데이터베이스의 복제(Replication)
현재 21세기 시스템, 아키텍처에 있어서 가장 큰 화두는 아마 분산시스템일 것이다.
갈수록 데이터가 커짐에 따라 단일 장비로는 충분한 성능을 내지 못하게 되었고, 노드를 여러개 띄워서 부하를 나누어 처리하게 되는 분산시스템들을 지향하게 된 것이다.
복제(Replication)는 분산시스템을 구축하는 대표적인 방법 중 하나다.
이점
복제를 사용해서 얻을 수 있는 이점은 대략 이렇다.
- 노드를 지리적으로 가까운 곳에 둬서 읽기 지연을 줄일 수 있다.
- 노드 중 일부가 하드웨어든 뭐든 장애가 발생해도, 나머지 노드로 정상적인 동작을 보장할 수 있다.
- 읽기 처리량을 크게 늘릴 수 있다. (구성하기에 따라 쓰기 처리량도.)
복제 알고리즘의 종류
복제에 주로 사용되는 알고리즘으로는 Single-Leader, Multi-Leader, Leaderless 3가지 정도가 있다.
Single-Leader Replication
가장 고전적인 알고리즘이라 할 수 있다.
대부분의 관계형 데이터베이스가 이 복제 기능을 제공하고, MongoDB를 포함한 일부의 NoSQL들도 지원한다.
말 그대로 전체 시스템을 관리하기 위한 하나의 리더(Leader)를 두고, 그놈이 전부 책임지게 하는 것이다.
원래는 Master-Slave라고도 부르는데, 요즘은 검열당해서 잘 쓰지 않게 됐다.
 여기서 중요한건 "쓰기 작업"은 마스터만 받아야 한다는 것이다.
여기서 중요한건 "쓰기 작업"은 마스터만 받아야 한다는 것이다.
데이터가 추가되거나, 수정되면, 마스터는 그 변경사항들을 slave에 전부 뿌려준다.
그래서 마스터는 쓰기 작업을 책임지고, slave는 읽기 작업을 담당하는 것이 일반적인 사용 구조가 되겠다.
당연히 이것도 단점이 꽤 많은데, 쓰기 작업이 마스터에만 몰린다는 것이다.
게다가 마스터가 SPOF가 된다. 마스터가 터지면 전체적인 문제가 발생한다.
문제가 발생할 경우 다른 slave들 중에 새 마스터를 선출하도록 구성하는 방법도 있는데, 이 또한 완전하지 않고 부수적인 데이터 손실이 발생할 수 있다.
그래서 장애 복구는 수동으로 하는 경우가 꽤 많다.
게다가 master-slave 간에는 필연적으로 복제 지연 시간이 발생한다. 정상적인 상태라면 1초 미만으로 복제가 되겠지만, 더 걸릴 수도 있다.
Multi-Leader
아무래도 Single-Leader 방식은 근본적으로 치명적인 약점을 갖고 있다. 뭘 어떻게 해도 마스터에 문제가 생기면 말짱 꽝이라는 것이다.
그래서 내놓은 해결책이 그냥 리더를 여러개 두는 multi-leader 알고리즘이다.
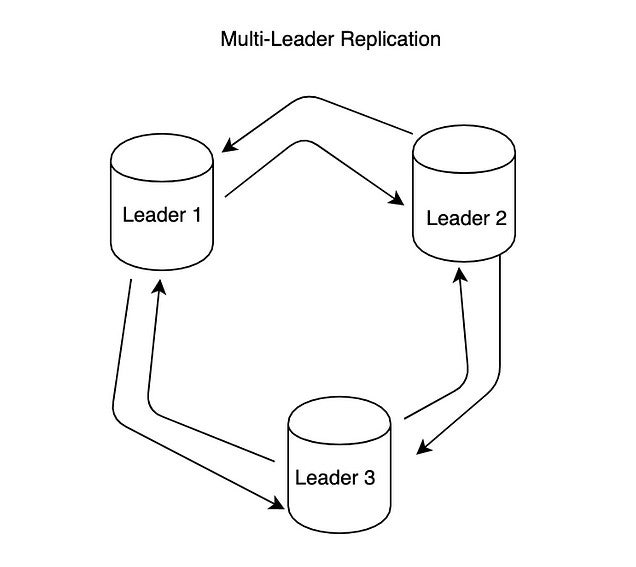 여러개의 리더들이 있고, 다 쓰기를 받아줄 수 있고, 쓰기를 받으면 다른 모든 노드에 전파해줘야 한다.
