[LLM] Ollama로 오픈소스 LLM 사용해보기
 Ollama는 LLM 모델들을 편리한 UI로 간편하게 사용해줄 수 있게 해주는 오픈소스 시스템 및 모델 허브, 종합 환경이다.
Ollama는 LLM 모델들을 편리한 UI로 간편하게 사용해줄 수 있게 해주는 오픈소스 시스템 및 모델 허브, 종합 환경이다.
ChatGPT같은 폐쇄형 모델은 안되고, LLAMA나 Mistral 같은 오픈소스 모델들만 사용할 수 있다.
설치
Mac, Linux, Windows에서 모두 사용할 수 있다. Windows는 WSL2을 사용해야 한다.
난 리눅스에서 했다. 리눅스의 경우 설치 자체는 매우 간단하다.
curl -fsSL https://ollama.com/install.sh | sh
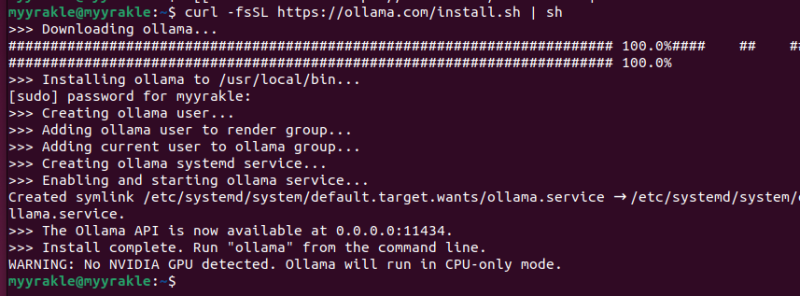 엔비디아 그래픽이 없다면 CPU 모드로만 동작한다. 나는 빈한한 코더이므로 CPU로만 돌리겠다.
엔비디아 그래픽이 없다면 CPU 모드로만 동작한다. 나는 빈한한 코더이므로 CPU로만 돌리겠다.
그래서 이렇게 CLI가 실행되면 설치 자체는 잘 된 것이다.
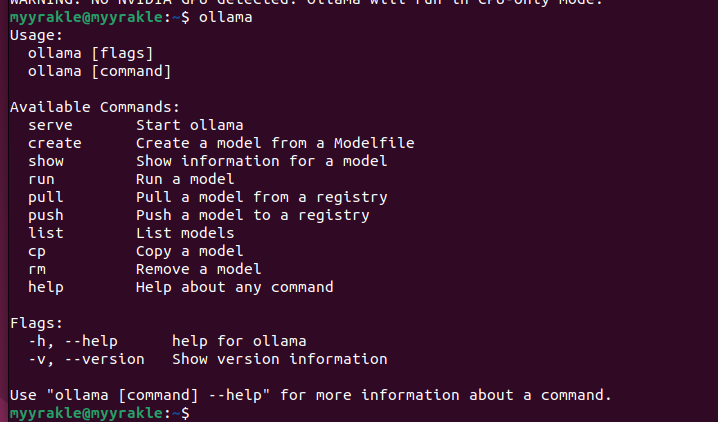
모델 다운받기
어지간한 유명 모델들은 다 자체적인 허브로 다운로드할 수 있게 제공해주고 있다.
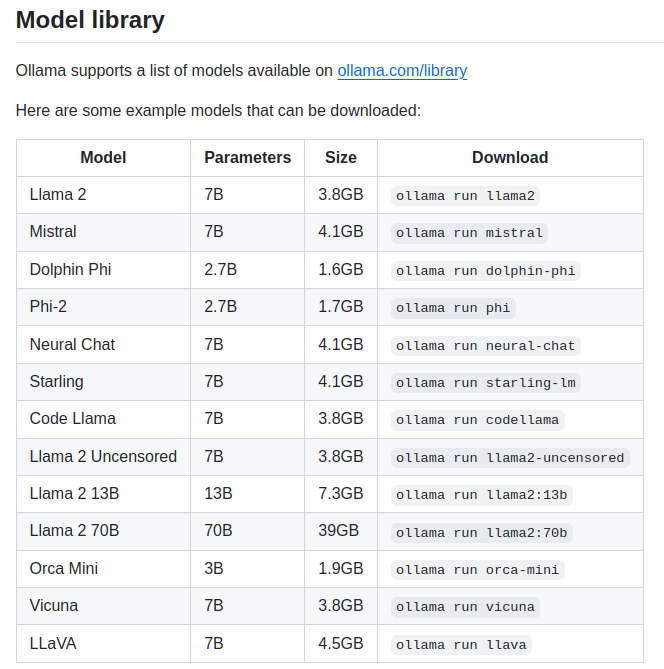
전체 목록은 다음 페이지에서 확인할 수 있다.
https://ollama.com/library
모델을 다운받으려면 pull 명령을 사용하면 된다. 나는 mistral을 다운받았다.
ollama pull 모델명 기가단위의 파일을 받는것치곤 꽤 빠르게 다운이 된다.
기가단위의 파일을 받는것치곤 꽤 빠르게 다운이 된다.
 설치가 되면 언제든 실행을 할 수 있는 상태가 되고, list로 조회를 할 수 있다.
설치가 되면 언제든 실행을 할 수 있는 상태가 되고, list로 조회를 할 수 있다.
CLI로 모델 사용해보기
run 명령을 사용하면 바로 모델을 시작해서 채팅 모드에 진입할 수 있다.

