로깅과 모니터링
서버 개발자로서의 경험을 가지고 있다면 개발만큼이나 중요한게 운영능력이란 것을 체감하고 있을 것이다.
문제 추적과 해결에 필요한 로깅과 모니터링 매커니즘, 환경들을 대략 정리해본다.
A. 로깅(Logging)
문제 추적 방식에는 여러가지 수단이 있지만, 아무래도 그 중 가장 대표적인 것은 로그일 것이다.
가장 원초적이고 단순하지만, 또 효과적으로 관리하기 어려운 수단이라고 할 수 있다.
1. 로깅의 기본 형태
로그는 뭐 어떻게 쓴다고 뭐라고 하는건 없지만, 기본적으로 권장되는 형태는 존재한다.
아래는 그에 대한 간단한 예시다.
 로그 포맷은 json을 사용했다. 요즘은 로그 자체를 json 기반으로 write하는게 약간 기본 옵션이 되었다.
로그 포맷은 json을 사용했다. 요즘은 로그 자체를 json 기반으로 write하는게 약간 기본 옵션이 되었다.
그리고 level을 통해서 로그의 수준을 명시한다.
관례적으로 debug, info, warn, error, fatal 5개 정도를 사용한다.
 https://fiberplane.com/blog/the-four-levels-of-log-collections
https://fiberplane.com/blog/the-four-levels-of-log-collections
이를 통해 심각도에 따라서 필터해서 볼 수 있도록 하는 것이다.
그 외에는 필요한대로 팀 차원에서 합의를 보고 정해서 사용하면 된다.
로그 기반의 강력한 추적
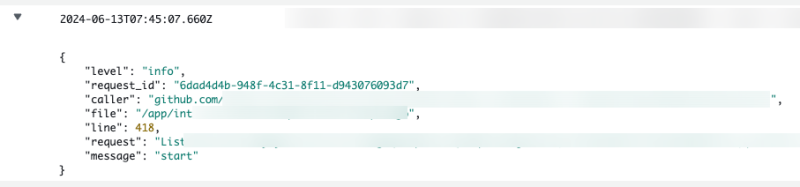 나는 로그를 찍을때 request_id라는 로그 필드를 사용했는데, 이름은 뭐든 상관 없지만 특정 기능 흐름을 하나로 묶어주는 로그 그룹 식별자가 필요하다.
나는 로그를 찍을때 request_id라는 로그 필드를 사용했는데, 이름은 뭐든 상관 없지만 특정 기능 흐름을 하나로 묶어주는 로그 그룹 식별자가 필요하다.
그냥 생각없이 싸지르다보면, 로그가 잔뜩 쌓여있더라도 이게 뭐 하다 난 로그인지, 어떤 호출에서 발생한 로그인지를 식별할 수가 없기 때문이다.
내 경우에는 API 호출마다 request_id라는 식별자를 context 단위로 유지하고, 그걸 상속받으면서 항상 로그에 기록하도록 했다. 그러면 일단 해당 흐름 단위의 로그는 필터링을 통해 한눈에 볼 수 있다.
그리고 이걸 매끄럽게 잘 연결하면, 오류 메세지나 요청/응답 로그를 통해서 역추적을 손쉽게 할 수 있다.
내 경우에는 APM에 Error를 던질 때도 request_id를 함께 던지게 만들고,
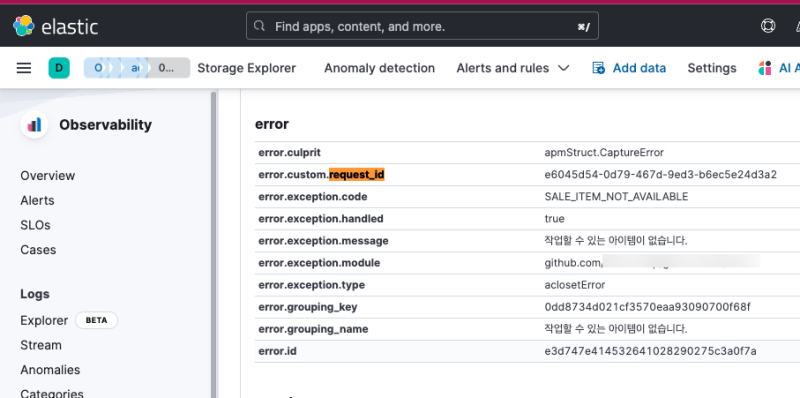
Error가 발생하면 catch해서 Slack으로 날아오게 만들었다.
