이슈노트 #8: 의문의 동시성 버그
1. 발단
어느 시점부터 의문의 오류 상황이 지속적으로 발생하기 시작했다.
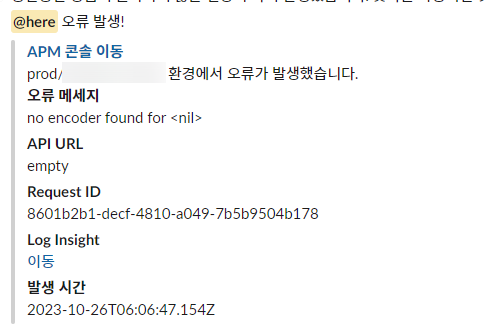 오류 발생이 시작된 시점은 명확하지 않았고, 원래도 드문드문 발생하다가 사용량이 증가하면서 오류 발생률이 급증하게 되었다.
오류 발생이 시작된 시점은 명확하지 않았고, 원래도 드문드문 발생하다가 사용량이 증가하면서 오류 발생률이 급증하게 되었다.
게다가 이 시스템 자체가 메세지 큐를 기반으로 느슨하게 결합된 비동기 시스템이라서 오류 추적이나 해결에 어려움이 컸다.
어째서인지 dev나 qa 스테이지에서는 재현이 되지 않고, production에서만 사용량이 증가할 때 한해서만 발생했다.
2. 시스템 구조
경위 파악에 앞서 시스템의 구조를 정리해보자면, 대략 다음과 같은 아키텍쳐 구조도를 갖고 있었다.
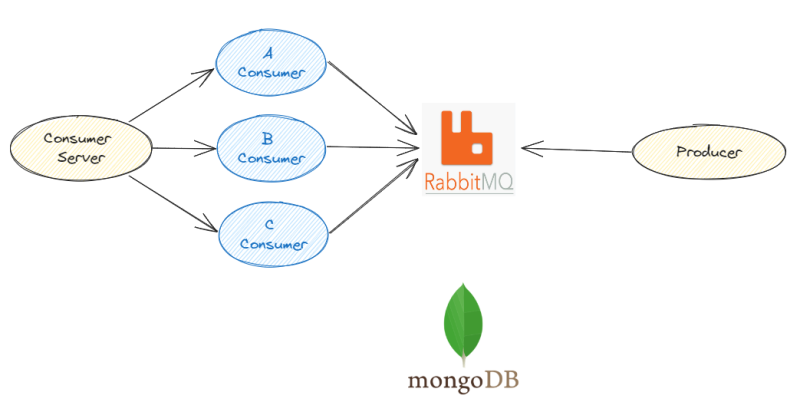 RabbitMQ는 AWS에서 제공하는 Amazon MQ였고, mongoDB는 atlas에서 aws에 호스팅하는 노드 3개짜리 dedicated replicaset 클러스터였다.
RabbitMQ는 AWS에서 제공하는 Amazon MQ였고, mongoDB는 atlas에서 aws에 호스팅하는 노드 3개짜리 dedicated replicaset 클러스터였다.
여기서 관련된 제어 흐름을 정리하면 이렇다.
- 프로듀서는 독립된 주제마다 일련의 이벤트를 큐에 전송한다.
- 컨슈머 측 서버는 독립된 주제마다 하나의 컨슈머 프로세스를 생성해서 일련의 이벤트를 처리한다.
- "독립된 주제" 단위마다 MongoDB를 사용해서 Lock을 생성하고 이를 통해 하나의 주제에는 하나의 Consume만이 생성되도록 유도했다.
- 하나의 "독립된 주제"에는 여러가지 무겁고 복잡한 Action들이 나열되어있고, 순서대로 실행되어야만 했다.
- 그래서 그 Action들의 올바른 순서를 RabbitMQ의 FIFO에 의존했다. A 이벤트, B 이벤트, C 이벤트 등을 RabbitMQ에 순서대로 전송하고, Consumer들이 그 메세지를 순서대로 받아서 실행하게끔 한 것이다.
- 한 주제에서의 순서 보장은 Lock을 통해 해결했다. 주제 ID를 기반으로 Lock을 생성한 것이다.
이걸 그림으로 그려보면 이랬다.
