[MongoDB] text 인덱스로 검색 구현하기
텍스트에 대한 검색은 참 어려운 문제 중 하나라고 할 수 있다. 그냥 무식하게 조건을 걸자면 성능이 박살나기도 하고, 가중치나 여러가지 요소들을 고려할 필요가 있기 때문이다.
다행히도 mongoDB는 이런 경우에 맞는 텍스트 인덱싱 기능을 제공한다. 전용 시스템인 elasticsearch 같은 것과 비교하면 좀 부족하긴 하지만, 대강 비슷하게 tokenizing과 가중치 설정 등이 가능하다.
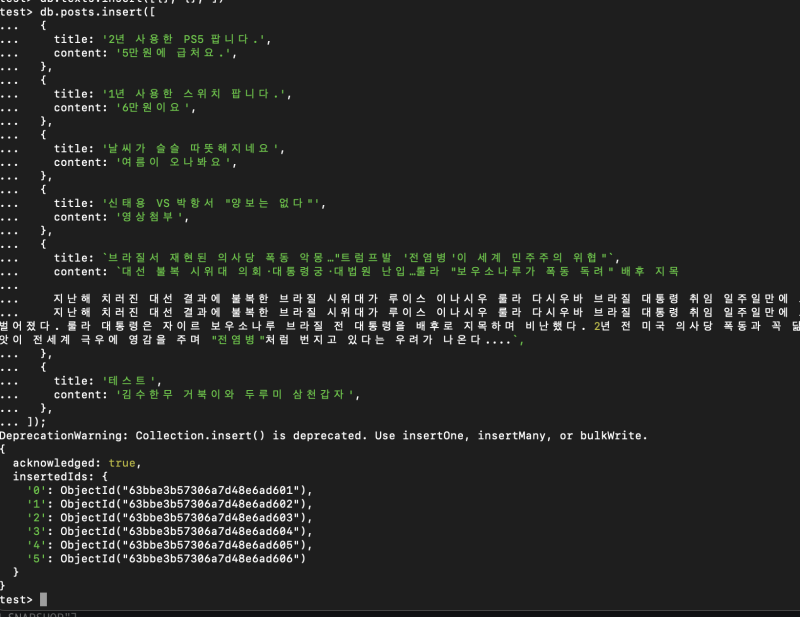
테스트 데이터는 이렇다.
일반 인덱스로 검색
한 필드에만 검색을 하는 간단한 경우에는 일반 인덱스로 처리를 할 수도 있다.
불편할 수도 있지만, 동작은 한다.
그냥 이렇게 인덱스 달아놓고 날리면

잘 가져오고
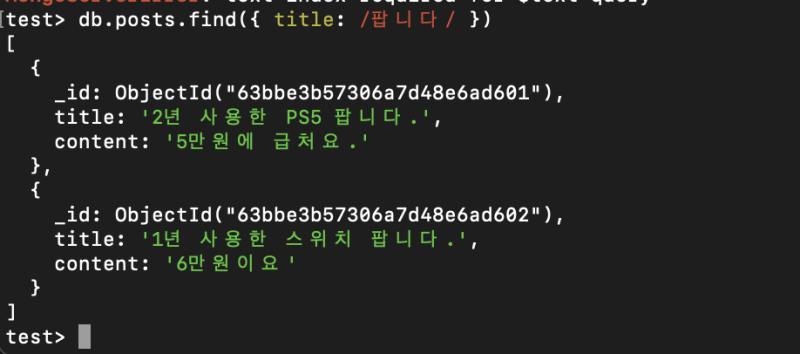
인덱스도 걸어준다.
