[Meilisearch] 검색 기준 우선순위
Ranking Rules
검색에는 항상 우선순위라는 것이 있다.
meilisearch는 rankingRules라는 설정을 통해 가장 높은 수준의 우선순위 조건을 관리한다.
예를 들어, rankingRules의 기본값은 다음과 같다.

"rankingRules":["words","typo","proximity","attribute","sort","exactness"]words를 기준으로 정렬하고, 그 와중에 words 점수가 같은게 있으면 typo 점수로 정렬하고... 그런 식으로 돌아간다.
하나씩 살펴보면 동작원리를 이해하기가 더 쉬울 것이다.
- words
일치하는 단어가 많을수록 정확도가 높다고 판단하는 것이다.
그래서 다른 조건의 점수가 아무리 높더라도, word 개수가 일치하는 것이 많은 항목이 최우선순위로 노출된다.
-
typo
오타를 허용했을 경우, 오타가 적은 경우를 더 정확하다고 판단한다. -
proximity
검색어가 먼저 검색 데이터와 동일한 순서로 서로 가깝게 나타나는 document를 반환한다. -
attribute
attribute, 그러니까 필드 간의 우선순위를 따라 정렬한다. 아래에 정리해뒀다. -
sort
(sort 쿼리에 한해서) sort 정렬 기준으로 정렬한다. -
exactness
검색어와 일치하는 단어의 유사성을 기준으로 결과가 정렬된다. (이건 무슨 말인지 모르겠다.)
필요에 따라서 순서는 얼마든지 조정할 수 있다.
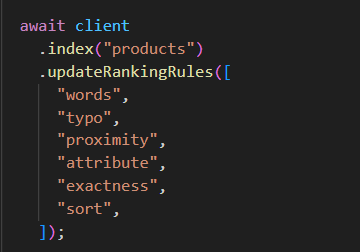
attribute 우선순위
필드 간의 우선순위를 부여해서 특정 필드가 일치할때 점수를 더 부여해주는 그런 기능이다.
우선순위는 searchableAttributes 내에 있는 순서로 결정되는데, 이건 따로 설정하지 않으면 와일드카드라서 직접 지정을 좀 해줘야 한다.
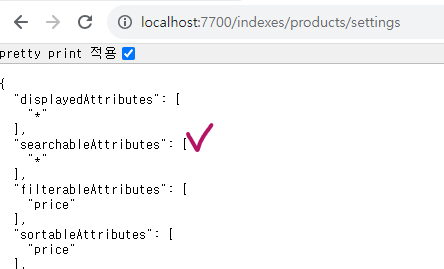

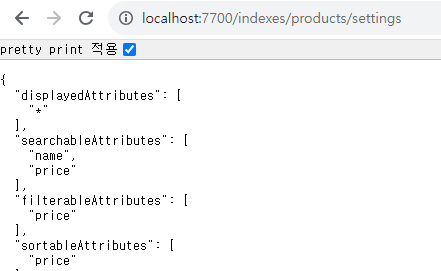 이런식으로 말이다.
이런식으로 말이다.
그리고 이 순서가 유효하게 동작하게 하려면 ranking rule에서도 attribute를 높은 순위로 올려줘야 한다.