[SQL] 커버링 인덱스 (Covering Index)
커버링 인덱스는 특정 쿼리에 컴팩트하게 최적화된 인덱스를 구성하는 것을 말한다.
한번 직접 돌려보면서 알아보자. 환경은 PostgreSQL이나, RDB들은 그 원리가 거의 같다.
기본 인덱스
일단 간단한 테이블을 만들어서 적당한 테스트셋을 랜덤으로 만들어보겠다.
CREATE TABLE buldak (
id SERIAL PRIMARY KEY,
rand int,
n int
);insert into buldak(rand, n)
select floor(random() * 500001)::integer, t.n
from (
select generate_series(0, 10000000) as n
) as t; 행 1000만에 랜덤 숫자 50만이니, 확률적으로 랜덤 숫자 하나당 20개 정도 물린다고 볼 수 있겠다.
행 1000만에 랜덤 숫자 50만이니, 확률적으로 랜덤 숫자 하나당 20개 정도 물린다고 볼 수 있겠다.
저대로 그냥 적당히 필터를 해보면
explain(analyze) select * from buldak where rand = 5640;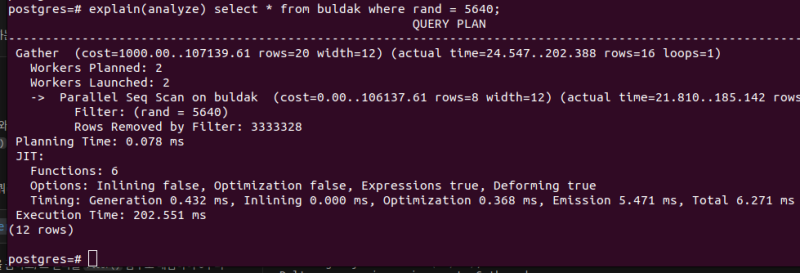 당연히 풀스캔을 떄릴 것이다.
당연히 풀스캔을 떄릴 것이다.
그리고 인덱스를 만들면
create index foo on buldak(rand);
그때부터는 인덱스가 껄려서 빨라진다.
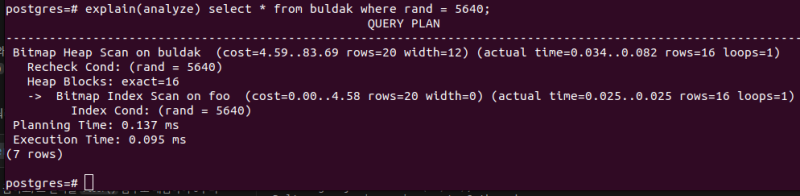
단일 컬럼으로만 필터링해도 충분한 그런 사례에서는 별로 신경쓸 것이 없다.
하지만 일반적인 비즈니스 서비스는 저 정도로는 턱도 없고, 보통은 굉장히 복잡한 필터링이 요구될 때가 많다.
다중 컬럼 인덱스
컬럼이 2개 이상이 되면 그때부터 고민을 해야할 시기가 온다.
먼저 테스트데이터를 적당히 쌓아보자.
CREATE TABLE rust (
id SERIAL PRIMARY KEY,
narrow_rand int,
wide_rand int,
n int
);insert into rust(wide_rand, narrow_rand, n)
select floor(random() * 10001)::integer, floor(random() * 51)::integer, t.n
from (
select generate_series(0, 10000000) as n
) as t; 이번에는 비중을 좀 다르게 했다.
이번에는 비중을 좀 다르게 했다.
wide에는 랜덤 폭을 늘여놔서 인덱싱이 좀더 빠르게 타게끔 했고, narrow는 사실상 인덱스가 무의미할 정도로 분포시켰다.