여러개의 리더들이 있고, 다 쓰기를 받아줄 수 있고, 쓰기를 받으면 다른 모든 노드에 전파해줘야 한다.
이것도 역시 단점은 많다. 모든 리더가 쓰기를 받고, 그걸 다 전파해서 쓰기 자체에 발생하는 지연시간이 좀 늘어날 수 있다.
그리고 여러개의 리더가 동일한 데이터를 수정할 때 충돌이 발생할 수 있다. 이건 좀 치명적인 부분이라고 할 수 있다.
이것도 마찬가지로 복제 지연이 발생할 수 있다.
일부 데이터베이스에서만 이런 복제 기능을 제공하고, 그마저도 대부분 근래에 추가된 기능이다.
관계형 데이터베이스들은 별도 서드파티 도구를 사용해야 구축이 가능하다.
아직은 위험성이 많이 존재한다.
Leaderless
리더를 두고 관리하는 것으로 인해 발생하는 문제가 어마어마하다보니, 아예 리더를 버리는 움직임도 나오기 시작했다.
AWS의 DynamoDB가 그 시작이었고, 카산드라DB 등도 이러한 방법론을 취한다.
노드1, 노드2, 노드3가 있다면, 원래 leader를 사용하는 방식에서는 노드 하나에만 쓰기를 보내고 그 노드가 책임지고 나머지 노드에 복제를 해줬었다.
leaderless는 그런 고정관념에서 아예 벗어나서, 클라이언트가 노드1, 노드2, 노드3에 쓰기를 다 직접 와장창 꽂아버리는 식으로 굴러간다.
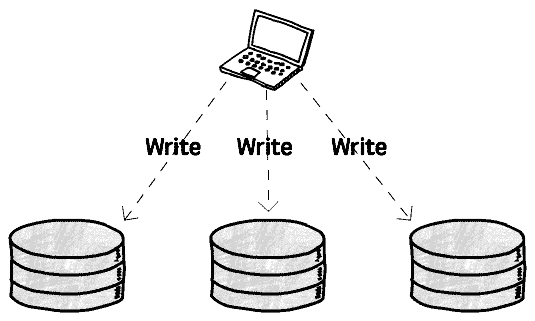 그래서 읽기를 수행하는 방법도 신박하고 재밌다.
그래서 읽기를 수행하는 방법도 신박하고 재밌다.
만약 노드가 3개가 있는데 2개에만 쓰기가 성공하고 1개는 실패한다면 읽어오는데도 문제가 생길 것이다.
이럴때는 아예 3개 노드에서 전부 데이터를 읽어온 다음 "가장 최신 버전의 데이터"를 진짜 데이터로 간주해서 사용하는 방법을 취한다. 이를 위해서 각 데이터는 내부적으로 버전 값을 갖고 있다.
그리고 이것도 당연히 단점이 있다.
일단 클라이언트가 직접 내다꽂는 느슨한 구조를 갖고 있어서, 동시에 같은 데이터를 수정하면 충돌이 발생할 수 있다.
구조를 염두에 두고 애플리케이션 레벨에서 잘 조정해줘야 한다.
참조
"데이터 중심 애플리케이션 설계", 마틴 클레프만, 위키북스(2018)
https://www.brianstorti.com/replication/