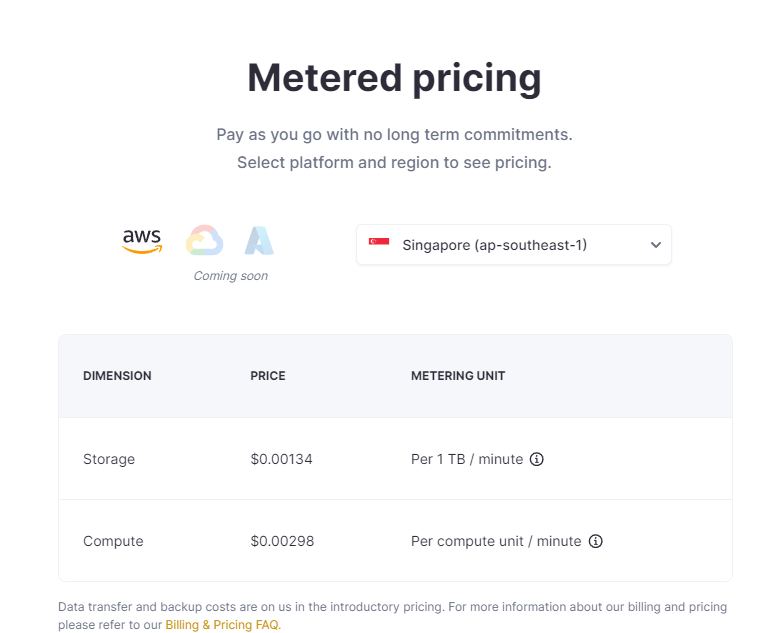 여기서 볼 수 있다.
여기서 볼 수 있다.
https://clickhouse.com/pricing#resource-billing
추정치를 제공해주기로는, 최소한 달에 300달러 정도는 생각해줘야 하지 싶다.
 https://clickhouse.com/docs/en/manage/billing/
https://clickhouse.com/docs/en/manage/billing/
처음 가입하면 2주동안 쓸 수 있는 테스트용 크레딧을 300달러쯤 준다.
시작해보기
가입하면 어느 리전에 깔 것인지를 먼저 물어볼 것이다.
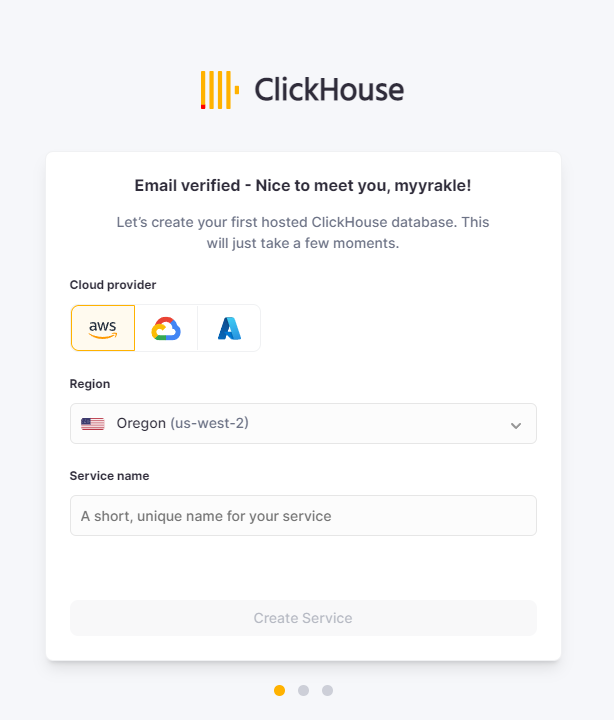 AWS외에도 GCP와 Azure 아이콘도 있는데, 저 둘은 지원예정이고 지금은 안된다. AWS만 가능하다.
AWS외에도 GCP와 Azure 아이콘도 있는데, 저 둘은 지원예정이고 지금은 안된다. AWS만 가능하다.
