벡터 데이터베이스
벡터 데이터베이스는 근래들어 부상하고 있는 데이터베이스의 한 갈래다.
벡터는 수학적인 의미의 벡터가 맞다.
비교적 크기가 큰 이미지, 비디오 등의 미디어파일에 대해서 유사도 검색을 수행하는 것에 최적화되어있다.
사용사례에 있어서는 AI와 관련이 깊다. 사실 구조상 AI가 없는 일반적인 애플리케이션에는 사용할 이유가 딱히 없다.
기본 원리
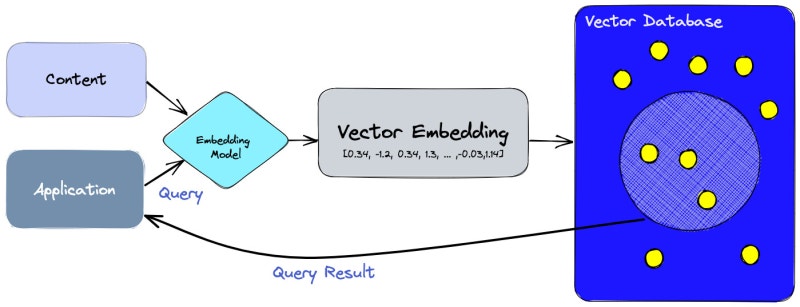 https://discuss.pytorch.kr/t/gn-vector-database/1516
https://discuss.pytorch.kr/t/gn-vector-database/1516
AI 시스템들에서는 보통 "벡터 임베딩"이란 형태로 데이터를 가공해서 보관할 때가 많다. 자연어가 되었든, 이미지가 되었든 다 그렇다.
ML이라도 일단 뭔가 연산의 결과를 저장하긴 해야하니, 그걸 벡터 형태로 관리하는 것이다.
그리고 실제 ML 사용례에서는 그 벡터 데이터를 기반으로 비슷한 벡터 데이터를 찾아서 유사한 데이터셋을 찾는 작업을 자주 한다.
벡터 데이터베이스는 이러한 벡터 데이터를 효율적으로 저장하고 검색할 수 있게 해주는 DB들을 말한다.
유사도 검색은 N차원 벡터에 대해서 모두 수행할 수 있어야 하기 때문에 복잡한 수학적 원리들이 많이도 응용된다.
유클리드 거리나, 코사인 유사성, 내적 등...
구현체
아예 벡터 전용으로 나온 Pinecoin 같은 녀석도 있고, 카산드라DB, MongoDB, Elasticsearch 등의 DB들도 이러한 저장형태를 지원한다.
참조
https://aws.amazon.com/ko/what-is/vector-databases/
https://en.m.wikipedia.org/wiki/Vector_database
https://velog.io/@tura/vector-databases
https://news.hada.io/topic?id=9147