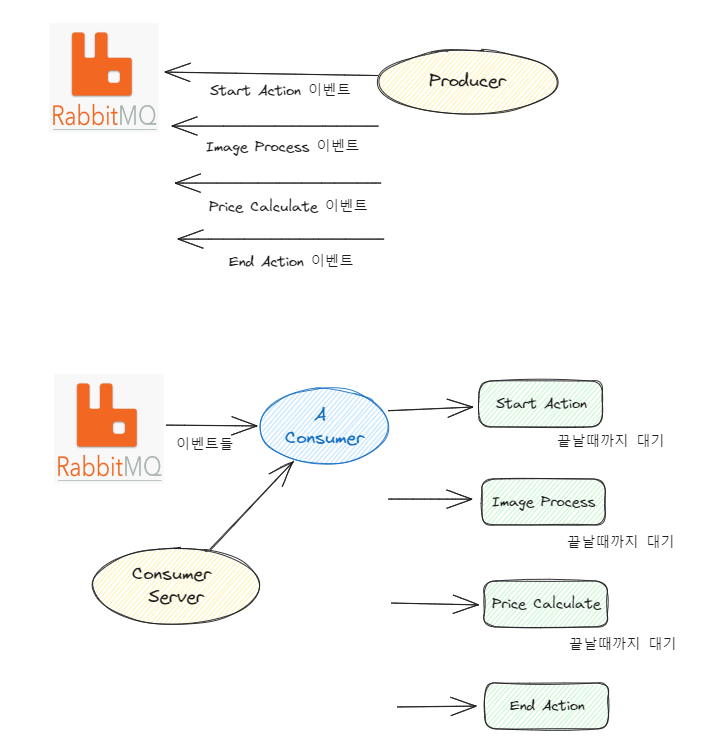 Lock은 github.com/square/mongo-lock 모듈을 통해서 구현했다.
Lock은 github.com/square/mongo-lock 모듈을 통해서 구현했다.
3. 분석
다시 돌아가서 오류 상황을 보면, 저건 이전 작업이 제대로 완료되지 않았을 때 발생하는 오류였다.
RabbitMQ FIFO로 순서 보장을 해뒀기 때문에 2번째 프로세스는 1번째 프로세스에서 완료된 결과를 가져다가 재가공을 하는 식인데, 1번째 프로세스에서 처리가 덜된 데이터를 받아서 저 오류가 난 것이다.
우리는 혼란에 빠졌다.
4. 첫번째 시도: MongoDB Write Concern
우리가 가장 먼저 시도한 것은 MongoDB의 데이터 부분이었다.
각 프로세스에서 작업한 결과물은 MongoDB를 통해 계승되는데, 쓰고 읽는 도중에 지연이 발생할 가능성이 있었기 때문이었다.
MongoDB 클러스터를 쓸 때에는, 다른 분산시스템들과 마찬가지로 복제 지연이 발생한다.
MongoDB 클러스터는 single master-multi slave의 구조를 가지고, 쓰기가 발생하면 master가 쓰기를 받아서 나머지 노드에 데이터를 동기화한다.
