[Rust] 문자열: 인코딩
Rust에서 문자열 인코딩을 처리하는 방법을 정리한다.
기본 인코딩
Rust 코드에서 적용되는 기본 인코딩은 UTF-8이다.
문자열 리터럴로 넣은 문자열은 전부 UTF-8로 인코딩되고, String과 &str 타입 모두 UTF-8로 문자열을 관리한다.
pub fn main() {
let some_text = "Hello, world!";
println!("{}", some_text);
let koean_text = "안녕하세요!";
println!("{}", koean_text);
let emoji_text = "👋🌍";
println!("{}", emoji_text);
}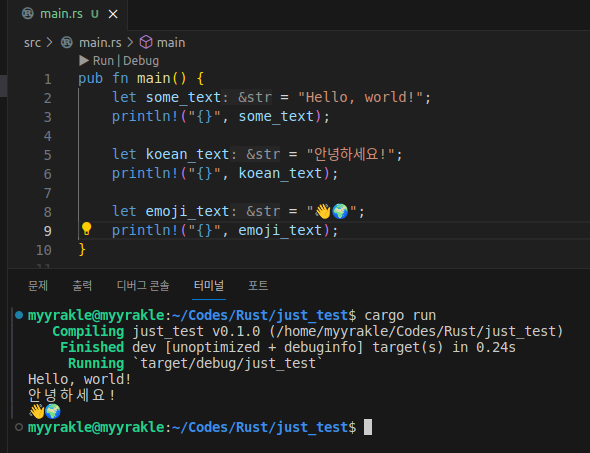 그렇기 때문에 모든 유니코드 대역을 표현할 수 있다.
그렇기 때문에 모든 유니코드 대역을 표현할 수 있다.
하지만 단점도 있다. 가변길이로 저장되다보니 바로 문자의 길이를 가져오거나, 문자 단위 처리를 하는 것이 불편하다는 것이다.
그래서 다음과 같이 길이를 측정해도
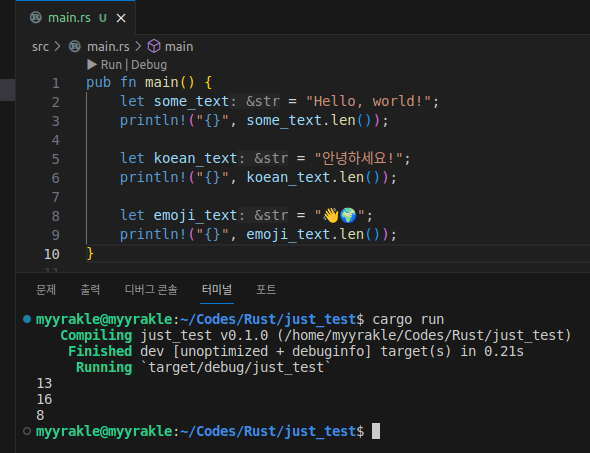 기대한 것과 다르게 나온다.
기대한 것과 다르게 나온다.
한글은 3바이트를 차지하기 때문에 6글자임에도 5*3+1=15가 나왔고, 이모지는 하나당 4바이트라서 8이 나왔다.
문자열을 문자 단위로 처리하고 싶다면, char 배열 타입으로 전환해서 다뤄야 한다.
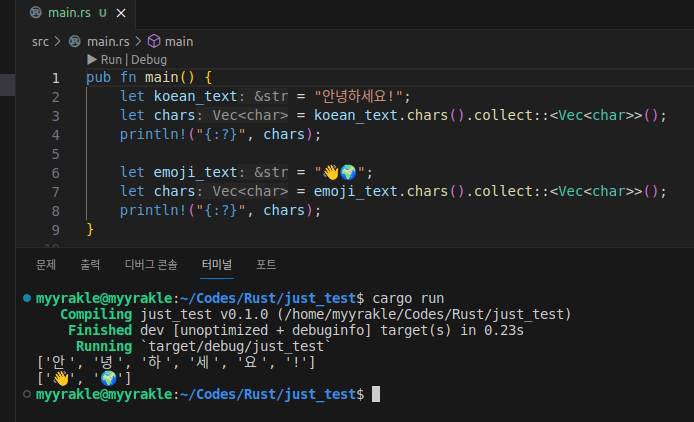 이런 느낌이다.
이런 느낌이다.
OS 종속 인코딩 처리: OsString
근데 항상 UTF-8로만 일관되게 다룰 수 있으면 참 좋겠지만, 세상일이 그렇게 흘러가지는 않는다.
특히 운영체제 수준에서는 이상한 인코딩을 쓰는 경우가 많기 때문에 더 그렇다.
Linux는 기본 인코딩으로 UTF-8을 사용하지만 기타 유닉스 계열이나 Windows는 그렇지 않다.
Windows는 기본적으로 UTF-16이나 EUC-KR 같은 2바이트 단위 인코딩을 즐겨쓴다.
그래서 뭔가 운영체제 정보에서 뭔가를 꺼내오거나, C 함수를 FFI로 사용하거나 할 때는 그 인코딩과 상호작용을 해야할 필요가 있는데, 그럴대 쓰는게 OsString 타입이다.
