[Java] GC의 구조와 원리
 Java가 GC를 구현한 최초의 언어는 아니지만, 가장 뛰어난 GC를 가진 언어라고는 할 수 있을 것이다.
Java가 GC를 구현한 최초의 언어는 아니지만, 가장 뛰어난 GC를 가진 언어라고는 할 수 있을 것이다.
Java는 현존하는 managed 언어들 중에서는 가장 빠르고 안정적인 GC를 제공한다.
ZGC를 적용한 Java 버전(since Java 15)은 무려 최대 16TB 단위의 메모리를 감당하고, 10 밀리세컨드 내의 지연으로 정리할 수 있다.
여기서 밀리세컨드도 극단적인 경우고, 일반적인 경우에는 마이크로세컨드 내에 처리가 된다.
C#이나 Go 같은 여타 GC 언어들은 수백기가 정도의 메모리 핸들링이 한계고 그것마저도 그리 빠르진 않다.
이 포스트에서는 JVM이 GC를 구현한 방법뿐만 아니라, GC의 역사에 대한 개괄적인 흐름 또한 다뤄보려 한다.
Java GC의 흐름
각 GC 구현체의 등장 시기만 간략히 정리했다.
JVM은 한가지의 GC만 제공하는게 아니라, GC 알고리즘을 선택해서 쓸 수 있다.
Serial GC
Java 1.2 초기부터 포함된 GC.
Java 5부터는 기본옵션이 아님.
싱글스레드로만 도는 GC.
Parallel GC
Java 5 ~ 8의 기본 GC
CMS GC
Java 7 ~ Java 8에 포함된 GC.
Java9 deprecated. Java 15 사용중단.
G1GC
Java 9부터 적용된 GC.
Java 9~의 기본 GC.
Shenandoah GC
OpenJDK 12부터 포함된 GC
ZGC
Java15부터 포함된 GC.
아직 기본 옵션은 아니다.
저 GC들을 파헤치기에 앞서서, 먼저 자바의 앞길을 닦아준 선현들의 노고부터 되돌아보며 기본기를 쌓아보자.
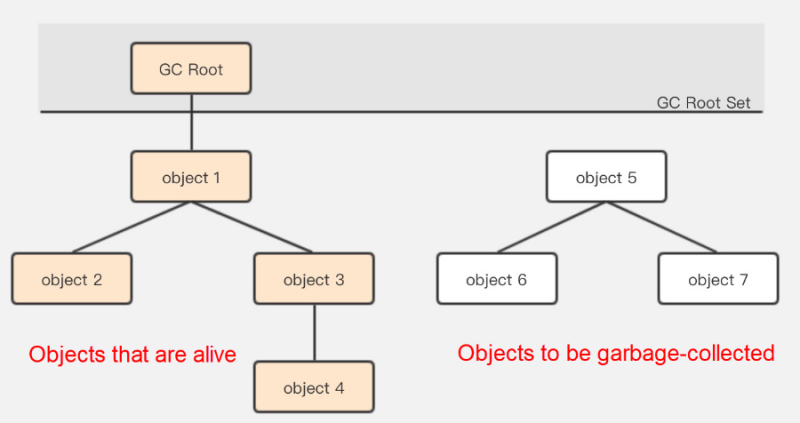
Basic: reachability analysis 알고리즘
거의 모든 GC 언어들은 다음과 같은 형태로 쓰레기를 식별하고 정리한다.
 https://alibabatech.medium.com/how-does-garbage-collection-work-in-java-cf4e31343e43
https://alibabatech.medium.com/how-does-garbage-collection-work-in-java-cf4e31343e43
일명 root 객체를 먼저 정의해두고, 힙 객체가 생성될때마다. 참조를 기반으로 쭉쭉 연결되게 구성하는 것이다.
root 객체는 힙 객체가 아니지만 최상위 레벨에서 힙 객체를 가리킬 수 있는 주체를 말한다. 일반적인 스택 지역변수나 전역변수 같은 것들이 해당될 것이다.