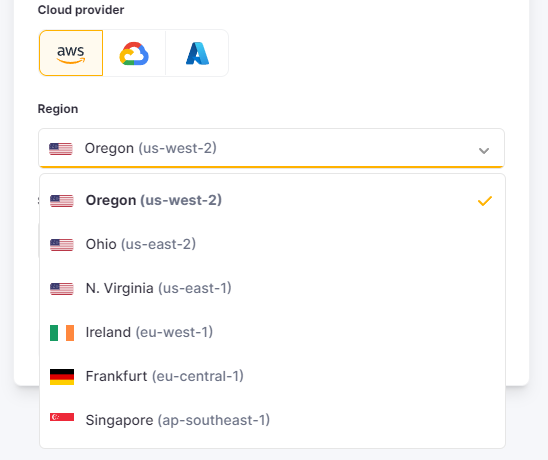 게다가 리전도 좀 부족하다...
게다가 리전도 좀 부족하다...
한국에서는 싱가포르가 그나마 빠르지 않을까 싶다.
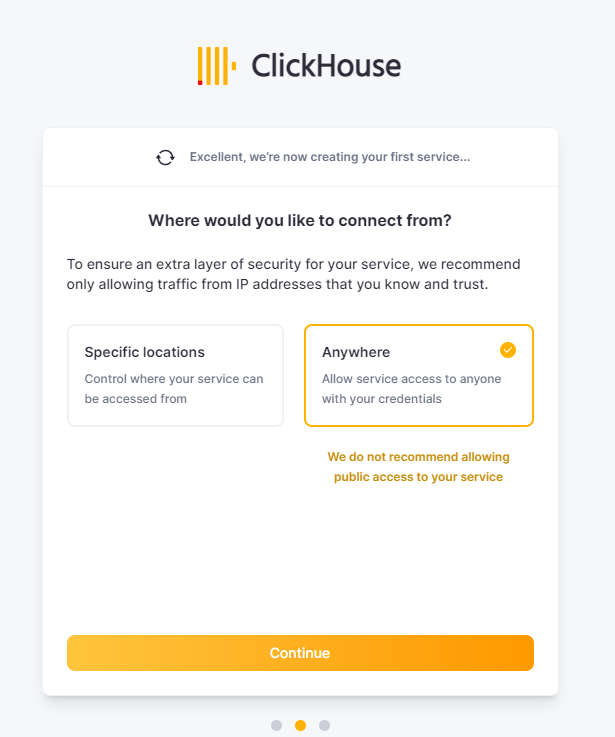 아이피 접근 어떻게 할것인지를 묻는데, 나는 그냥 anywhere로 다 열겠다.
아이피 접근 어떻게 할것인지를 묻는데, 나는 그냥 anywhere로 다 열겠다.
 그럼 비밀번호 한번 알려주고
그럼 비밀번호 한번 알려주고
대시보드에 들어가질 것이다.
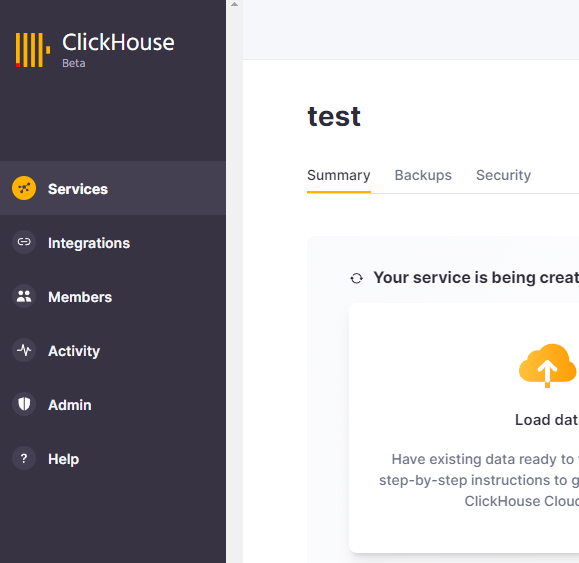
콘솔 접속하기
클릭하우스는 전용 클라이언트를 제공하는데, 그냥 웹콘솔을 쓸 수도 있다.