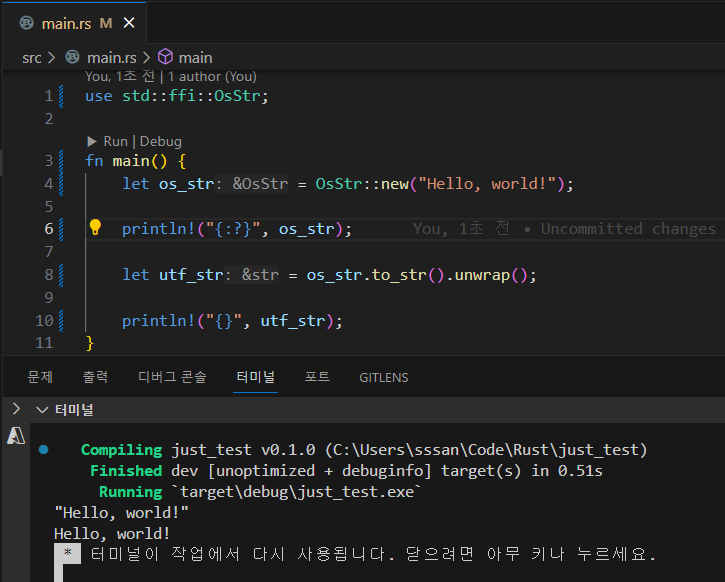 이건 약간 일종의 어댑터로서 사용하고, to_str 같은 함수를 사용해서 기본 문자열 타입으로 캐스팅해서 사용하는 것이 일반적인 방법이다.
이건 약간 일종의 어댑터로서 사용하고, to_str 같은 함수를 사용해서 기본 문자열 타입으로 캐스팅해서 사용하는 것이 일반적인 방법이다.
사용할 일이 아주 많지는 않다.
UTF-16 인코딩 변환
여러가지 기능적 요구사항에 부닥치다 보면 당연히 특정 인코딩으로 문자열을 처리해야할 경우도 빈번하다.
다행히 UTF-16에 한해서는 std에서 인코딩 기능을 제공한다.
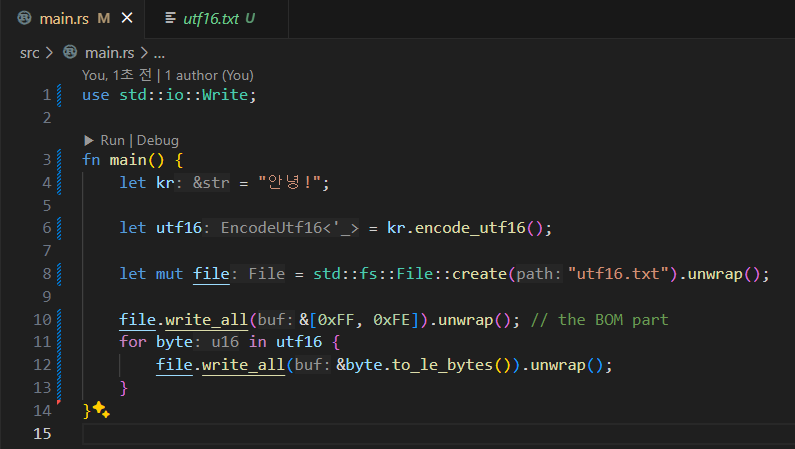
아래는 기본 문자열을 UTF16로 변환해서 리틀 엔디언으로 저장하는 예시다.

UTF-32 인코딩 변환
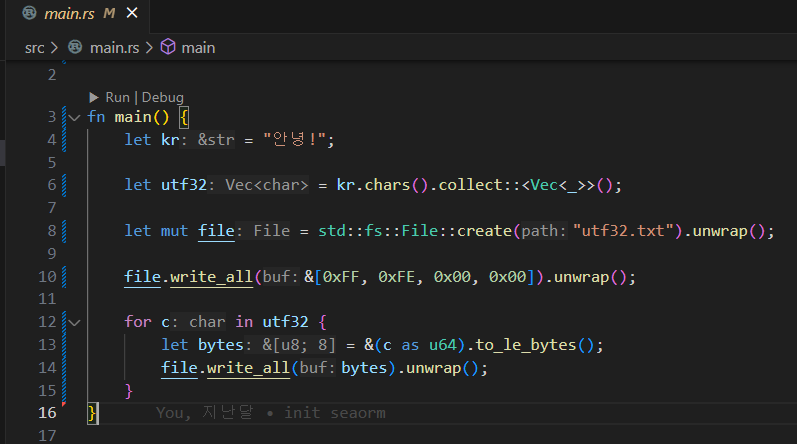
Rust는 UTF-32 인코딩 변환을 명시적으로 제공하지는 않지만, char 타입 자체가 UTF-32에 근사하므로 그리 어렵지 않게 변환을 시도해볼 수 있다.
이것도 그냥 바이트열로 바꿔서 때려넣으면 된다.
 근데 UTF-32를 지원하는 뷰어가 별로 없어서 확인해보긴 매우 어려울 것이다.
근데 UTF-32를 지원하는 뷰어가 별로 없어서 확인해보긴 매우 어려울 것이다.
사용사례가 거의 없어서 그런거같다.
기타 인코딩 변환
나머지 인코딩 변환들을 수행하려면 서드파티 crate들을 사용해야 한다.
이게 좀 쓸만한 편인 것 같다.
https://docs.rs/encoding_rs/latest/encoding_rs/index.html
참조
https://doc.rust-lang.org/std/string/struct.String.html
https://doc.rust-lang.org/std/ffi/struct.OsString.html
https://doc.rust-lang.org/book/ch08-02-strings.html