예를 들어 a라는 지역변수에 new Integer()가 할당되면, a가 root가 되고 new로 생성한 객체가 a에 연결된 자식이 되는 것이다.
그러다 지역변수 a가 스택을 벗어나 할당해제되면 객체는 참조 없이 붕 뜨게 된다. GC는 이러한 쓰레기(Garbage)들을 주기적으로 돌면서 제거한다.
그래서 보통 Object의 트리 깊이가 깊거나, root 객체가 많을수록 부하가 커지는 편이다.
자바도 이러한 근간을 벗어나지는 않지만, 최적화를 위해서 여러가지 변칙적인 방법들을 많이 사용한다.
Basic: 세대별(Generational) GC
대다수의 GC 언어들은 세대별 GC 이론을 기본으로 사용한다. 자바만의 전유물은 아니다.
세대별 GC는 다음과 같은 경험에서 우러난 가설을 토대로 한다.
- 대부분의 객체는 금방 죽는다.
- GC에서 살아남은 횟수가 늘어날수록, 그 객체는 더 오래 살아있을 확률이 커진다.
이러한 경험에 힘입어 JVM은 신세대와 구세대를 별도의 공간에 저장하며 관리한다.
계속해서 살아남을 확률이 높은 객체만 구세대 영역에 모아두고, 나머지를 신세대에 두고서 집중하는 것이다.
Java: GC 레벨
세대별 이론에서 파생된 부분 중 하나다.
JVM은 효율화를 위해 GC의 레벨을 몇가지로 세분화한다.
세부사항은 GC 구현체마다 다르다.
Minor GC
신세대만 대상으로 GC를 수행한다.
Major GC
구세대만 대상으로 GC를 수행한다. (CMS GC에만 존재)
혼합 GC
신세대 전체와 구세대 일부를 대상으로 하는 GC (G1GC만 해당)
전체 GC
힙 전체와 메서드 영역 전체를 대상으로 하는 full GC
Hisory: Mark and Sweep 알고리즘
현대 GC의 근간이 된 기법 중 하나다.
1960년에 리습의 창시자 매카시가 만들었다.
Java에서도 몇몇 GC 기법은 마크앤 스윕 기반으로 만들어졌고, Go는 지금도 이걸 쓴다.
SerialGC, CMS,
https://m.blog.naver.com/sssang97/221567636644
마크앤스윕은 초기에 나온 방법론인만큼 구조가 매우 단순하다.
루트객체들부터 한바퀴 뺑 돌면서 참조되고 있는지를 체크하고, 참조되지 않은걸 싹 지워버린다는 간단한 방법이다.
구현하기에는 편리하지만 단점이 많아서 Java의 경우에는 근래에 이 구조를 거의 버렸다.
매 GC 타임마다 모든 객체를 풀스캔하면서 찍고, 또 풀스캔하면서 지워야 하기 때문에 메모리가 커지면 감당이 안된다.
게다가 메모리 파편화도 심하다. 그냥 일단 지우고 보는게 최종 목적이기 때문에 메모리 조각모음같은걸 고려하지도 않았다.
메모리 파편화가 누적될수록 연속된 큰 공간이 없어져서 빈 공간을 찾기도 힘들고, 추가적인 정리작업이 필요해질 수도 있다.
Hisory: Mark and Copy 알고리즘
객체가 많아질수록 느려지는 마크앤스윕을 개선하기 위해 나온 알고리즘이다.
1969년에 로버트 페니첼이란 사람이 고안했다.
