[MongoDB] 클러스터: 부하 분산 매커니즘
mongodb는 기본적으로 single master - multi slave 형태의 replication을 지원한다.
single node로도 운영이 가능하긴 하지만, 일반적으로 3 노드 환경을 권장하며, atlas 시스템에서도 기본 생성 옵션이 3 노드 클러스터다.
mongodb 클러스터의 개략적인 구조와, 클러스터를 잘 활용하는 방안을 간단히 정리해보겠다.
Replication 구조
mongodb는 고전적인 방식으로 복제를 구현한다.
master만 write를 직접 받고, 나머지 slave들은 복제를 받아서 읽기만을 처리하는 것이다.
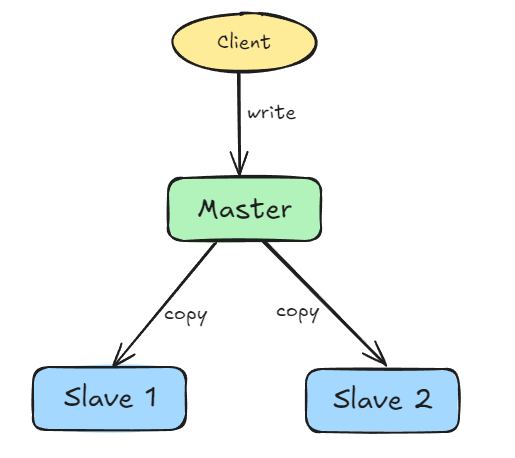 mongodb에서는 primary=master, secondary=slave라고 부르긴 하는데, 난 master slave가 더 입에 잘 붙어서 master와 slave라고 통칭하겠다. 항의 안받는다.
mongodb에서는 primary=master, secondary=slave라고 부르긴 하는데, 난 master slave가 더 입에 잘 붙어서 master와 slave라고 통칭하겠다. 항의 안받는다.
https://blog.naver.com/sssang97/223038029971
참조
아무튼 만약 master node에 과부하가 걸리거나 하면 뻗은걸로 간주하고, slave들이 다시 투표를 해서 새 master를 선출한다. 이 과정에서는 당연히 시스템이 뻗어서 몇초 정도의 중단이 발생할 수 있다.
그래서 master node에 과도한 부하가 걸리지 않도록 read만큼은 slave에 잘 분산되도록 하는 것이 중요하다.
애초에 single master 시스템들이 으레 그렇듯, 이건 쓰기 부하를 분산하기 위한 것이 아니라, 읽기 분산을 하기 위한 매커니즘이다.
Cluster URL (SRV)
mongodb 단일노드는 mongo:// 같은 일반적인 프로토콜을 쓰는데, mongodb 클러스터는 좀 특이한 엔드포인트 형식을 사용한다.

SRV라고 하는데, N개의 노드 엔드포인트에 동시에 접근할 수 있게끔 해주는 그룹의 역할을 해주는 프로토콜이다.
이걸 통해서 커넥션을 구성하면, 클러스터 내에 있는 모든 노드 엔트포인트에 참조할 수 있다.
편하기도 편한데, 일반적인 TCP 프로토콜이 아니라서 프록시나 터널링 구성하는게 좀 빡센 편이다.
Read Preference
read preference는 read 동작을 어떤 노드에 때릴지를 결정하는 옵션이다.
왜 그런지는 모르겠는데, mongodb 동작의 기본 설정은 primary다. master에만 read를 때린다는 것이다.
그래서 클러스터로 쓴다면 Read Preference 옵션을 Secondary로 설정해야만 노드 3개 띄워서 쓰는걸로 본전을 뽑을 수 있다.
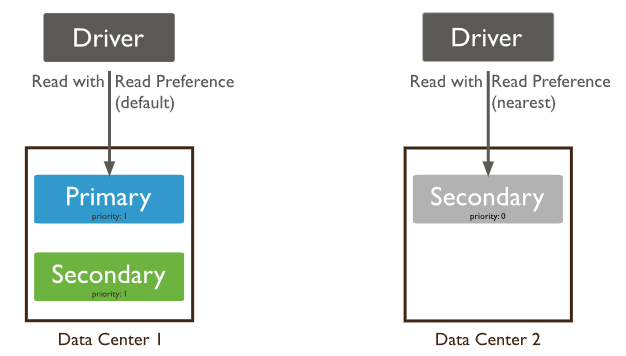
내 경우에도 뒤늦게 리소스 낭비를 하고 있는 것을 깨달아서 옮겼다.
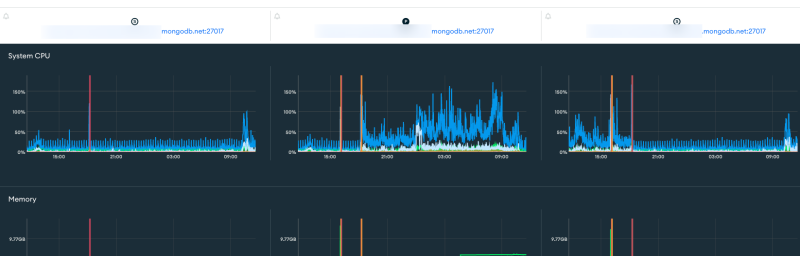 readPreference=primary라서 주인만 바쁘게 일하면서 다운되던 것이
readPreference=primary라서 주인만 바쁘게 일하면서 다운되던 것이
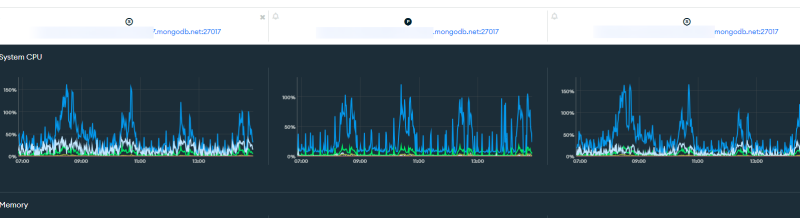 readPreference=secondary로 바꾸고 나서는 노예들이 열심히 일하기 시작했다.
readPreference=secondary로 바꾸고 나서는 노예들이 열심히 일하기 시작했다.
Write Concern
무슨 DB든간에 DB를 복제해서 쓰다보면 겪게되는 가장 큰 문제가 복제로 인한 딜레이다.
write node에 A 값을 넣었는데, 그 값이 read node에 복제되기도 전에 참조를 하면 데이터가 꼬이는 상황이 발생할 수 있기 때문이다.
mongoDB의 경우에는 write concern을 이용해서 read after write를 그럭저럭 대처할 수 있다.
https://blog.naver.com/sssang97/223248671329
master+slave1+slave2의 3 노드라면 write concern을 3으로 줘서, 모든 노드에 복제되기까지 기다리게 할 수 있다.
물론 이걸 쓰면 클라이언트와 DB 서버 양측에 추가적인 부하가 생기긴 하는데, 대체로 그리 크진 않은 것 같다.
참조
https://stackoverflow.com/questions/66225004/what-is-meant-by-srv-in-the-mongodb-connection-string