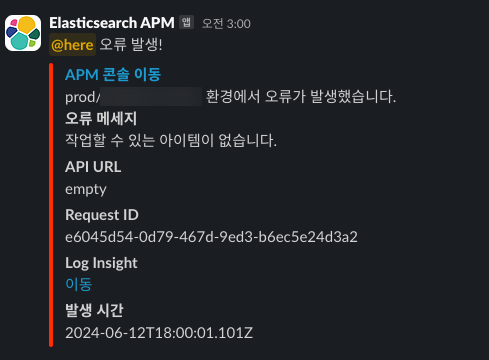 그러면 저기서 다시 APM으로 이동해서 해당 컨텍스트의 메타데이터를 조회할 수 있고
그러면 저기서 다시 APM으로 이동해서 해당 컨텍스트의 메타데이터를 조회할 수 있고
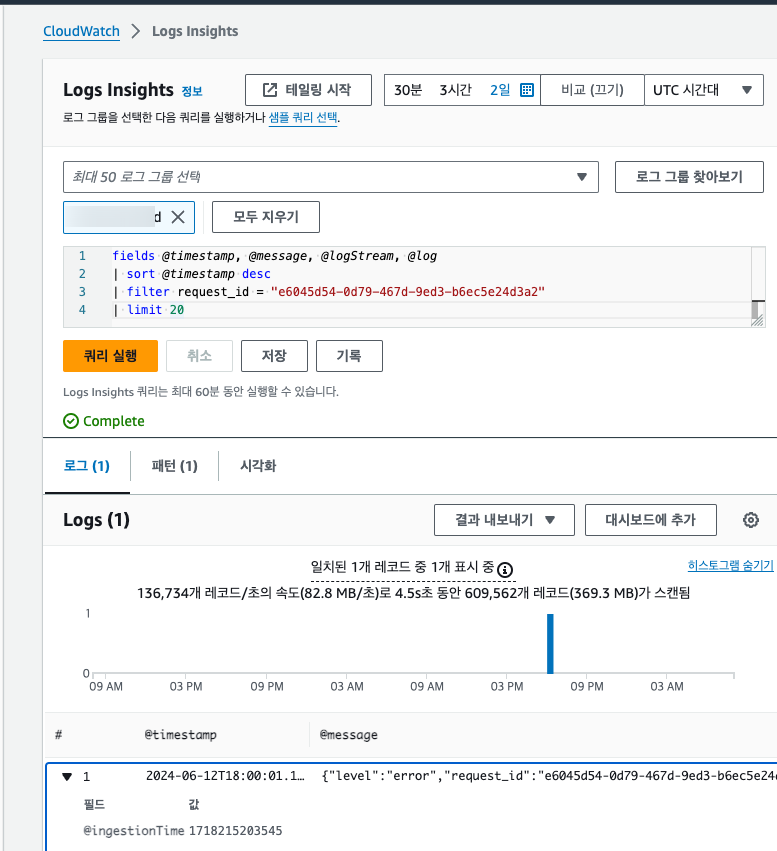 로그 검색 페이지로 이동해서 조회할 수 있다.
로그 검색 페이지로 이동해서 조회할 수 있다.
로그 저장소
정보성 로그, 혹은 디버그, 오류 수준의 로그를 표준 출력으로 write하면, 별도의 구성을 통해서 로그 저장소에 저장하도록 하는 것이 기본이다.
여기서 로그 저장소는 비용이나 제반사항에 따라서 천차만별일 수 있다.
**1. **로컬 파일 저장
가장 구시대적인 방법은 로그를 그냥 서버 위치에 바로 저장하는 것이다. 비용적으로 저렴하고 일단 생각없이 쌓기는 좋지만, 디스크 사이즈를 관리하는 것이 어렵고, 로그를 검색하는 것도 불편하다.
컨테이너 기반 서버로 가거나 스케일아웃된 환경에서 이런 방식을 고수하면 지옥을 맛볼 수 있다.
2. 클라우드 저장소 사용
AWS 같은 클라우드를 사용한다면 클라우드에서 제공하는 로그 저장소를 사용하는 것이 거의 강제가 된다.
ec2나 eks 기반으로 한다면 직접 제어가 가능하지만, fargate나 lambda 기반 리소스는 모든 로그가 자동으로 Cloudwatch에 기록된다.
