[MongoDB] 쓰기 지연 문제
MongoDB를 클러스터 모드로 쓸 때에는, 다른 분산시스템들과 마찬가지로 복제 지연이 발생한다.
필연적인 문제다.
MongoDB 클러스터는 일반적인 Single Master - Multi Slave의 구조를 가진다.
쓰기가 발생하면 master가 쓰기를 받아서 나머지 노드에 데이터를 동기화한다.
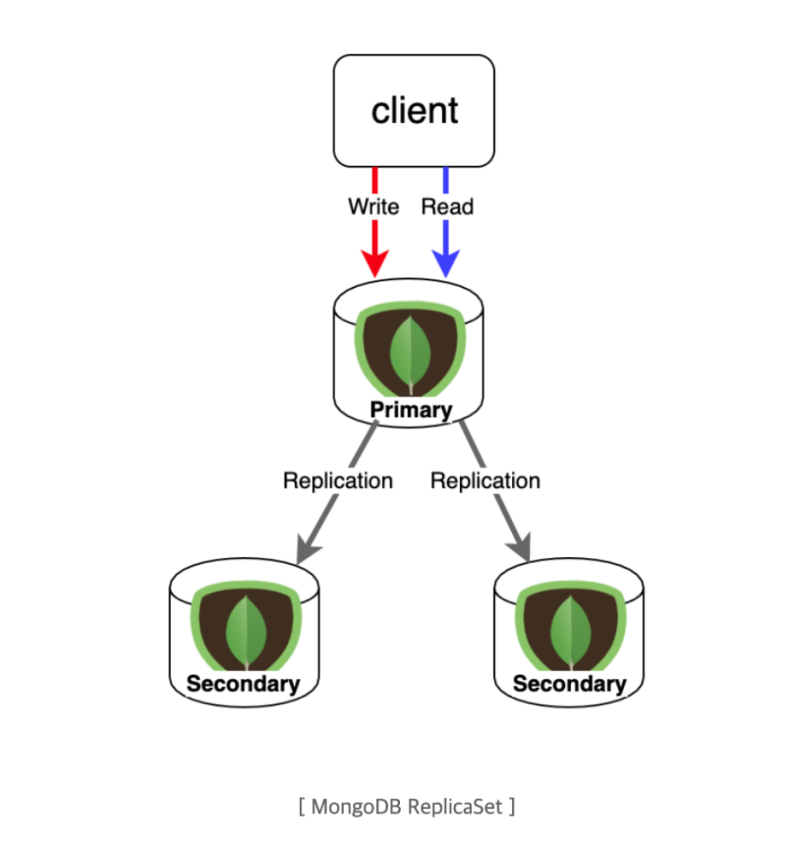 그런데 당연히 이런 동기화에는 반드시 지연 시간이 존재하고, 이 지연은 네트워크나 기타 상황에 따라 마이크로초에서 밀리초, 혹은 초 단위까지도 걸릴 수 있다.
그런데 당연히 이런 동기화에는 반드시 지연 시간이 존재하고, 이 지연은 네트워크나 기타 상황에 따라 마이크로초에서 밀리초, 혹은 초 단위까지도 걸릴 수 있다.
그래서 그냥 이렇게 코드를 짜면
store.CreateSomeData({
ID: "1234"
}) // 삽입 성공
store.FindByID("1234") // 하지만 조회되지 않음..이런 어이없는 상황이 벌어질 수가 있다.
일반적으로 정상적인 언어들에서 각 코드 인스트럭션은 아무리 느려도 나노초 단위로 실행되기 때문에, 쓰고 나서 바로 읽더라도 그 쓰기가 반영되지 않은 노드에서 데이터를 읽어올 수 있는 것이다.
쓰기 고려(Write Concern)
이런 현상에 대응하는 방법 중 하나는 Write Concern을 사용하는 것이다.
이건 쓰기 작업의 완료 기준을 정하는 설정이다.
아래 커맨드를 날리면 Write Concern 설정을 조회할 수 있는데
db.adminCommand(
{
getDefaultRWConcern: 1 ,
}
)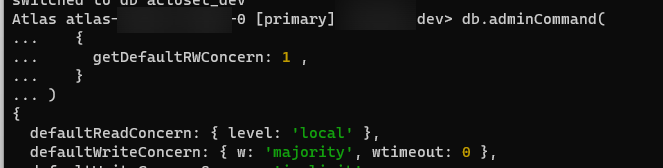 어지간해서 기본 설정은 majority다.
어지간해서 기본 설정은 majority다.
저건 노드 중 과반수에 복제가 완료되면 쓰기 작업이 "끝났다"고 판단하겠다는 것이다.
그래서 노드가 3개인 일반적인 상황에서는, 노드 2개에만 데이터가 동기화돼도 쓰기가 끝났다고 판단해서 오퍼레이션을 끝낸다. 문제는 노드 1개에 동기화되지 않은 찰나의 순간에 코드가 그 노드에서 읽기를 수행할 수 있는 것이다.
완벽하게 쓰기가 완료되게끔 기다리게 하려면, writeConcern 설정을 노드 최대 개수와 맞춰야 한다.
아래와 같이 디폴트 설정을 덮어씌울 수도 있고,
db.adminCommand({
"setDefaultRWConcern": 1,
"defaultWriteConcern": { w: 3 },
})커넥션을 생성할때, 혹은 command를 날릴때 지정해서 날릴 수도 있다.
그러면 해당 개수만큼 복제가 완료될때서야 write operation이 끝났다고 판정하기 때문에, 쓰기 후-바로 읽는 작업에서의 부작용은 제거할 수 있다.
참조
https://velog.io/@euholee/mongodb-read-preference-%EC%84%A4%EC%A0%95
https://www.mongodb.com/docs/manual/reference/write-concern/#std-label-wc-w
https://dlaudtjr03.tistory.com/17
https://bluese05.tistory.com/74
https://www.mongodb.com/docs/manual/core/causal-consistency-read-write-concerns/
https://www.mongodb.com/docs/manual/core/read-isolation-consistency-recency/#std-label-sessions