저대로 그냥 조회하면
explain(analyze) select * from rust where wide_rand = 400 and narrow_rand = 45;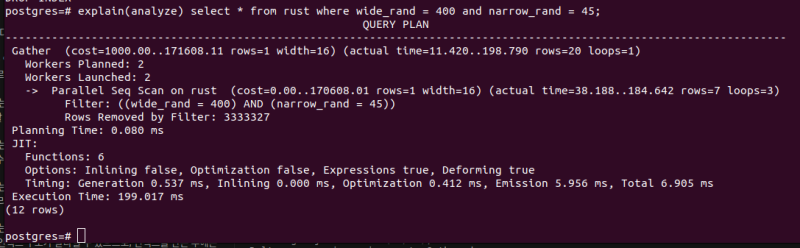 당연히 다 풀스캔만 때릴 것이다.
당연히 다 풀스캔만 때릴 것이다.
그러면 먼저 narrow=>wide 순서로 구성된 복합인덱스를 만들어보겠다.
DROP INDEX IF EXISTS asdf;
CREATE INDEX asdf ON rust (narrow_rand, wide_rand); 인덱스는 잘 걸렸고, 0.06초 정도가 걸린다.
인덱스는 잘 걸렸고, 0.06초 정도가 걸린다.
반대 순서로 걸면 어떨까?
DROP INDEX IF EXISTS asdf;
CREATE INDEX asdf ON rust (wide_rand, narrow_rand); 0.03초로 조금 더 빨라진 성능을 보여준다.
0.03초로 조금 더 빨라진 성능을 보여준다.
극적인 결과를 보이려면 더 조정을 해야할텐데, 귀찮아서 이 정도까지만 했다.
먼저 wide로 인덱스를 거는게 더 좁은 범위로 잡고 스캔을 시작할 수 있기 때문이다.
Order By 절
이번에는 Order by 같은 부가적인 Select 연산에 대해서 최적화 사례를 들어보겠다.
테스트데이터는 맨 위에서 쓴 테이블을 재사용한다.
먼저 데이터 세팅부터 한다.
delete from buldak;
create index if not exists foo on buldak(rand);
insert into buldak(rand, n)
select floor(random() * 10001)::integer, t.n
from (
select generate_series(0, 10000000) as n
) as t;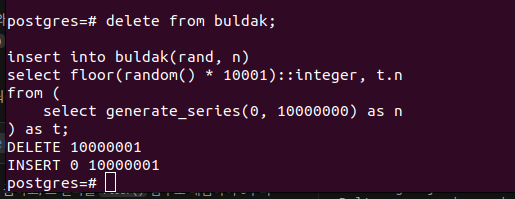
이번에는 필터->정렬 같은 복합 연산에 대해서 어떻게 인덱싱을 해야할지 정리해보겠다.
explain(analyze) select * from buldak where rand = 5640 order by n desc limit 1;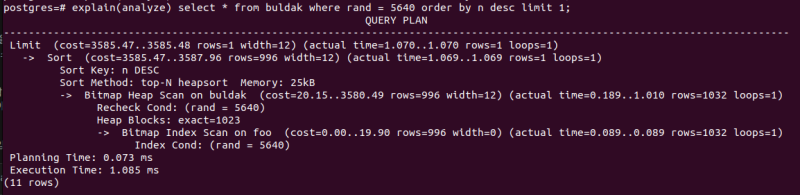 적당히 짜봤다.
적당히 짜봤다.
당연히 인덱스가 있긴 있어서 타긴 타는데, 뭔가 체크가 많고 연산이 많다.
실행시간도 1초가 넘게 나왔다.
여기에 대해서 커버링 인덱스를 구성하려면, 이런 식으로 넣어줘야 한다.
CREATE INDEX bar ON buldak (rand, n DESC); 먼저 rand로 필터하고, n으로 내림차순 정렬을 처리할 수 있는 인덱스다. 항상 WHERE가 먼저고, ORDER가 그 다음임을 기억하길 바란다.
먼저 rand로 필터하고, n으로 내림차순 정렬을 처리할 수 있는 인덱스다. 항상 WHERE가 먼저고, ORDER가 그 다음임을 기억하길 바란다.
그리고 정렬까지 고려해야 최적의 케이스로 인덱스를 타니 유의한다.