AWS Cloudwatch의 경우 데이터 압축도 빡세게 해주고 온디맨드라 관리는 매우 편리하지만, 가격이 조금 나간다.
로그를 무지성으로 쌓다보면 치솟는 비용을 볼 수 있을 것이다.
3. 오픈소스 로깅 저장소 시스템
로그 저장용으로 사용되는 DB 같은 시스템들이 몇가지 있다.
Elasticsearch가 그 대표주자 중 하나였다. 흔히 말하는 ELK 스택에서는 Logstash로 로그를 긁어다 Elasticsearch에 저장하는 방식을 취한다.
Elasticsearch 자체가 좀 무거운 녀석이다보니, 검색은 빠르겠지만 비용 효율적이지 않을 수는 있다.
Grafana Loki는 로깅 전용 스택이다.
일반 환경에서도 사용할 수 있고, k8s 환경에서의 지원도 상당히 좋다.
Elasticsearch에 비하면 디스크도 적게 먹고, 리소스를 전반적으로 덜 먹는다. 대신 검색 성능은 조금 떨어질 수 있다.
4. k8s?
그럼 쿠버네티스 스택에서는 어떤 식으로 로그를 중앙화해서 저장하고 관리할까?
그냥 로그를 무지성으로 쌓다보면 파드별로 로그를 싸기만 하고 관리가 되지 않는다.
그래서 별도의 데몬을 돌려서 로그를 재수집, 저장하는 방식을 취한다. 이런 용도로 사용하는 대표적인 수집용 도구가 Fluentbit다. 저장소와는 별개다.
Grafana Loki도 이러한 자동 수집을 지원힌다.
B. Error reporting 시스템
error tracking이라고도 부른다.
로그를 쌓는 것도 중요하지만, 오류가 발생했을때 오류를 기록하고 운영자에게 알려주는 것도 중요하다.
일반적인 로깅으로도 오류 관리를 못하는건 아니지만, error reporting 시스템들은 좀더 특화되고 편리한 형태로 오류를 핸들링해주는 부분들이 있어서 많이들 쓴다.
일반적인 오류 보고 및 저장 시스템들은 대략 다음과 같은 구조를 가지고 있다.
-
오류가 발생한 함수의 호출 trace를 자동으로 저장해준다.(Client SDK 수준 지원)
-
오류가 발생한 환경의 요청 IP 브라우저 정보 같은 부가적인 정보들도 자동으로 저장해준다.(Client SDK 수준 지원)
-
같은 오류를 묶어줄 수 있는 기능을 갖고 있다.
-
오류 그룹에 대해서 오류가 해결되었는지 아닌지를 상태로 관리할 수 있다. (없을수도)
-
오류가 발생할 때 Slack 같은 메신저로 바로 보내주는 연동 기능을 제공한다. (없을수도)
아래 예시는 Elastic APM에서 제공하는 오류 관리 시스템이다.
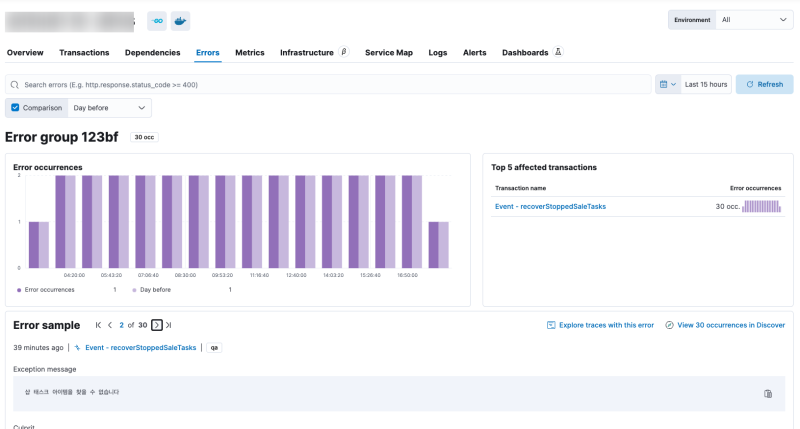 이런식으로 오류를 볼 수 있는데
이런식으로 오류를 볼 수 있는데
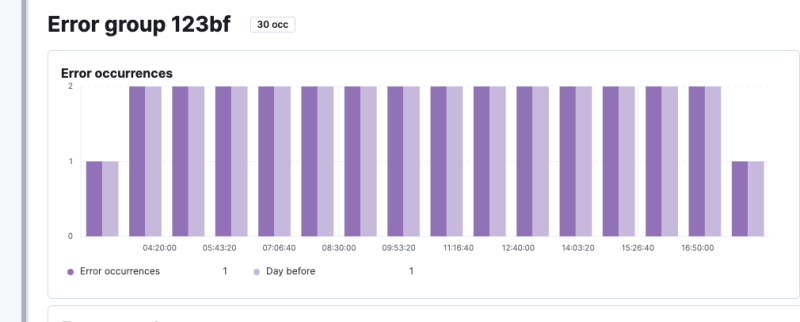 이렇게 오류 관련된 통계도 있고
이렇게 오류 관련된 통계도 있고
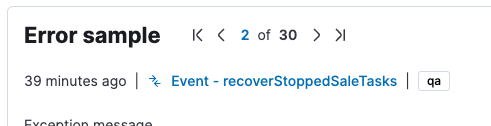 같은 오류를 묶어서 보여주기도 하고
같은 오류를 묶어서 보여주기도 하고
 오류 발생 지점의 스택트레이스와 메타데이터를 확인할 수도 있다.