들어갈 인스턴스에 connect 누르고
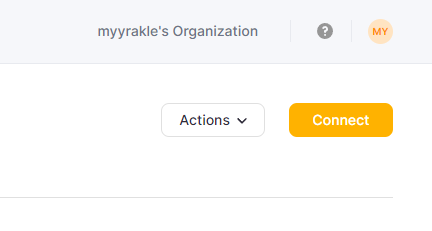
밑에 connect to SQL console을 누른다.
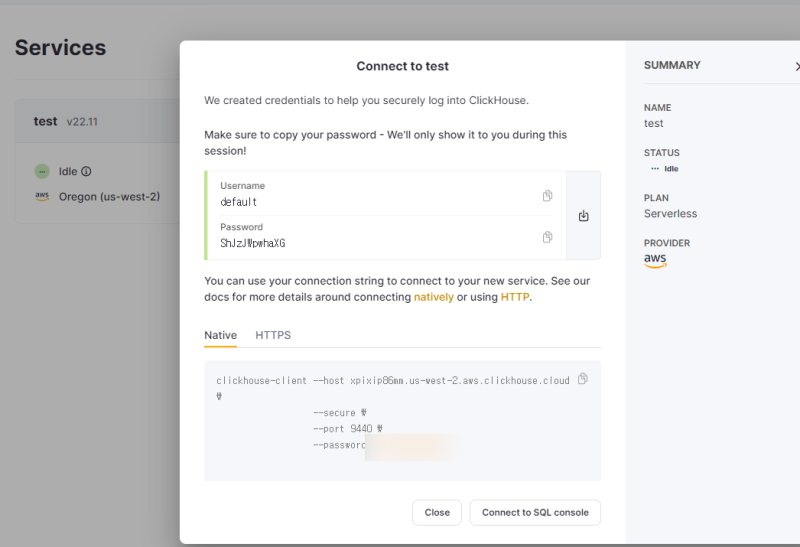
그럼 이런식으로 창이 뜰 것인데,
 우상단에 패스워드 쳐주고
우상단에 패스워드 쳐주고
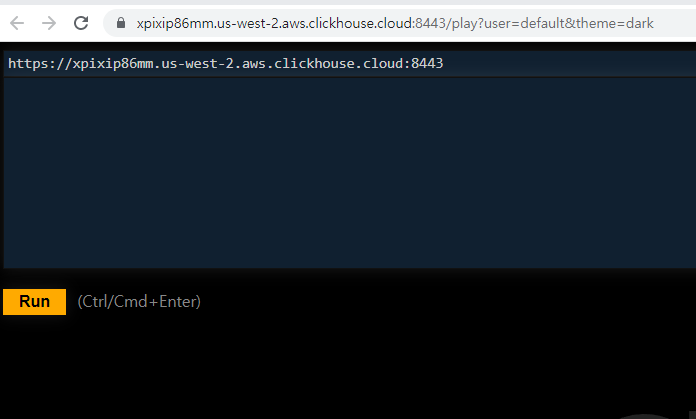
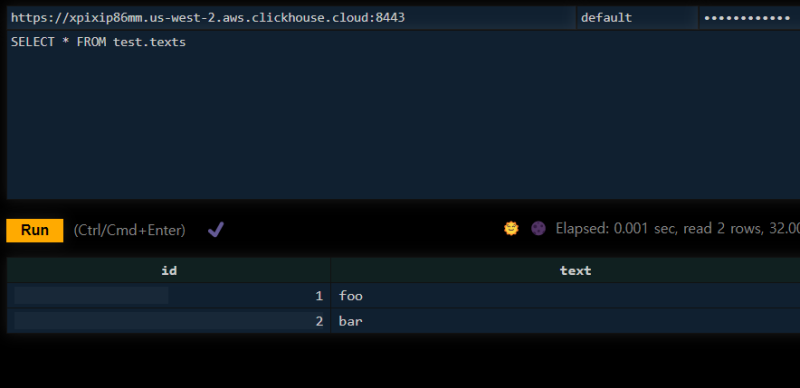
쿼리를 작성해준다음에