그러고 나서 다시 날려보면
explain(analyze) select * from buldak where rand = 5640 order by n desc limit 1; 깔끔하게 인덱스를 타고, 성능도 0.03으로 매우 시원하게 나온는 것을 볼 수 있다.
깔끔하게 인덱스를 타고, 성능도 0.03으로 매우 시원하게 나온는 것을 볼 수 있다.
Group By 절
Group By 절도 Order By 절과 양상이 크게 다르지는 않다.
그저 필터 순서가 WHERE => GROUP BY => ORDER BY 순서로 이뤄진다는 것 정도만 알아두면 된다.
drop index if exists foo;
drop index if exists bar;인덱스 없이 쌩으로 조회하면
explain(analyze) select rand, count(1) from buldak where n < 1000 group by rand;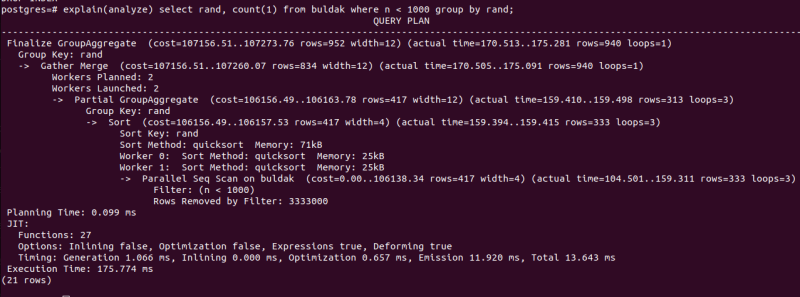 당연히 어지럽게 풀스캔때리고 이상한 짓거리들을 잔뜩 할 것이다.
당연히 어지럽게 풀스캔때리고 이상한 짓거리들을 잔뜩 할 것이다.
실행시간도 0.2초 정도 나왔다.
그냥 단일 인덱스만 만들면
CREATE INDEX foo ON buldak (n);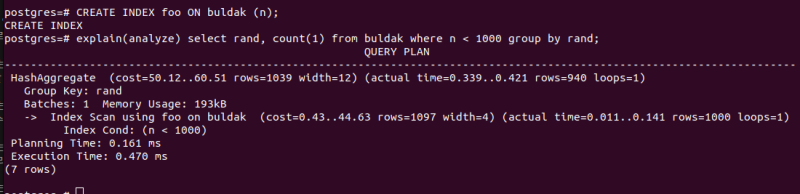 그것만 해도 일단 group 하기 전에 스캔하는 것 자체를 인덱스로 가져오니 꽤 빨라지긴 한다.
그것만 해도 일단 group 하기 전에 스캔하는 것 자체를 인덱스로 가져오니 꽤 빨라지긴 한다.
여기서 더 최적화를 해주려면, Group by 절까지 포함해서 인덱스를 걸어줘야 한다.
CREATE INDEX bar ON buldak (n, rand);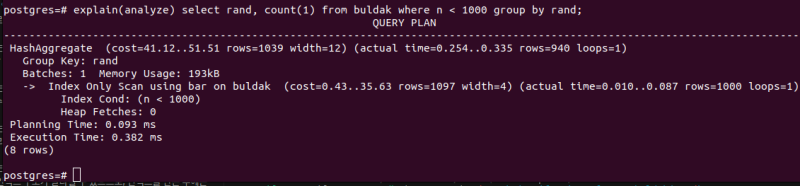 데이터 형태가 딱 그렇게 맞지 않아서 큰 차이가 나지는 않긴 하는데, 옵티마이저도 새로 만든 인덱스를 골랐고, 약간 더 빨라졌다.
데이터 형태가 딱 그렇게 맞지 않아서 큰 차이가 나지는 않긴 하는데, 옵티마이저도 새로 만든 인덱스를 골랐고, 약간 더 빨라졌다.
Select 절 최적화
이렇게까지는 잘 안하긴 하는데, 좀더 최적화를 한다면 include 인덱스라고 해서 Select 절 까지도 최적화를 할 수 있다. 이건 마지막 프로세스다.
참조
https://blog.naver.com/sssang97/222148841925