오류 발생 지점의 스택트레이스와 메타데이터를 확인할 수도 있다.
이런 느낌이다.
1. 오픈소스 시스템
오픈소스 중에서 가장 대표적인 오류 관리 시스템은 아무래도 sentry가 있다.
오류 처리에 특화되어있고, 관련된 편의기능들을 잘 지원한다.
원한다면 sentry 그룹에서 직접 호스팅하는 클라우드 서비스를 사용할 수도 있다.
Elasticsearch APM으로 구성할 수도 있다. sentry에 비하면 조금 부족한 느낌이 있긴 있다.
2. 유료 서비스
유료 서비스로 대표적인 것은 역시 Datadog이 있다.
이외에도 Rollbar, Bugsnag 꽤 많은데, 안써봐서 모르겠다.
C. Resource Metric
서버를 안정적으로 운영하기 위해서는 실제 서버가 리소스를 얼마나 점유하고, 얼마나 여유가 있는지를 확인하는 것이 중요하다.
그 중 대표적인 지표는 바로 CPU 사용량과 Memory(RAM) 사용량이다.
아래 예시는 Elasticsearch APM이다.
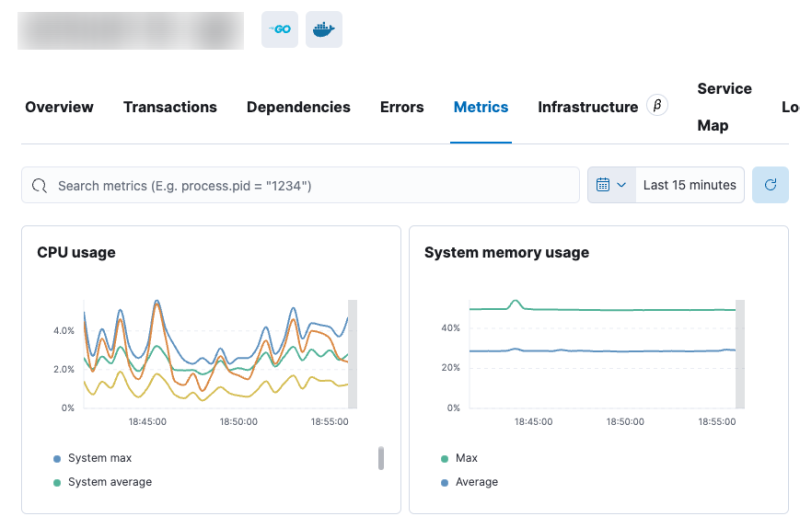 이외에도 디스크 사용량이나 IOPS나 여러가지 지표들이 존재할 수 있지만, 가장 기본적인건 이 2가지다.
이외에도 디스크 사용량이나 IOPS나 여러가지 지표들이 존재할 수 있지만, 가장 기본적인건 이 2가지다.
CPU 리소스가 부족하면 시스템이 매우 느려지거나 거의 멈출 수 있고,
메모리가 부족하면 대부분의 시스템은 OOM으로 터질 것이다.
