[분산 시스템] CAP
CAP은 분산 데이터베이스 시스템에서 요구하는 3가지 주요 달성 지표다. RDB에서 말하는 ACID같은 것과 대략 비슷하다.
하지만 현재는 근본적인 한계로 인해서 완전한 달성은 불가능하다는 것이 중론이다.
CAP은 다음과 같이 일관성(Consistency), 가용성(Availability), 파티션 내구성(Partition tolerance) 3개로 이루어지는데
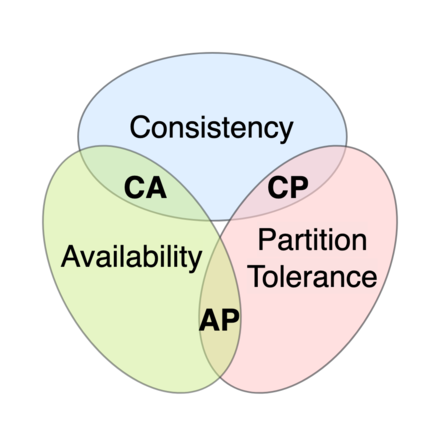 이중에서 2가지를 달성하려면 나머지 하나는 포기를 해야 한다는 것이다.
이중에서 2가지를 달성하려면 나머지 하나는 포기를 해야 한다는 것이다.
특히 파티션 내구성(Partition tolerance)을 보장하려면 일관성(Consistency)과 가용성(Availability) 중에 하나만 선택해야 한다는 주장으로 사용된다.
그래서 아직 이 3가지를 다 완벽히 충족한 DB는 없다...
일관성(Consistency)
데이터의 일관성을 말한다.
최적의 일관성을 보장하는 시스템이라면
"최신 데이터를 항상 반환해주거나, 그럴 수 없다면 오류를 반환해야 한다."
만약 어떤 데이터의 값을 300에서 500으로 수정하고 조회하면 항상 500이라는 값이 나와야 한다.
하지만 머신 자체가 여러개인 분산 환경에서는 데이터베이스의 A 노드에서는 500이 나오고, B 노드에서는 300이 나오는 그런 동작이 가능하다.
이건 당장 RDB를 master-slave로만 replica 구성을 해도 와장창 깨져버리는 상황을 잔뜩 볼 수 있다. master에서 read replica로 전송시키는 지연 시간이 발생하기 때문이다...
가용성(Availability)
가용성은 일반적으로 말하는 가용성과 같다.
"어떠한 부분 장애 상황에서도 오류가 발생하지 않고, 성공적인 응답을 줄 수 있는지"다.
다시 말해 일부 노드에 장애가 발생하더라도 전체 시스템이 고장나지 않게 할수 있는 내결함성 같은걸 말한다.
여기서 말하는 장애는 보통 네트워크 파티션을 말하는데, 노드끼리 통신할때 타임아웃이나 기타 오류가 뜨는 모든 상황을 가리킨다.
파티션 내구성(Partition tolerance)
파티션 내구성은 네트워크 장애 등으로 노드간의 연결이 끊기더라도, 각각의 노드가 독립적으로 동작할 수 있음을 뜻한다.
대부분의 분산시스템은 이걸 다 깔고간다.
어지간해서는 포기하지 않는다.
RDB의 경우
구성하기에 따라 다르다.
RDB들은 보통 단순한 single master- multi slave 구조로 async replica를 구성하는 경우가 많은데,
사실 이러면 파티션 내구성도 없고 일관성 보장도 안되는데다 마스터가 죽으면 다 터지니 가용성도 없다...
하지만 single master- multi slave에서 sync 레플리카를 구성하면 일관성만은 보장이 가능하다. (C)
multi master에 async 레플리카를 구성할 경우에는 가용성이나 파티션 내구성이 보장이 된다.
데이터 복제가 비동기라서 일관성은 없다. (AP)
multi master에 sync 레플리카를 구성할 경우에는 일관성과 파티션 내구성이 보장된다.
그대신 하나 터지면 다 터진다... (CP)
근데 RDB에서 multi master를 구성하는건 너무나도 머리아프고 고통스러운 일이라서, NoSQL들을 사용하는게 정신건강에 이롭다.
일관성을 포기한 경우 (AP)
이걸 포기하고 가용성과 파티션 내구성을 챙긴 DB로는 CouchDB, CassandraDB, ScyllaDB, AWS DynamoDB 등이 있다.
이 시스템들은 write를 하더라도 모든 노드에 공평하게 복제가 된다는 보장이 없다.
부분적으로 일관성을 확인할 수 있는 기능이 제공되나, 기본적으로는 보장되지 않는다.
가용성을 포기한 경우 (CP)
이걸 포기하고 일관성과 파티션 내구성을 챙긴 DB로는 MongoDB, Couchbase, Redis Cluster, HBase 등이 있다.
예를 들어 MongoDB는 쓰기가 완료되면 모든 노드에서 최신 수정본을 확인할 수 있지만, primary node에 장애가 발생했을 경우 새 primary node를 투표해서 띄울때까지 downtime이 발생한다.
그래서 가용성이 부족한다고 말하는 것이다.
항상 master가 모든 복제를 책임지고 통제하니 일관성을 높게 지킬 수 있지만, 이런 장애상황에서의 가용성을 보장할 수는 없다.
파티션 내구성을 포기한 경우 (AC)
별로 없다.
유명한 시스템 중에서는 Kafka 정도가 여기에 속한다고 할 수 있겠다.
기타: 설정하기에 따라 다른 놈들
Elasticsearch는 관점에 따라 CAP 충족사항이 좀 다르다.
쓰기 작업은 가용성보다 일관성을 선택해서 CP이고, 읽기 작업은 일관성보다 가용성을 선택해서 AP다.
쓰기는 실패해도 괜찮지만, 읽기는 조금 이상한게 있더라도 우선 가져오는게 좋다는 검색시스템의 사용 측면을 고려한 것이다.
참조
https://geunyang93.tistory.com/m/41
https://majidfn.com/blog/mysql-sync-vs-async-replication/
https://discuss.elastic.co/t/which-side-of-cap-theorem-elasticsearch-satisfy/177810
http://happinessoncode.com/2017/07/29/cap-theorem-and-pacelc-theorem/
https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/
https://blog.nullbus.net/91
https://blog.codingconfessions.com/p/the-cap-theorem-of-clustering