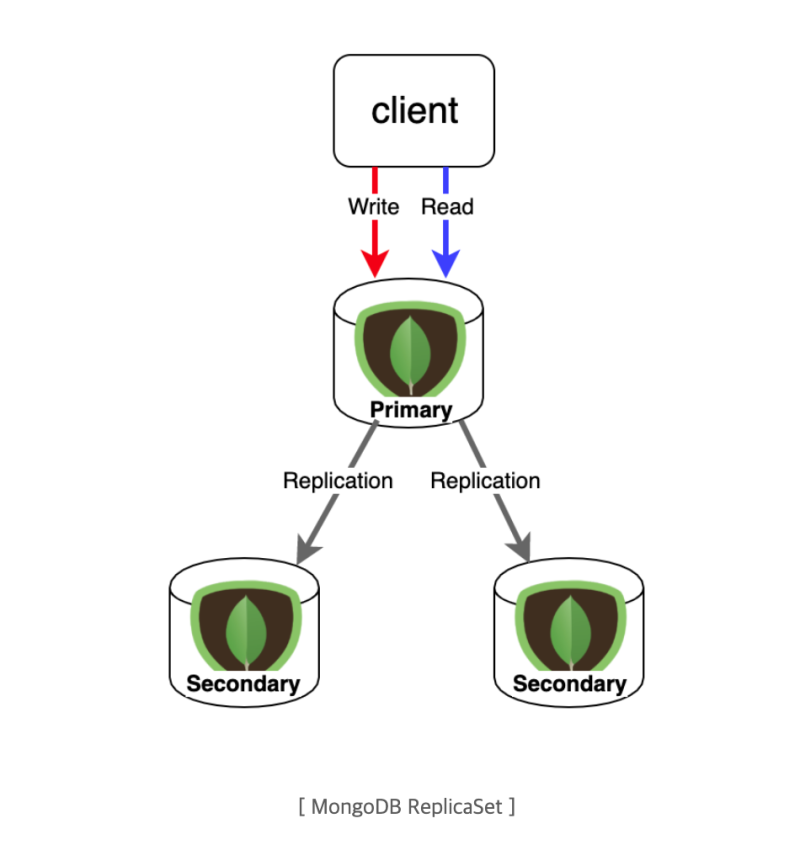
그런데 당연히 이런 동기화에는 반드시 지연 시간이 존재하고, 이 지연은 네트워크나 기타 상황에 따라 마이크로초에서 밀리초까지도 걸릴 수 있다.
그래서 그냥 이렇게 코드를 짜면
store.CreateSomeData(Params{
ID: "1234"
}) // 삽입 성공
store.FindByID("1234") // 하지만 조회되지 않음..이런 어이없는 상황이 벌어질 수가 있다.
일반적으로 정상적인 언어들에서 각 코드 인스트럭션은 나노초 단위로 실행되기 때문에, 쓰고 나서 바로 읽더라도 그 쓰기가 반영되지 않은 노드에서 데이터를 읽어올 수 있는 것이다.
이런 현상에 대응하는 방법 중 하나는 Write Concern을 사용하는 것이다.
아래 커맨드를 날리면 Write Concern 설정을 조회할 수 있는데
db.adminCommand(
{
getDefaultRWConcern: 1 ,
}
)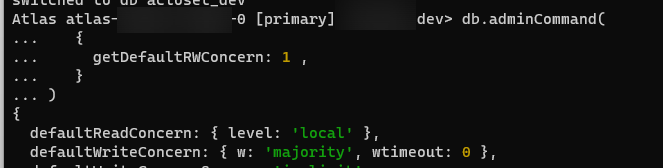 어지간해서 기본 설정은 majority다.
어지간해서 기본 설정은 majority다.
저건 정족수, 그러니까 노드 중 과반수에 복제가 완료되면 쓰기 작업이 "끝났다"고 판단하겠다는 것이다.
그래서 노드가 3개인 일반적인 상황에서는, 노드 2개에만 데이터가 동기화돼도 쓰기가 끝났다고 판단해서 오퍼레이션을 끝낸다. 노드 1개에 동기화되지 않은 찰나의 순간에 코드가 그 노드에서 읽기를 수행할 수 있는 것이다.
우리는 부하가 급증했을 때 복제 지연이 늘어나서 이러한 엣지케이스가 발생한 것이라고 여겼고, 쓰기를 수행할때마다 write concern 숫자를 노드의 전체 개수인 3으로 지정해서 3개에 복제가 다 된 다음에 다음 코드로 넘어가게끔 유도했다.
이것으로 해결이 되리라고 믿었다.
5. 두번째 시도: 무식한 retry
그럼에도 불구하고 상황은 나아지지 않았다.
당시 우리는 데이터의 동기화 지연 이외에는 다른 가능성을 생각하지 못했기 때문에, write concern이 기대대로 동작하지 않는다고 여겼다.
그래서 무식하지만 그냥 문제의 로직에서 read를 할때 100밀리초씩 5번까지 retry를 시도하도록 했다.
이게 안되면 진짜 MongoDB의 문제가 아니었을 것이다.
그리고... 실패했다,.
6. 고찰
mongoDB의 데이터는 문제가 아니었다.
500밀리초까지 기다려도 안되면 그건 동기화 문제가 아니라 다른 부분에 있는 것이다. 아무리 그래도 지연이 그렇게 걸릴 수가 있겠는가?