1. 알람
그래서 이런 긴급도가 높은 리소스 사용량 급증에 대해서는 트리거를 걸어서 알림을 구축하고 빠르게 대처할 수 있게 하는 것이 중요하다.
내 경우에는 AWS를 쓰기 때문에 Cloudwatch 기반으로 대부분의 주요 리소스에 대해서 알림을 구현했다.
 이런건 Open-Closed 형태로 관리하는 것이 편하다.
이런건 Open-Closed 형태로 관리하는 것이 편하다.
2. 오토 스케일링
리소스 메트릭은 단순 모니터링용으로만 쓰는 게 아니라, 서버를 자동으로 스케일아웃-다운하는 용도로 사용하기도 한다. 대부분 실시간 메트릭에 기반해서 오토 스케일링을 구성한다.
CPU가 얼마 이상 치면 서버를 한대 늘리고, 안정화되면 한대 줄이고 하는 식으로 말이다.
AWS만 해도 그렇다.
3. Metric 저장소
metric도 로그처럼 어디다가 저장을 하긴 해야 한다. 여기에도 상황에 따라서 선택지가 좀 있다.
클라우드에서
클라우드 서비스에서 관리형 리소스를 쓴다면, 따로 metric 저장을 고려할 필요는 거의 없다.
대표적으로 AWS의 경우에는 Cloudwatch를 기반으로 metric을 자동으로 저장하고 가시화해준다.
오픈소스 시스템
대표적인 metric 저장용 시스템은 prometheus가 있다. 딱 metric 저장만을 위한 시계열 DB다.
특히 k8s 스택은 이게 국룰이다. prometheus에 저장하면 또 가시화된 대시보드는 grafana 스택을 쓴다.
grafana에서 만든 prometheus 대체재로 grafana mimir가 있는데, 많이들 쓰는지는 잘 모르겠다.
Elasticsearch 기반의 APM 스택에서도 지원한다.metric 저장은 elasticsearch에 하고 가시화는 kibana로 한다.
D. Transaction Metric
리소스 사용량은 사용량이고, 각 기능 단위의 성능 추적을 위해서는 Transaction Metric을 주로 사용한다.
Transaction을 Trace라고 부르기도 한다.
Opentelemetry에서 트랜잭션은 하나의 완전한 작업 단위를 말한다. 웹서버에서는 HTTP Request 각각을 하나의 Transaction으로 잡곤 한다.
그래서 전체적인 레이턴시(응답시간)이나 처리량, 실패율 같은 것도 transaction metric의 일부로서 다룬다.
아래 예시는 Elasticsearch APM의 transaction metric이다.
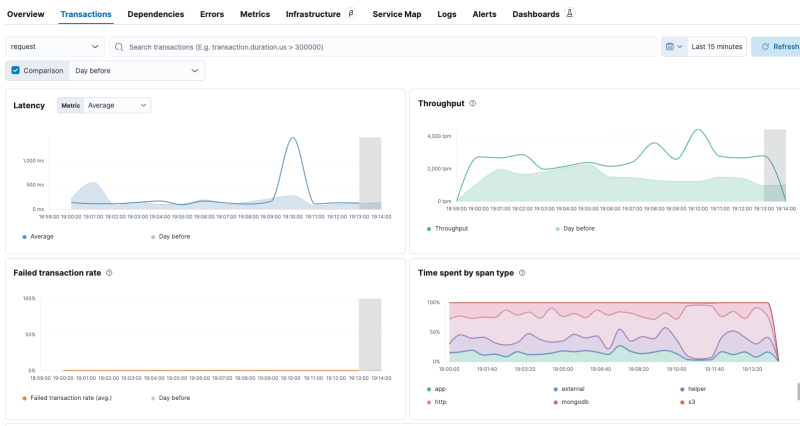 레이턴시나 처리량, 실패율 따위를 쉽게 볼 수 있다.
레이턴시나 처리량, 실패율 따위를 쉽게 볼 수 있다.
1. Transaction & Span 구조
transaction base metric에서는 transaction과 span이라는 2가지 단위를 기반으로 성능과 각 진행에 대한 메타데이터를 저장하고 추적할 수 있다.
하나의 작업 단위를 transaction으로 잡고, 작업에 속한 하위 행위들을 Span으로 잡아서 어느 부분에서 시간이 얼마나 걸리는지, 어떤걸 들고 실행되었는지를 추적할 수 있다.
