[Redis] 시스템구조
사람들이 Redis에 대해서 설명할때 자주 말하는 특징 중 하나는, 싱글 스레드 시스템이라는 것이다.
그 전반적인 구조에 대해서 한번 정리를 해보겠다.
인 메모리 시스템
이게 뭐냐면, 메모리, 그러니까 RAM에 데이터를 저장하는 DB라는 것이다.
그래서 디스크에 데이터를 저장하는 고전적인 의미에서의 DB라고는 부를 수 없다.
일반적인 RDB들이 디스크에 데이터를 저장하고, 메모리를 최적화의 수단으로 사용한다.
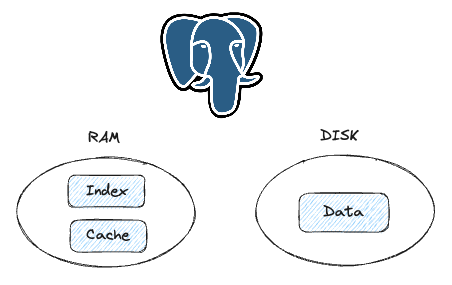 큰 데이터를 저장하기 유리하고, 장애시의 대응도 안정적이지만, 성능, 특히 레이턴시를 극단적으로 최적화하는데는 한계가 있다. 기본적으로 캐시를 타지 못하면 디스크를 거치기 때문에다.
큰 데이터를 저장하기 유리하고, 장애시의 대응도 안정적이지만, 성능, 특히 레이턴시를 극단적으로 최적화하는데는 한계가 있다. 기본적으로 캐시를 타지 못하면 디스크를 거치기 때문에다.
보통은 밀리세컨드 수준이라고 봐도 된다.
하지만 레디스는 바로 데이터를 메모리에 저장하고, 디스크를 선택적인 백업 수단으로 사용한다.
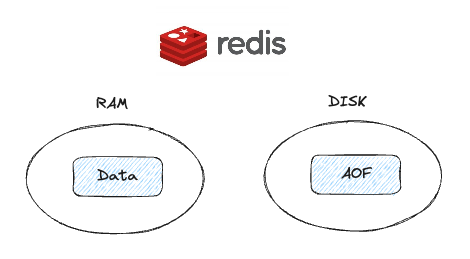
그래서 레디스는 기본 성능이 일단 빠르다.
공간도 작고 서버 재부팅시 데이터가 날라간다는 점이 있지만,
단순한 메모리 전달자 수준이라서 레이턴시를 마이크로세컨드 수준으로 보장할 수 있다는게 가장 큰 장점이다.
근데 그정도로 민감한 레이턴시 보장이 필요한게 아니라면 굳이 레디스를 쓸 이유는 없다.
싱글 스레드 시스템
Redis는 일단 싱글 스레드 시스템은 맞다.
DB 엔진 수준에서 동시에 한번의 연산만이 가능하다.
그래서 Redis는 멀티코어에 올려도 이점이 별로 없다.
성능 확장을 위해서는 단일코어 머신을 여러개 띄워서 스케일아웃하는 형태로 확장을 해야 한다.
레디스가 싱글 스레드 구조를 채택한 이유는 구조를 단순하게 유지하기 위한 점이 크다.
멀티스레드 동기화나 복잡한 성능 저하 요인이 별로 없기 때문에 오히려 성능이 괜찮은 부분도 있다.
그리고 단일 스레드로 동작하기 때문에 원자성을 강력하게 보장할 수 있다는 장점도 있다.
Redis 7에서는 스레드를 도입하겠다는 말이 있긴 한데, 정해진건 아니다.
I/O 멀티플렉싱
근데 단일 스레드를 쓴다고 해서 동시성을 활용하지 못한다는 것은 아니다.
Redis의 코어 엔진 자체는 싱글 스레드지만, Request를 받아서 사용자 요청을 핸들링하는 부분은 멀티스레드를 통해 다중화한다.
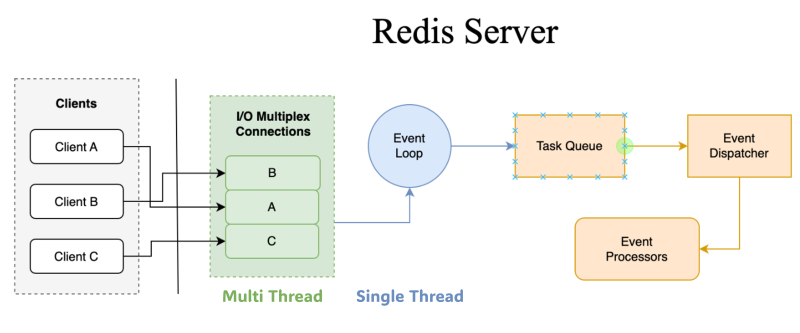 그래서 사실 실제 read/write 수준에서 발생하는 병목은 해결하진 못하지만, 탄력적으로 네트워크 요청/응답을 다중화해서 사용자 수준에서 느끼는 처리량은 크게 나쁘지 않다.
그래서 사실 실제 read/write 수준에서 발생하는 병목은 해결하진 못하지만, 탄력적으로 네트워크 요청/응답을 다중화해서 사용자 수준에서 느끼는 처리량은 크게 나쁘지 않다.
요청 태스크들이 단일 이벤트루프에 요청을 쏘면, 코어 엔진은 이벤트루프를 기반으로 결과를 핸들링한다.
네트워크 핸들링에는 epoll/kqueue을 활용한다.
Redis 6에서 Thread가 추가되었다고 말하는 것도 이 네트워크 I/O 핸들링을 위해서 멀티스레드를 활용했다는 말이다.
확장
레디스는 자체적인 한계 탓에 스케일업은 좀 효율성이 떨어지고, 서버를 여러개 띄워서 사용량을 확장하는 멀티노드 구성을 많이 사용한다.
Redis에서 멀티노드를 구성하는 방법은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223485062023
참조
https://velog.io/@hope1213/Redis-%EC%A0%95%EB%A7%90-%EC%8B%B1%EA%B8%80%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%BC%EA%B9%8C
https://stackoverflow.com/questions/48035646/if-redis-is-single-threaded-how-can-it-be-so-fast
https://www.linkedin.com/pulse/why-heck-single-threaded-redis-lightning-fast-beyond-in-memory-kapur
https://redis.io/blog/multiplexing-explained/