 인터랙티브하게 대화를 보내고
인터랙티브하게 대화를 보내고

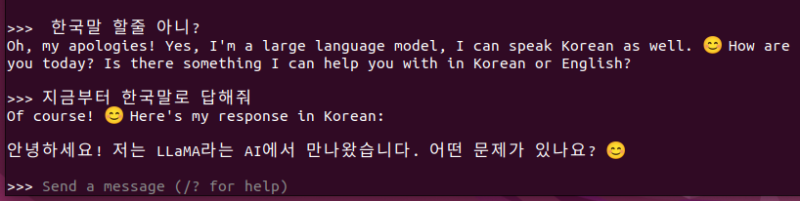 대답을 받을 수 있다.
대답을 받을 수 있다.
나가려면 컨트롤+d를 치면 된다.

Rest API로 사용하기
근데 실제로 저걸 사용하려면 저게 아니라 뭔가 정형화된 형태로 호출을 할 수 있어야 한다.
그래서 ollama는 rest api를 제공한다.
generate는 가장 기본적인 형태의 생성 방법이다.
모델과 텍스트를 넘기면 거기에 대한 대답을 준다.
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "Hello?",
}'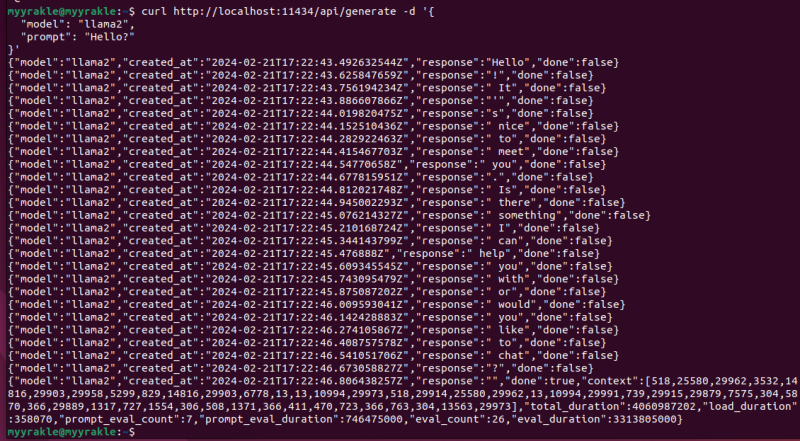 근데 옵션 없이 그냥 보내면 스트리밍 형태로 응답을 줘서 읽기가 어렵다.
근데 옵션 없이 그냥 보내면 스트리밍 형태로 응답을 줘서 읽기가 어렵다.
stream: false 옵션을 주면 성능은 조금 떨어지지만, 좀더 편하게 볼 수 있다.
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "Hello?",
"stream": false
}'
근데 저 generate는 뭔가 컨텍스트 유지가 안되기 때문에 그럴듯한 채팅을 만드는 데는 쓰기가 어렵다.
그러려면 chat API를 사용해야 한다. 이건 알아서 대화를 기억해주는건 아니고, 메세지를 직접 append-only로 관리하다가 계속 모아서 보내는 형태로 사용해야 한다.
curl http://localhost:11434/api/chat -d '{
"model": "llama2",
"stream": false,
"messages": [
{
"role": "user",
"content": "안녕?"
}
]
}'
curl http://localhost:11434/api/chat -d '{
"model": "llama2",
"stream": false,
"messages": [
{
"role": "user",
"content": "안녕?"
},
{
"role": "user",
"content": "내가 방금 뭐라고 말했지?"
}
]
}'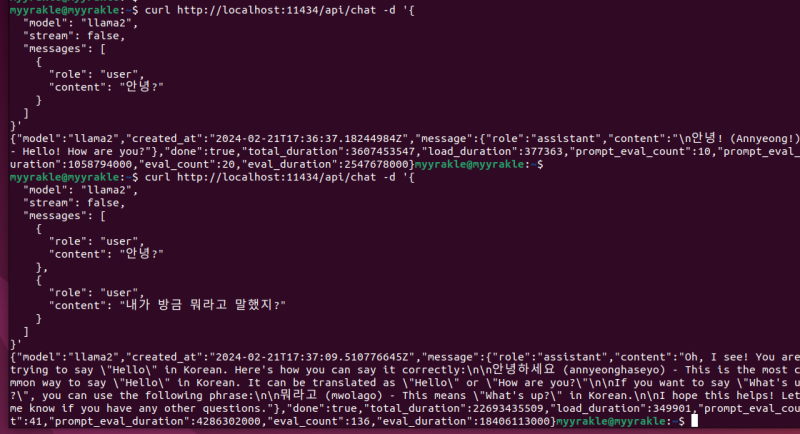
그렇다.
API에 대한 전체 명세는 다음 링크를 참고한다.
https://github.com/ollama/ollama/blob/main/docs/api.md