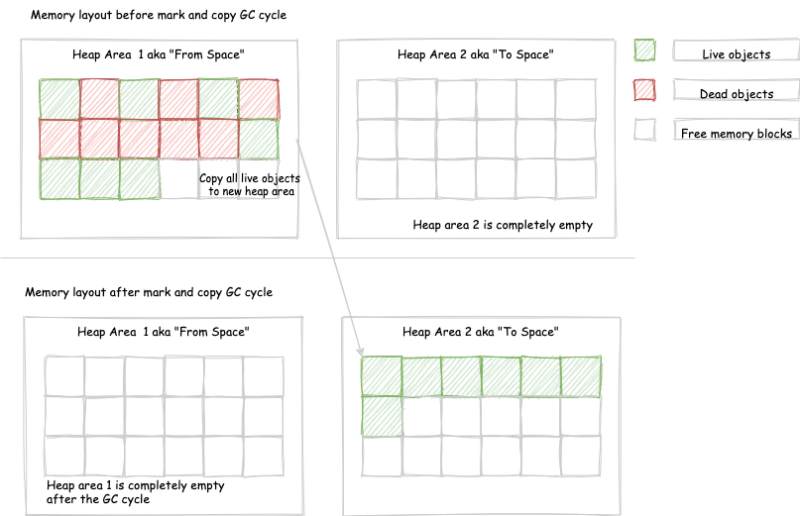
이 기법에서는, 우선 메모리를 2개로 쪼갠다.
그리고 한번에 한 블록만 사용한다.
 https://abiasforaction.net/understanding-jvm-garbage-collection-part-2/
https://abiasforaction.net/understanding-jvm-garbage-collection-part-2/
그러다 한쪽이 꽉차면 살아남은 객체만 다른 블록으로 옮기고 기존 블록을 싹 지워버린다.
대부분의 객체가 살아남는다면 다 옮겨야하니 복사비용이 꽤 들지만, 대다수가 죽는 경우라면 놀라울 정도로 효율적인 결과를 낼 수 있다.
게다가 옮기는 과정에서 새 블록에 차곡차곡 예쁘게 쌓아서 파편화 문제도 없다.
물론 단점도 명백하다.
메모리를 반토막내서 쓰는거라 가용 메모리 낭비가 심하고, 객체 생존률이 높다면 비효율적이기 때문이다.
그럼에도 불구하고 빈번한 삭제에 대해서는 뛰어난 성능을 보장할 수 있기 때문에 JVM에서는 신세대 영역에 대해서 Mark and Copy을 활용해서 구현한다.
정확히 말하면 하술할 Appel의 알고리즘을 차용한다.
Now: Andrew Appel의 알고리즘
Mark and Copy의 대표적인 단점 중 하나는, 메모리를 반갈죽해서 쓰는거라 메모리 낭비가 극심하다는 것이다.
그런데 실제 신세대 메모리에 대한 경험적인 연구결과가 있었는데, 98%의 신세대 객체가 첫번째 GC에서 날라간다고 한다.
그 말인즉슨, 굳이 절반이나 쪼개서 낭비하지는 않아도 된다는 것이다.
Appel은 이 점에 착안해서 변형된 Mark and Copy 알고리즘을 제안했다. 이건 지금 Java에서도 쓰이고 있는 현역이다.
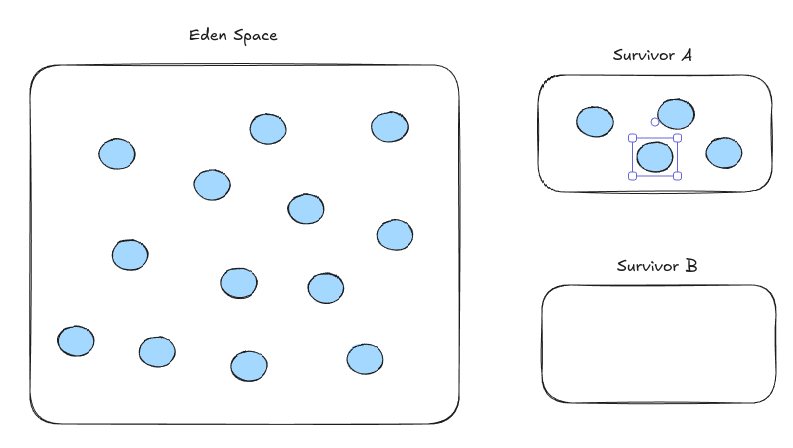 일단 매우 큰 메모리 영역 하나와 작은 메모리 영역 2개를 둔다.