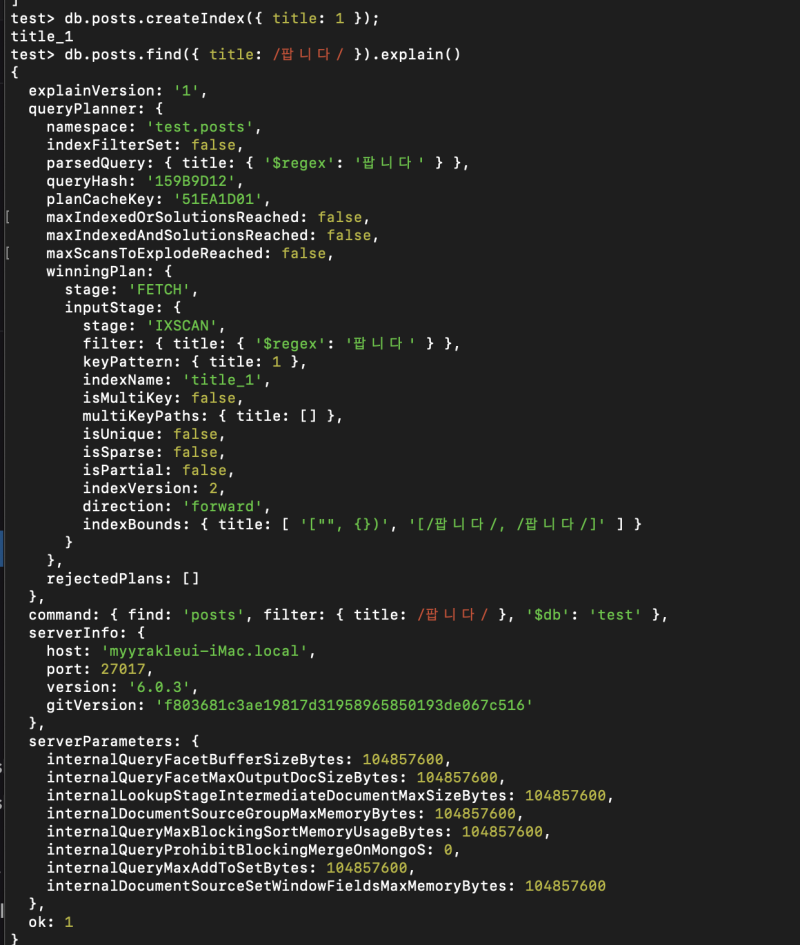 RDB들과는 다르게 와일드카드를 붙여서 돌려도 인덱싱을 꽤 잘 해준다.
RDB들과는 다르게 와일드카드를 붙여서 돌려도 인덱싱을 꽤 잘 해준다.
text 인덱스 만들기
근데 또 여러 컬럼에 대해 검색을 해야하고 그러면 아무래도 텍스트용 인덱스를 쓰는 편이 좋다.
이렇게 만들 수 있다. 텍스트 검색의 대상으로 삼고 싶은 컬럼을 다 'text'로 지정해주면 된다.
db.컬렉션.createdIndex({
필드명: 'text'
})
필드가 고정적이지 않고 모든 문자열 필드에 text를 달고 싶다면, 이렇게 와일드카드를 지정해도 된다.

text 검색하기
검색은 어렵지 않다.
이런식으로 기존 find에 $text 속성을 활용해서 검색키워드를 제공하면 된다.
db.컬렉션.find({
"$text": {
"$search": "검색어..."
}
})이러면 text 인덱스가 걸린 모든 필드에 대해 검색을 수행한다.
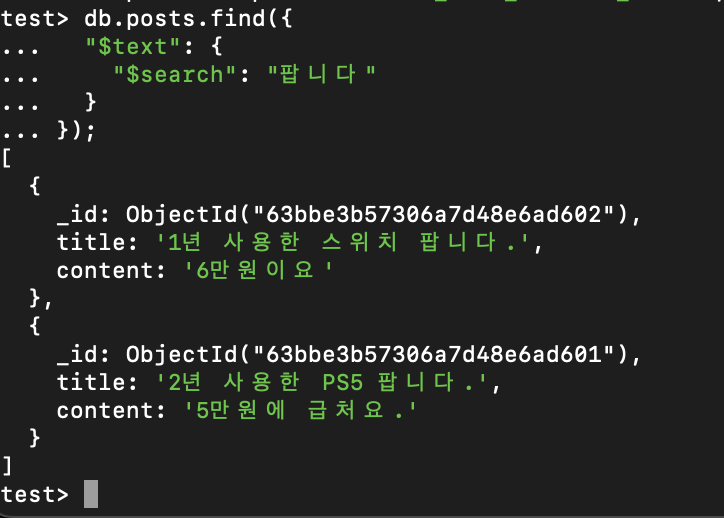
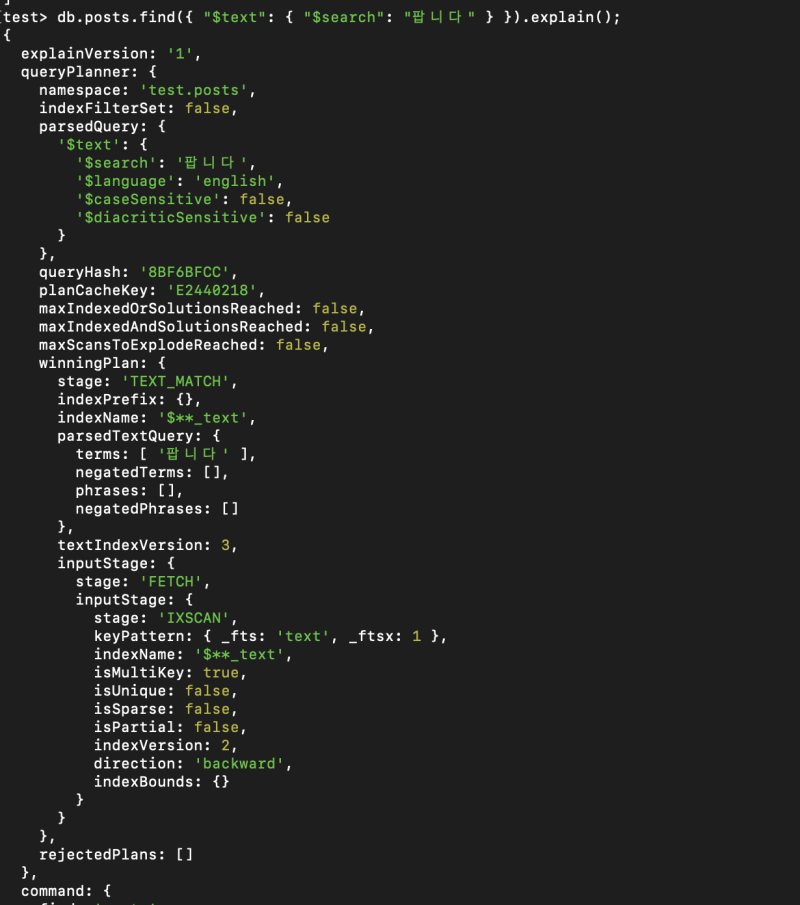 잘 가져오고, 인덱싱도 잘 되는 것을 확인할 수 있다.