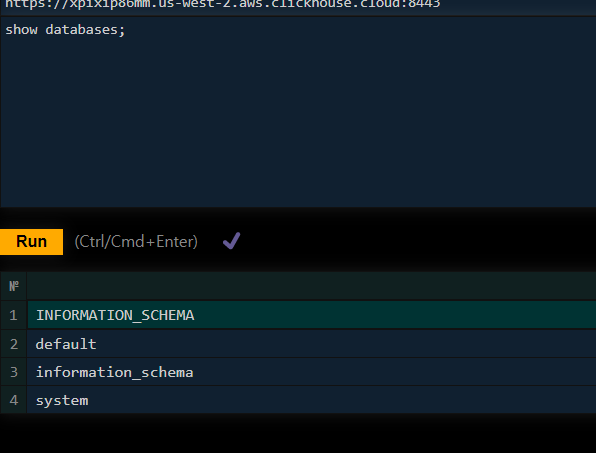 Run 버튼을 누르면 결과를 확인할 수 있다.
Run 버튼을 누르면 결과를 확인할 수 있다.
신택스
clickhouse는 친숙한 SQL 스타일의 쿼리 신택스를 제공한다.
타입같은게 좀 다르긴 한데, 크게 다르지는 않다.
DB 만들고
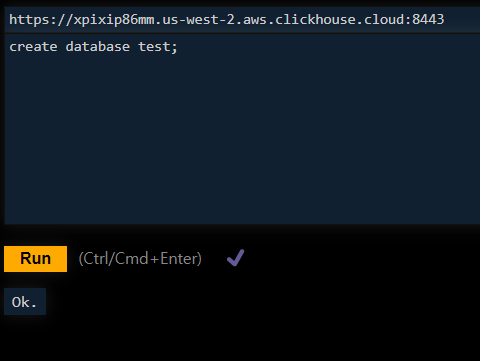
테이블 만들고
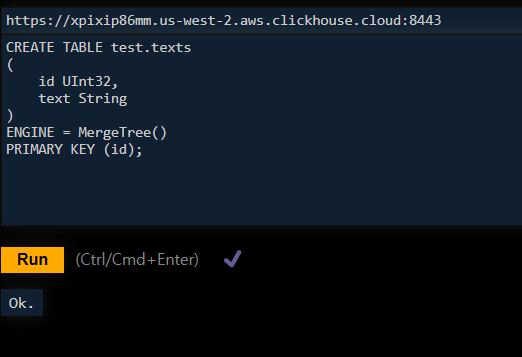
삽입하고
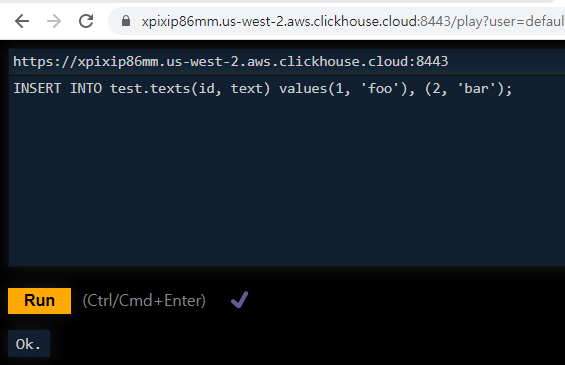
조회하면서 쓰면 된다.