일단 매우 큰 메모리 영역 하나와 작은 메모리 영역 2개를 둔다.
가장 큰 메모리를 Eden이라고 하는데, 보통 80%를 잡는다.
작은 메모리는 Survivor라고 한다. 10%씩을 점유하는 작은 공간이다.
일단 처음에 메모리를 쌓을때는 Eden 하나와 Survivor 하나에만 메모리를 쌓는다.
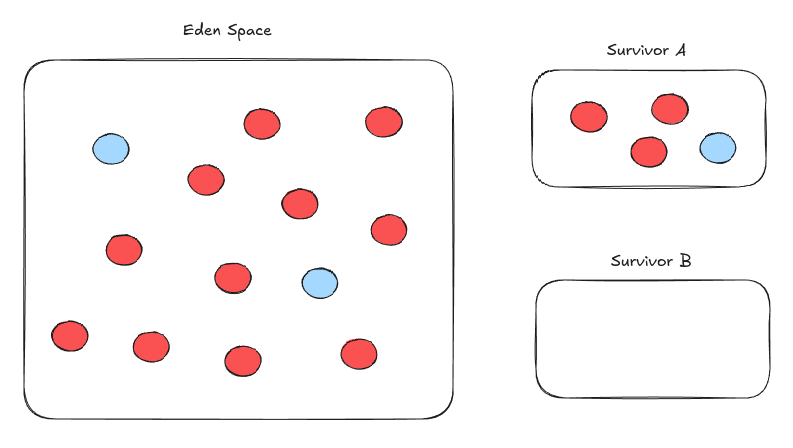 그리고 꽉차서 정리할 필요가 있으면
그리고 꽉차서 정리할 필요가 있으면
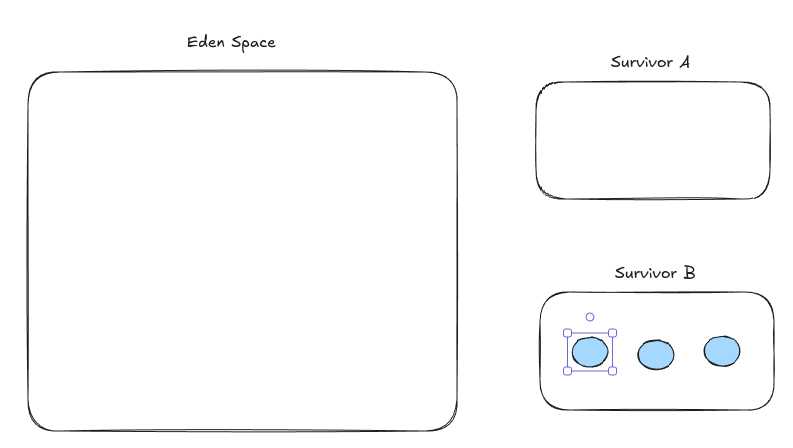 싹 날리고 안쓰던 나머지 Survivor로 옮긴다.
싹 날리고 안쓰던 나머지 Survivor로 옮긴다.
여기서부터는 Eden과 새로 옮긴 Survivor에 메모리를 할당하는 것이다.
근데 이건 보통 10%만이 살아남는다는 경험적인 추론에 근거한거라서, 실제 생존률이 10%가 넘을 수도 있다.
Appel의 알고리즘에서는 그런 상황이 발생하면 넘친 객체들을 구세대로 승격시켜 떠넘긴다.
이걸 메모리 할당 보증이라고 부른다.
아무튼 이 알고리즘은 G1GC가 나오기 전까지는 거의 모든 GC의 핵심 알고리즘으로 사용됐다.
Eden과 Survivor라는 용어는 G1에서도 계승된다.
History: Mark and Compact 알고리즘
Mark and Copy 이론은 특성상 대부분이 삭제되는 패턴에 효율적이기에 신세대 영역에 쓰인다고 했다.
반대로 Mark and Compact는 대부분이 유지되는 구세대 영역에 적절한 알고리즘이다.