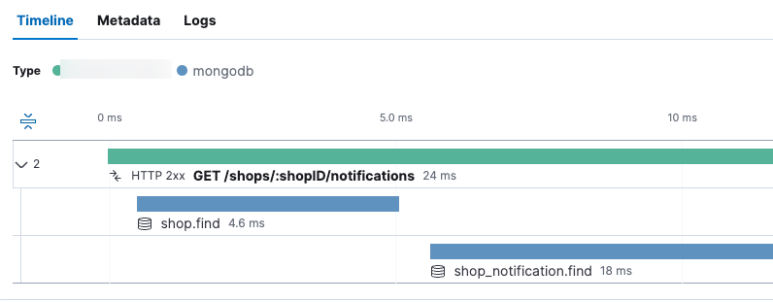 이런 느낌이다.
이런 느낌이다.
이건 특히 I/O 수준 딜레이로 인한 응답속도 등을 추적하기에 좋다. 약간 높은 수준의 성능추적이다.
이거보다 낮은 수준으로 가면 그게 지속적 프로파일링이다.
참조
https://blog.naver.com/sssang97/223389852344
2. Transaction Metric 시스템
유료 서비스
Datadog 같은 서비스들에서 보통 다 지원한다.
오픈소스
Elasticsearch APM에서 기본으로 통합해서 제공한다.
Grafana 스택에서는 Grafana Tempo를 통해 Transaction Metric의 저장과 쿼리를 지원한다.
E. 지속적 프로파일링
지속적 프로파일링(Continuous Profiling)은 성능 추적을 위한 가장 극단적인 모니터링 방법론 중 하나다.
실제 시스템 수준의 프로파일 데이터를 실시간으로 수집해서, 실제 코드의 함수들이 CPU 리소스를 얼마나 점유했는지, 메모리를 얼마나 할당했는지 등을 언제든 확인할 수 있게 하는 것이다.
보통 CPU 프로파일링과 메모리 사용량 프로파일링을 주로 사용한다.
아래는 대표적인 프로파일링 수집&가시화 도구인 Grafana Pyroscope다.
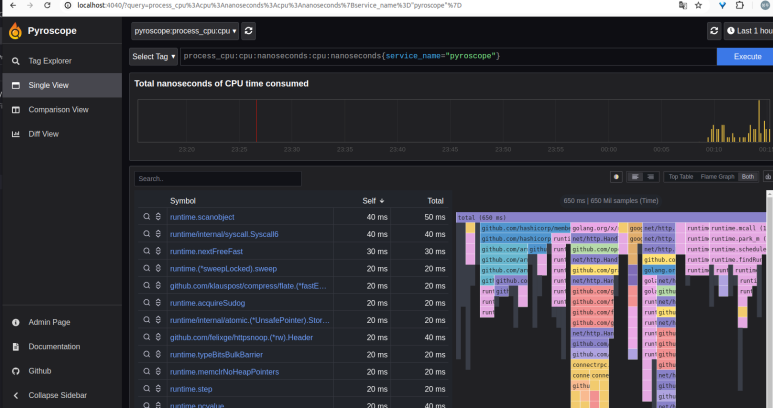
서버 부하?
이걸 하려면 서버들이 실시간으로 셀프 프로파일링을 해서 자신의 프로파일 데이터를 보내줘야 하는데, 이걸 하는데서 서버 리소스가 좀 소모될 수는 있다. 하지만 보통은 5% 미만이라서 크게 문제가 될 정도는 아니다.
언어별 차이
이건 시스템을 구현하는데 사용한 언어의 영향을 많이 받는다.
C/C++, Rust 같은 시스템 기본 메모리 할당을 사용하는 네이티브 언어들은 jemalloc 같은 메모리 할당자를 사용하지 않으면 메모리 프로파일링은 불가능하고, CPU 프로파일링만 가능하다.
Java, Go 같은 메모리 할당자를 언어 차원에서 구현해서 사용하는 경우에는 거의 모든 프로파일링 데이터를 쉽게 수집할 수 있다.
지속적 프로파일링 도구
오픈소스
대표적인 오픈소스 도구로는 Grafana Pyroscope가 있다.
Elasticsearch APM도Universal Profiling이라고 해서 지원한다.
유료 서비스
Datadog 같은 유료서비스들도 이걸 지원한다.
참조
https://blog.naver.com/sssang97/223415589139