잘 가져오고, 인덱싱도 잘 되는 것을 확인할 수 있다.
tokinizing 문제
그런데 막 쓰다보면 문제가 좀 있을 수 있다.
text 인덱스는 모든 검색어를 화이트스페이스를 기준으로 분리하고 그 각각의 token으로 쿼리를 한다.
이렇게 말이다.
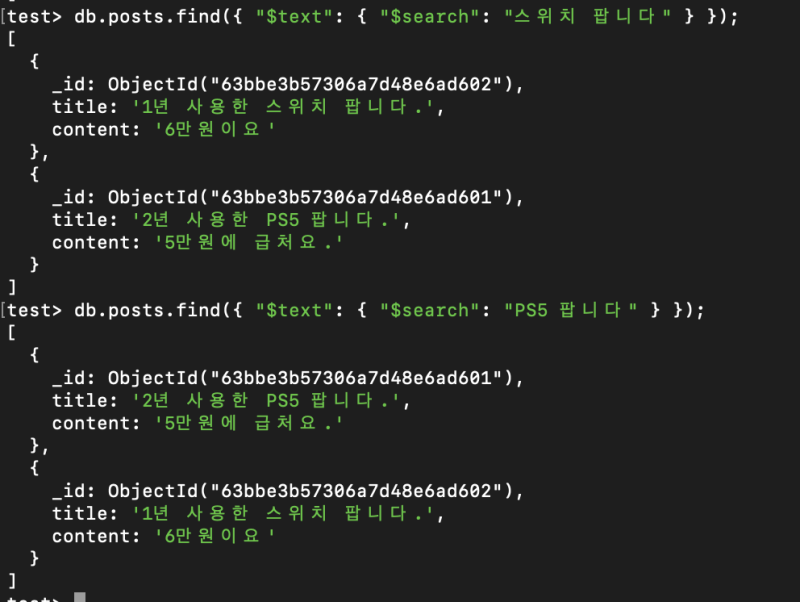 그래서 "스위치 팝니다"라고 검색한다고 해서 "스위치 팝니다"가 포함된 모든 텍스트를 가져오는게 아니라, "스위치", "팝니다." 2개의 token으로 OR 필터 검색을 한다.
그래서 "스위치 팝니다"라고 검색한다고 해서 "스위치 팝니다"가 포함된 모든 텍스트를 가져오는게 아니라, "스위치", "팝니다." 2개의 token으로 OR 필터 검색을 한다.
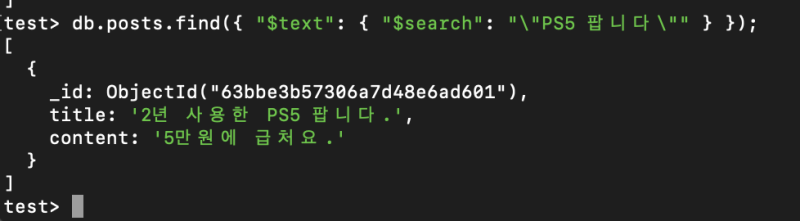
만약 "스위치 팝니다" 자체를 하나의 토큰으로 인식하게 하려면, 큰따옴표로 묶어줘야 한다.
tokenizer도 필요에 따라서 커스텀이 필요할 수도 있다.
그건 나중에 쓸일이 있을때 따로 정리해보겠다.
검색어 점수: textScore
text search는 token 단위로 쪼개서 OR로 조건을 건다고 했었다.