Edward Lueders라는 사람이 1974년에 고안했다.
전반적인 동작방식은 마크앤스윕과 거의 비슷하다.
차이점은 마크 후에 쓰레기를 삭제할때, 삭제만 하는게 아니라 생존한 객체들을 한쪽으로 예쁘게 모은다는 것이다.
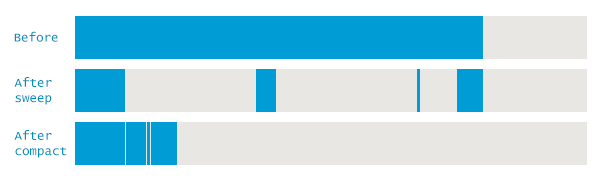 https://siahn95.tistory.com/108
https://siahn95.tistory.com/108
이를 통해서 파편화 문제를 해결한다.
바로 이놈이 이른바 Stop the World를 유발하는 주범이다. 메모리 이동은 필연적으로 메모리 접근을 차단한 채로 이뤄져야하기 때문이다.
ZGC에서는 이런 문제를 거의 해결한다.
이제부터는 이론에서 벗어나 실제 GC 구현체들의 히스토리를 살펴보겠다.
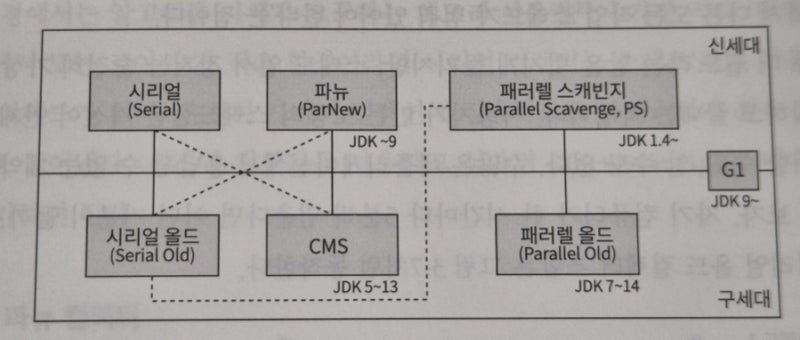 게임체인저인 G1GC가 등장하기 이전까지는 신세대와 구세대 GC가 따로 존재했고, 이래저래 이합집산을 이뤘다.
게임체인저인 G1GC가 등장하기 이전까지는 신세대와 구세대 GC가 따로 존재했고, 이래저래 이합집산을 이뤘다.
GC의 성능 지표
분산시스템의 지표에 CAP이 있듯이, GC에도 부분적으로만 달성 가능한 최종 지표가 있다.
바로 처리량(Throughput), 지연시간(latency), 메모리 사용량(footprint) 3요소다.
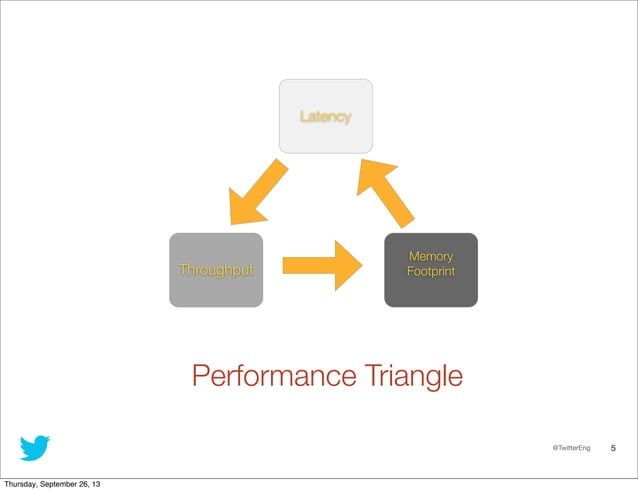
처리량은 전반적인 프로그램의 실행속도를 말한다.
지연시간은 gc에 걸리는 시간(Stop the world)를 말한다.
