캐시라인 최적화와 배열
캐시라인 최적화는 CPU 캐시가 캐싱을 잘 하도록 유도하는 최적화 유도 기법이다.
캐시는 생각보다 성능에 지대한 영향을 주는 변인 중 하나다.
최적화를 논할때 수학적 알고리즘을 이야기하곤 하지만, 결국 모든 코드는 하드웨어에서 돌아간다.
시간복잡도니 뭐니 하는 것도 실제 하드웨어에 올라가면 맞지 않을 때가 많다.
이를테면 정렬 알고리즘 중 quick sort가 알고리즘적으로는 N log N ~ N^2 정도의 성능을 보여야 하지만, 다른 대부분의 정렬 알고리즘을 압도하는 실성능을 보이는 것도 캐시 최적화를 굉장히 잘 타기 때문이다.
캐시 참조는 대략 1-10ns 정도의 시간이 소모되는 반면 메인메모리 참조는 100ns 정도가 소요된다. 최소 10배 정도는 차이가 나는 것이다.
캐시와 캐시라인
캐시는 약간 변칙적인 방법에 의거해서 데이터를 가져온다.
- 자주 사용되는 값은 당연히 1순위로 캐시에 로드한다.
- 가져온 데이터에 주변에 있는 값도 캐시에 로드한다. 이를 지역성(locality)라고 한다.
그리고 캐시 메모리에서 각각의 캐시 묶음이 저장되는 영역을 캐시라인이라고 부른다.
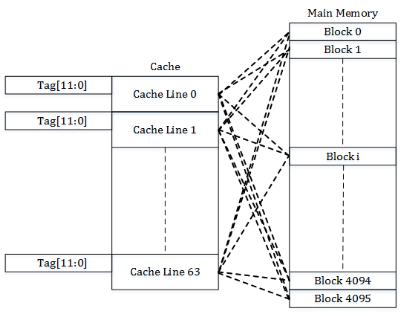 https://en.algorithmica.org/hpc/cpu-cache/associativity/
https://en.algorithmica.org/hpc/cpu-cache/associativity/
캐시 매커니즘은 현대에 와서는 굉장히 복잡해졌기 때문에, 간단히만 다루고 넘어간다.
여기서 이야기하고 싶은건 지역성이다.
예를 들어 CPU는 1004번 주소의 메모리 값을 사용했다면, 근처에 있는 1005, 1006, 1007번에 있는 메모리 값도 곧 사용할 것이라고 추측하고 한번에 캐시에 로드할 수 있다.
그렇기 때문에 메모리에 가까이 위치한 변수에 접근하는 것은 캐시를 잘 탄다.
배열과 캐시
배열은 항상 메모리 연속적으로 데이터가 저장된다.
그렇기 때문에 locality에 의한 캐시 최적화가 굉장히 잘 되는데, 리스트니 해시테이블이니 뭐니 해도 대부분의 경우 배열이 가장 가볍고 빠른 이유가 이것이다.
그래서 극적인 수준의 최적화가 필요하다면 배열을 사용하는 것이 최우선순위가 되어야 한다. 정적으로 스택에 할당된 배열인지, 동적으로 힙에 할당된 배열인지는 상관이 없다.
배열의 연속적 접근
배열만 쓴다고 해서 무조건 캐시 최적화가 잘 되는건 아니다.
결국에는 locality가 중요한 것이기 때문에, 순서대로 접근하거나 계속 근처 가까운 곳에 접근을 해야 한다.
7 인덱스에 액세스했다가, 544에 액세스했다가 하는 널뛰기식 접근으로는 캐시 최적화가 제대로 이루어지지 않는다.