데이터 문제가 아니라면 정말 각 이벤트 액션의 순서가 꼬이는 것 말고는 경우가 존재하지 않았다.
그래서 RabbitMQ에서 엄격한 FIFO를 보장하지 못하는 건가 싶어서 좀 봤는데, FIFO를 보장할 수 있는 조건은 다 갖추고 있었다.
액션의 순서를 보증해주는 것은 MongoDB Lock과 RabbitMQ 둘이었다. 둘 중 하나에 문제가 있는 것은 분명해보였다.
7. 발견
혹시나 싶어 Lock 데이터를 까보니, 어째서인지 Lock 데이터가 동일 주제에 대해서 중복으로 생성되는 경우가 있었다.
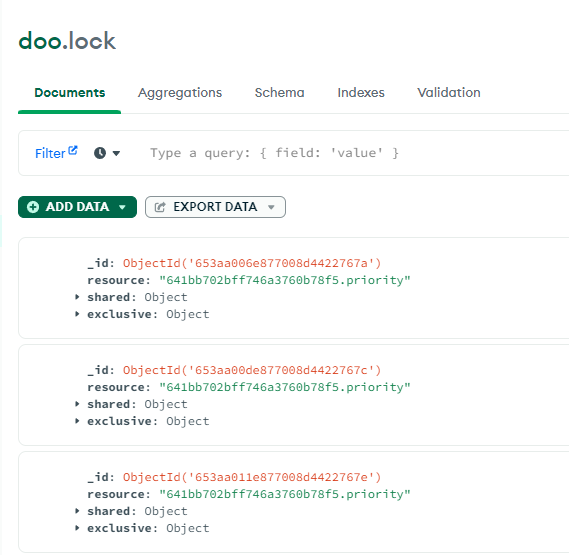 이게 원인이라면 문제가 설명이 됐다. Lock을 기반으로 각 주제에 대해서 이벤트가 한번만 순서대로 실행됨을 보장하는데, Lock이 중복으로 생성된다면 충분히 consumer 프로세스도 중복으로 생성되어서 꼬일 가능성이 있었기 떄문이었다.
이게 원인이라면 문제가 설명이 됐다. Lock을 기반으로 각 주제에 대해서 이벤트가 한번만 순서대로 실행됨을 보장하는데, Lock이 중복으로 생성된다면 충분히 consumer 프로세스도 중복으로 생성되어서 꼬일 가능성이 있었기 떄문이었다.
그리고 Lock이 왜 중복으로 생성되었는지를 보았는데...? 알고보니 "주제" 필드에 대해서 unique 제약이 삭제되어있었던 것이다.
원래 "주제" 단위로 unique 키를 걸어놔야 DB의 신뢰성을 기반으로 엄격한 배타성을 보장할 수 있는 것인데, 그게 어떠한 역사적 이유로 production 환경에서만 "원래 있었다가" 삭제가 되어있었다.
그래서 부하가 몰릴 때만 동시에 write가 발생해서 Lock이 중복 생성되고, qa 스테이지 등에서는 버그 재현이 되지 않았던 것이다.
저걸 풀고 하니까 똑같이 버그 상황이 재현되더라.
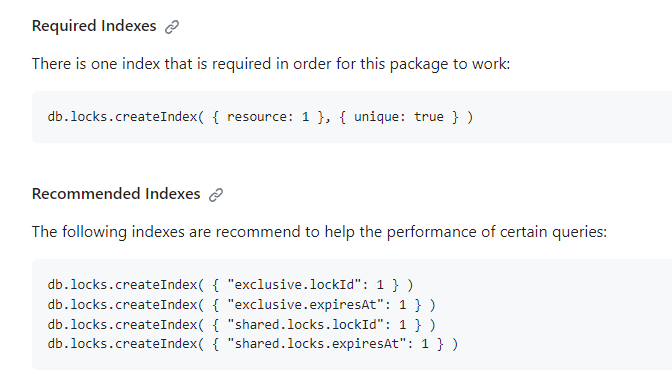
8. 해결
lock 라이브러리에서 요구하는 대로, unique-index 제약사항을 다시 맞춰주는 것으로 해결이 되었다.
9. 결론
여러모로 DB 관리에 소홀해서 생긴 문제였다.
스테이지별 데이터 구조는 항상 잘 맞춰주자...