빅데이터 다뤄보기
clickhouse 튜토리얼 가이드에서 제공하는 데이터를 활용해서 간단한 성능테스트를 좀 해보겠다.
우선 테이블 하나 만들고
CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime;
샘플데이터를 때려박아준다.
클릭하우스는 S3 기반의 데이터를 읽어서 넣어주는 기능을 제공한다.
INSERT INTO trips
SELECT * FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{1..2}.gz',
'TabSeparatedWithNames', "
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
") SETTINGS input_format_try_infer_datetimes = 0이러면 샘플데이터를 잘 넣어줄 텐데, 150MB짜리라서 조금 걸릴 수도 있다.
다 들어갔다면 조회가 가능할 것이다. 삽입은 느리지만 조회는 매우 빠르다.
400만개 정도가 들어있는데도
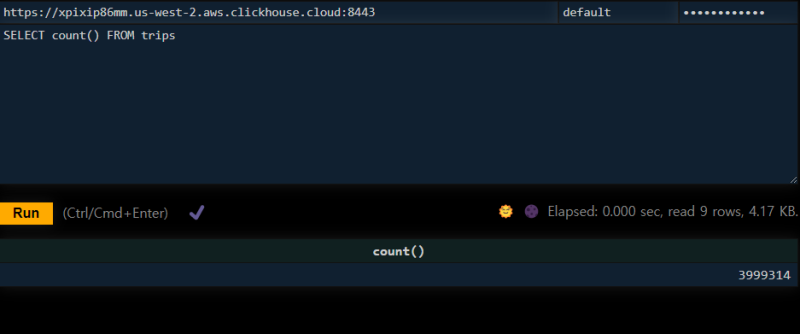
이런 일반적으로 느린 쿼리도 1초 미만에 수행이 되고
이런 헤비한 쿼리도 매우 빠르게 실행한다.
SELECT
pickup_ntaname,
toHour(pickup_datetime) as pickup_hour,
SUM(1) AS pickups
FROM trips
WHERE pickup_ntaname != ''
GROUP BY pickup_ntaname, pickup_hour
ORDER BY pickup_ntaname, pickup_hour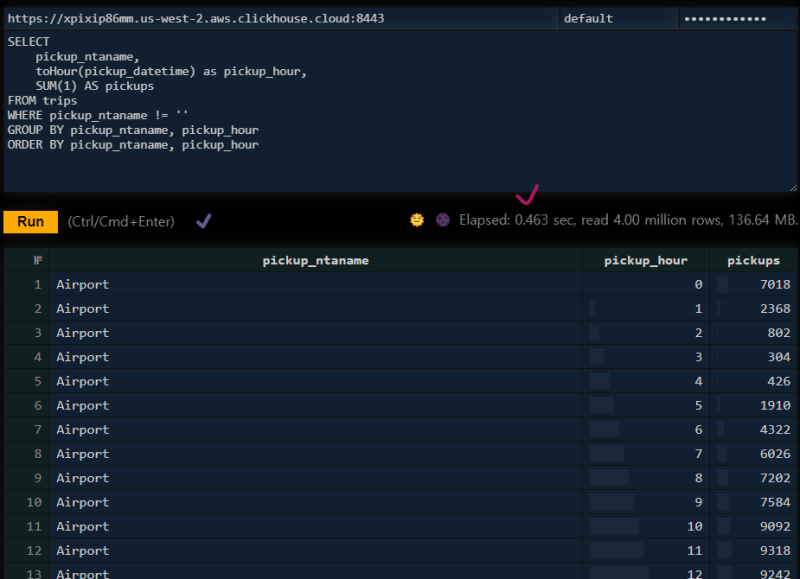 깊게 써보진 않았지만 잘 만들긴 잘 만든 것 같다.
깊게 써보진 않았지만 잘 만들긴 잘 만든 것 같다.
참조
https://clickhouse.com/docs/en/sql-reference/statements/select/