[ML] 강화학습(Reinforcement Learning)
강화학습(Reinforcement Learning)은 머신러닝의 학습 방법론 중 하나다.
여러모로 현대 머신러닝에의 토대가 되었다고 할 수 있다.
기본 원리
우리가 언어나 기술, 경험 등을 어떻게 습득하던가? 사실 뭐 대단한 테크닉이 있는게 아니다.
그냥 현실 속에서 하나씩 시도해보고, 경험해본 것들이 쌓여서 우리 안에 자연스럽게 내재되는 것이다.
강화학습도 현실에서의 인간과 같은 학습 논리를 따르는 접근방법이다.
만약 생쥐가 미로에서 치즈를 찾는 것을 강화학습으로 구성한다고 하면, 이런 형태가 된다.
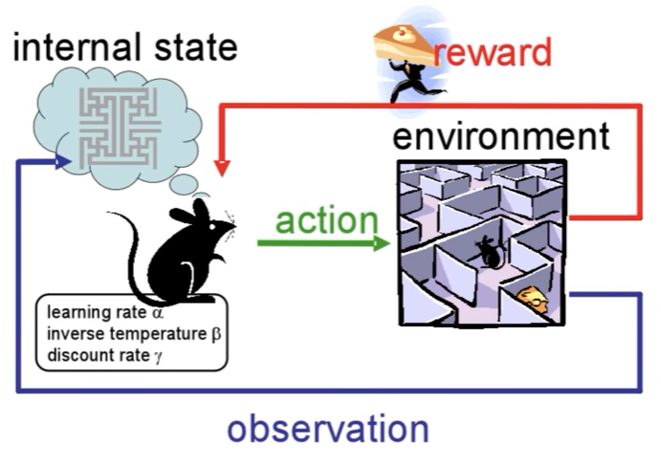 생쥐가 한칸 이동할때마다 action이 발생하고, 그 결과는 환경을 거쳐 내부 상태에 저장되고 학습된다.
생쥐가 한칸 이동할때마다 action이 발생하고, 그 결과는 환경을 거쳐 내부 상태에 저장되고 학습된다.
그리고 성공한다면 치즈라는 reward를 받게 될 것이다.
역사
발단
강화학습은 1997년에 Tom Mitchell이 "Machin Learning"이라는 저서를 통해 처음 제시했다.
생각보다 오래된 개념이다.
하지만 한동안은 그다지 주목을 받지 못했다.
부흥
강화학습이 본격적으로 주목을 받게 된 것은 역시 구글의 딥마인드(Deep Mind)팀에 의한 것이다.
한때 유명했던 알파고가 바로 강화학습으로 만들어진 AI다.

현재
현재도 버림받지 않고 핵심 이론으로서 계속해서 사용되고 있다.
유명한 tensorflow 같은 프레임워크들도 딥러닝과 섞인 deep reinforcement learning를 기반으로 만들어졌고, 주식시장을 뒤흔들었던 chatgpt나 bing ai 같은 챗봇형 ai들도 강화학습 기반이라고 할 수 있다.
장단점
장점
기존 기술로 해결할 수 없거나 어려운 매우 복잡한 문제를 해결하기 용이하다.
단점
역시, 학습을 위한 무수한 데이터와 연산이 필요해서 리소스 소비가 매우 극심한 편이다.
딥 러닝(Deep learning)
딥러닝은 강화학습과는 다른 개념이지만, 상충되지도 않는다.
딥러닝은 그저 학습 집합으로부터 어떻게 학습하고, 진행한 학습을 새 데이터에 어떻게 적용시킬지에 대한 방법론이다.
반면 강화학습은 최고의 reward를 위해서 동적으로 학습하며 action을 바꾸어나가는 방법론을 말한다.
따라서 딥러닝과 강화학습은 상호보완이 가능하며, 딥러닝 프레임워크라고 말하는 tensorflow 등도 둘을 전부 활용하는 deep reinforcement learning이라고 할 수 있다.
참조
https://hunkim.github.io/ml/
https://pythonistaplanet.com/pros-and-cons-of-reinforcement-learning/