아래는 그런 캐시 효율성의 차이를 극적으로 보여줄 수 있는 예시 코드다. 언어는 Rust다.
pub struct Timer {
start: std::time::Instant,
}
impl Timer {
pub fn new() -> Timer {
Timer {
start: std::time::Instant::now(),
}
}
pub fn elapsed(&self) -> std::time::Duration {
self.start.elapsed()
}
pub fn elapsed_as_millis(&self) -> u128 {
self.elapsed().as_millis()
}
pub fn elapsed_as_secs(&self) -> u64 {
self.elapsed().as_secs()
}
}
const ARRAY_SIZE: usize = 10_000_000;
fn do_something_with_indices(array: &Vec<i32>, indices: &Vec<usize>) -> i64 {
let mut sum = 0;
for i in indices {
let value = array[*i];
sum += value as i64;
}
sum
}
fn get_randome_indices() -> Vec<usize> {
use rand::seq::SliceRandom;
let mut indices = (0..ARRAY_SIZE).collect::<Vec<usize>>();
let mut rng = rand::thread_rng();
indices.shuffle(&mut rng);
indices
}
fn get_sequencial_indices() -> Vec<usize> {
(0..ARRAY_SIZE).collect::<Vec<usize>>()
}
fn main() {
let mut array = vec![0; ARRAY_SIZE];
for i in 0..ARRAY_SIZE {
array[i] = i as i32;
}
println!("Array Size: {}", ARRAY_SIZE);
let indices = get_sequencial_indices();
let timer = Timer::new();
do_something_with_indices(&array, &indices);
println!("Seq Access => Elapsed: {}ms", timer.elapsed_as_millis());
let indices = get_randome_indices();
let timer = Timer::new();
do_something_with_indices(&array, &indices);
println!("Randome Access => Elapsed: {}ms", timer.elapsed_as_millis());
}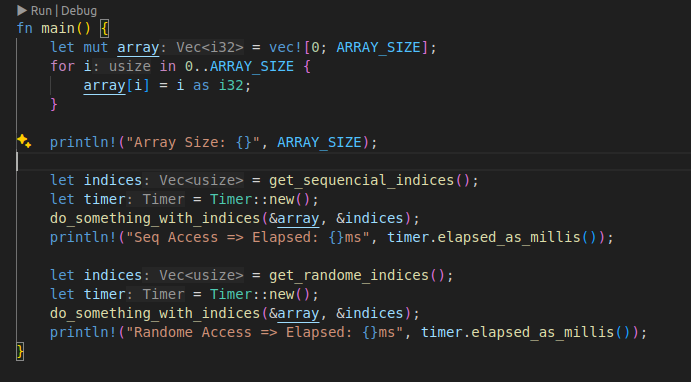 인덱스 배열을 받아서 하나의 함수는 배열을 순서대로 조회해서 합산하고, 하나의 함수는 배열을 랜덤으로 조회해서 합산한다. 차이는 그것 뿐이다.
인덱스 배열을 받아서 하나의 함수는 배열을 순서대로 조회해서 합산하고, 하나의 함수는 배열을 랜덤으로 조회해서 합산한다. 차이는 그것 뿐이다.
후자의 경우는 변화무쌍하게 메모리 접근을 시도하니 당연히 메모리 액세스에 캐시 미스만 주구장창 뜰 것이다.
하지만 그것만 해도 꽤 큰 성능 차이가 발생한다.
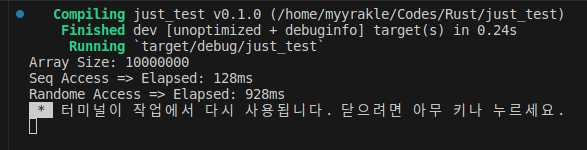 1000만번을 반복했을 경우 8배 정도의 성능차이를 보였고
1000만번을 반복했을 경우 8배 정도의 성능차이를 보였고
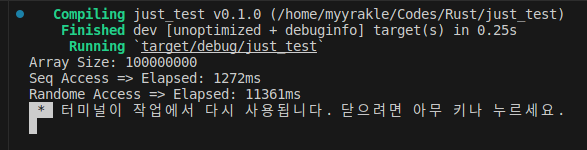 1억번을 반복했을 경우 9-10배의 성능차이를 보였다.
1억번을 반복했을 경우 9-10배의 성능차이를 보였다.