그래도 위의 경우들을 보면 일치도가 높은 것을 먼저 보여주긴 한다.
이건 또 "textScore"라는 걸 통해 검색 일치도 점수를 쌓고 그걸 내림차순으로 뿌려줘서 그런 것이다.
점수를 보고 싶다면 이런식으로 쿼리를 주면 된다.
db.posts.find({ "$text": { "$search": "스위치 팝니다" } }, { score:{$meta : 'textScore'} });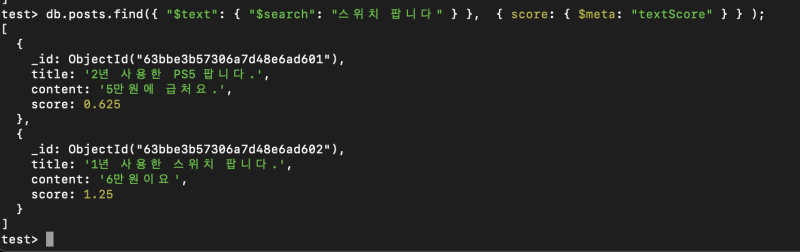 첫번째 값은 "팝니다" 토큰 하나만 일치하니, 0.625점, 두번째 값은 "스위치" "팝니다" 2개 토큰이 다 일치하니 1.25가 나왔다.
첫번째 값은 "팝니다" 토큰 하나만 일치하니, 0.625점, 두번째 값은 "스위치" "팝니다" 2개 토큰이 다 일치하니 1.25가 나왔다.
검색어 점수: 필드별 가중치
근데 여러 필드에 대해 검색을 하더라도, 필드마다 우선순위에 차이는 있을 것이다.
별다른 설정을 하지 않는다면 그냥 똑같은 가중치에 텍스트 길이에 비례해서만 점수가 부과되는데
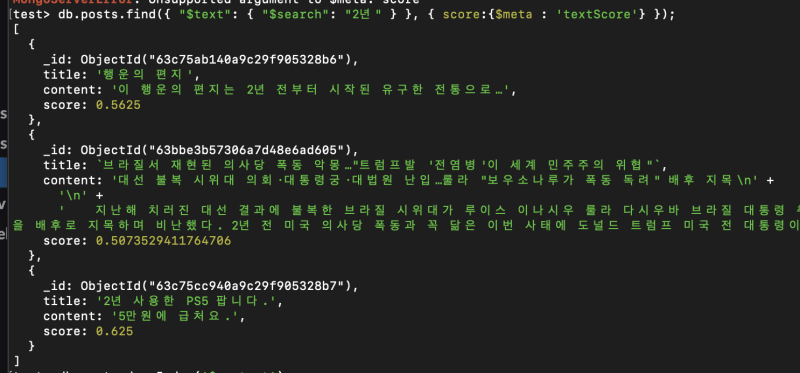
인덱스를 생성할때 옵션을 주면 그 비례치를 조정할 수 있다.
이러면 content가 title의 5배의 가중치를 갖게 된다.
db.posts.createIndex(
{ '$**': 'text' },
{ weights:
{
title: 1,
content: 5
}
}
);그러면 내용에 키워드가 포함된 항목의 점수가 뻥튀기가 될 것이다.
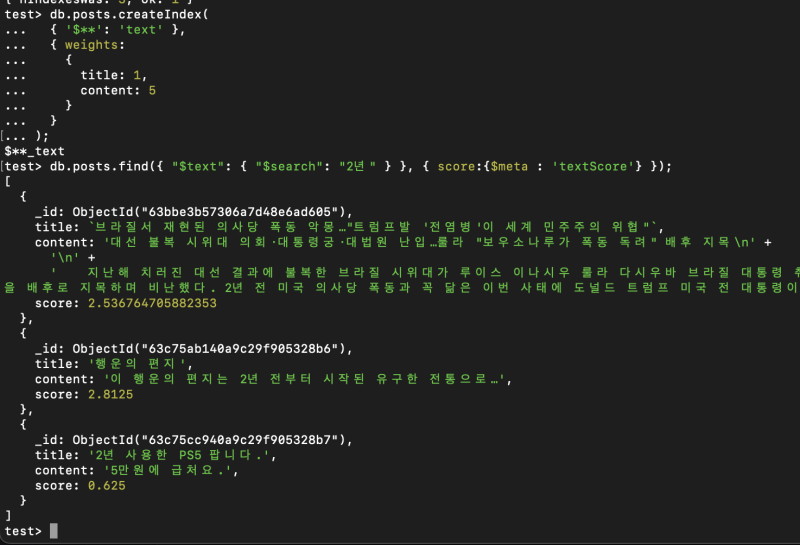
그렇다.
참조
https://www.mongodb.com/docs/manual/core/index-text/
https://www.mongodb.com/docs/manual/reference/operator/query/text/