[Redis] multi node를 구성하는 방법
Redis가 멀티 노드 구축을 통해 사용량이나 가용성을 확장하는 방법을 다룬다.
기본 원리
1. Replication
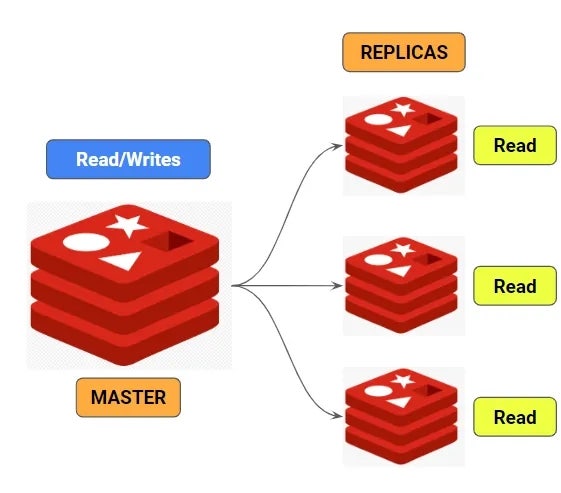
Redis도 여타 고전적인 DB들처럼 master-slave 방식의 replication을 지원한다.
 https://ankitsahay.medium.com/redis-multi-node-deployment-replication-vs-cluster-vs-sentinels-8099d15dcc09
https://ankitsahay.medium.com/redis-multi-node-deployment-replication-vs-cluster-vs-sentinels-8099d15dcc09
마스터 노드에다가 값을 쓰거나 수정하면, slave 노드들에 값을 복제시키면서 쓰는 것이다.
그래서 쓰기 작업은 master에만 행할 수 있고, slave 노드를 참조할 경우에는 복제 딜레이로 인한 오차가 발생할 수 있다는 단점이 있다.
이 구조의 주 목적은 read 부하를 분산하는 용도로 쓰는 것이다.
write 부하를 확장할 수는 없다. master가 더 많은 일을 하기 때문에 오히려 줄어들 수도 있다.
master 노드가 다운되더라도 slave를 master로 승격하거나 하진 않는다. 고가용성을 보장하진 못한다.
2. Clustering
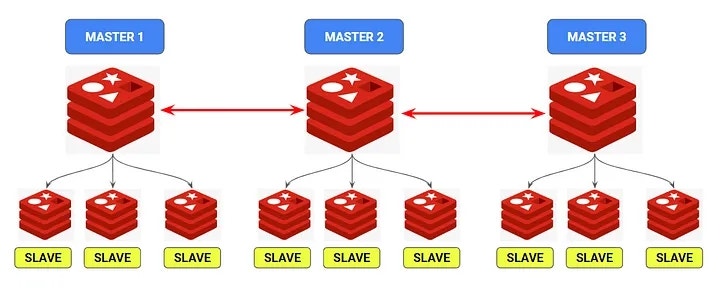
규모가 계속 확장되고 단일 마스터로 부하를 감당하기 힘들거나 메모리 용량이 부족한 지경에 이른다면, multi master로 클러스터를 구성하는 단계에 이르게 된다.
물론 Redis를 어지간히 짬통처럼 쓰는게 아니라면 그 정도 부하에 도달하는게 흔한 일은 아닐 것이다.
 https://ankitsahay.medium.com/redis-multi-node-deployment-replication-vs-cluster-vs-sentinels-8099d15dcc09
https://ankitsahay.medium.com/redis-multi-node-deployment-replication-vs-cluster-vs-sentinels-8099d15dcc09
클러스터 환경에서 보통 마스터는 N개로 구성되며, 각각의 읽기 전용 Slave 세트를 가진다.
이 경우 master끼리는 동일한 데이터를 복제하는게 아니라, 1/N로 데이터를 분할해서 저장한다.
그리고 각 Slave들은 본인들의 Master에 대한 읽기 전용 복제본만을 가진다.
만약 Master가 죽을 경우 Slave가 Master로 승격되어 그룹 내에서의 쓰기와 복제를 처리할 수 있다. 고가용성을 어느 정도 보장할 수 있는 것이다.
3. Redis Sentinels
Redis Sentinels은 고가용성이 필요하지만 multi master까지는 필요하지 않은 중간 지점의 사용자를 위한 방법론이다.
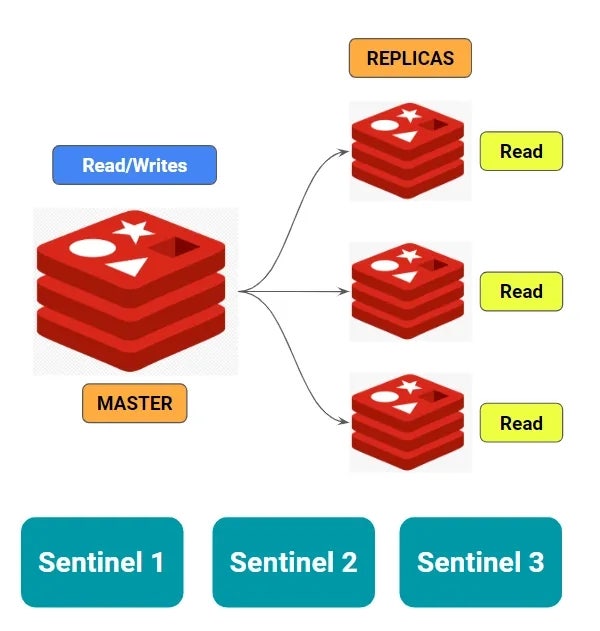 일반적인 Master Slave 구조 시스템에서 Master가 죽어도 Slave를 승격시키지 못하는 이유는, 애초에 Master가 모든 책임을 지고 복제나 관리를 총괄하는 것을 전제로 시스템이 짜여있어서 그런 것이다.
일반적인 Master Slave 구조 시스템에서 Master가 죽어도 Slave를 승격시키지 못하는 이유는, 애초에 Master가 모든 책임을 지고 복제나 관리를 총괄하는 것을 전제로 시스템이 짜여있어서 그런 것이다.
기본 설계 수준부터 분산 DB로 만들어진 근래의 시스템들은 서로서로 체크해주면서 과반수 투표 하고 그렇게 살려주는 구조가 있긴 한데, Redis는 그런거까진 없다.
그래서 master의 생존을 확인해주는 Sentinel이라는 서브프로세스를 따로 구성하고, 그걸 통해 master가 뻗으면 새 master를 선정하는 일련의 작업을 수행한다.
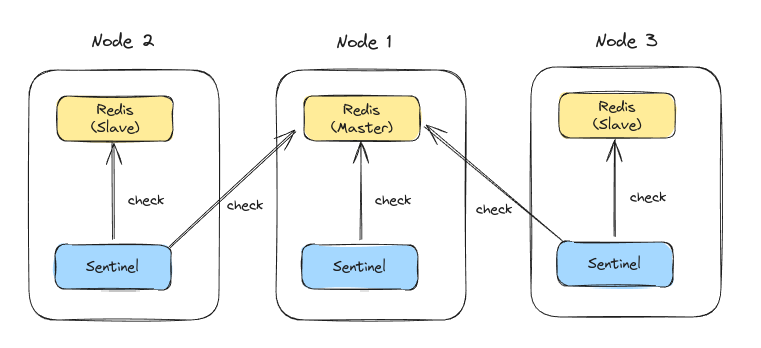 따로 별도의 머신이 필요한건 아니고, 각 레디스 노드와 함께 포장해서 띄우면 된다.
따로 별도의 머신이 필요한건 아니고, 각 레디스 노드와 함께 포장해서 띄우면 된다.
별도 인스턴스에 띄워도 되긴 하는데, 리소스 낭비도 낭비고 네트워크 레이턴시도 늘어날 것이다.
사실 Redis 내부에서 자체적으로 구현할 수도 있을텐데 귀찮아서 따로 빼서 제공하는 것 같다.
아무튼 이 sentinel들은 각각의 Redis 프로세스들이 살아있는지도 검사하고, master가 살아있는지도 모니터링한다. 과반수 합의로 master가 실패했다는게 확실하면 master 교체를 수행한다.
참조
https://redis.io/docs/latest/operate/oss_and_stack/management/replication/
https://redis.io/docs/latest/operate/oss_and_stack/management/sentinel/