그리고 메모리 사용량은 실제로 메모리를 얼마나 효율적으로 쓰는지다.
현재 GC 알고리즘들은 3가지 지표를 전부 다 극대화하고자 노력하고는 있지만, 보통은 셋 중 하나는 포기해야하는 모양새가 나온다.
일례로, G1GC는 지연시간이 보통인 편이고, 처리량은 CMS보다 조금 낮다.
반대로 ZGC는 지연시간에 집중하는 대신 실행속도(처리량)을 좀 잃었다.
Java: Serial GC
Serial 시리즈는 자바의 태동기부터 역사를 이어온 산증인이다.
이건 GC가 싱글스레드에서 돈다. GC 돌릴때마다 전체 스레드를 다 정지시켜서 Stop the world로 인한 폐해가 가장 극심하다.
신세대용 Serial이 Mark and Copy고, 구세대용 Serial Old가 Mark and Compact로 구현된다.
그 대신 알고리즘이 단순하고 메모리 요구치가 낮아서 각박한 환경에서도 사용할 수 있다는게 유일한 장점이다.
Java: ParNew
신세대용 GC다. 근데 사실 별건 없고, 그냥 Serial을 멀티스레드로 돌리는게 다다.
여전히 GC 스레드와 유저 스레드가 동시에 돌진 못한다.
CMS와 쌍으로 쓰이곤 했었는데, 지금은 함께 버려졌다.
Java: Parallel GC
이것도 ParNew와 비슷하게 GC를 병렬로 띄우는 알고리즘이다. GC와 유저스레드가 동시에 뜨는건 아니다.
다만 CMS와는 다르게 GC로 인한 일시정지 시간에 집중하지 않고, 전체적인 처리량 개선을 우선하는 지향성을 가진다.
그러니까, Freezing 한번한번이 좀 길더라도 전체적인 실행속도를 단축하겠다는 것이다.
Java: CMS
CMS는 Mark and Sweep의 변형이다.
지금은 G1GC에 밀려서 폐기되었지만, 자바에 있어서는 큰 전환점이었다.
GC와 유저스레드가 동시에 떠서, GC가 유저스레드를 멈추지 않는다는 목표를 부분적으로나마 달성했기 때문이다.
아래 스텝을 따른다.
- 최초 mark
- 동시 mark
- remark
- 동시 sweep
여기서 "동시"라고 붙인 2번과 4번 단계는 실제로 User 스레드를 멈추지 않고 동시적으로 실행된다.
1번과 3번은 아직 유저 스레드를 멈춘다.
그럼에도 불구하고 획기적인 성과를 이룩했다고 볼 수 있다. 이게 나온 시점에서는 Stop the world로 인한 정지 시간이 가장 짧았다.
하지만 당연히 단점도 수두룩했다.
GC가 코어수를 잔뜩 점유하니, 정지시간은 짧더라도 처리량이 떨어진다.
게다가 floating garbage라고 하는 애매한 부작용도 존재했다. 시스템을 멈추고 GC를 하는게 아니다보니, 이미 문제없다고 판단하고 넘어간 영역에서 뒤늦게 쓰레기가 생길 수도 있다.
그러면 다음 GC타임때까지 쓰레기가 붕 뜨게 되는데, 이걸 floating garbage라고 한다.
이게 문제가 될 정도로 쌓이면 어쩔 수 없이 Stop the world를 때려서라도 긴급구호조치를 해야 한다.
게다가 마크앤스윕의 고질적인 문제인 파편화 문제도 그대로 떠안고있다. 조각모음을 시키는 옵션도 있는데, 당연히 그러면 더 느려지기도 한다.
Java: G1GC (Garbage First)
Java 9부터 적용된 표준 GC다.
G1은 발상의 전환을 시도했다.
여태까지는 구세대, 신세대, 혹은 전체 GC를 구분해서 GC를 돌렸었다.
G1은 영역을 쪼개는것보다 쓰레기에 집중했다.
무슨 세대에 속하는지가 중요한게 아니라, "어떤 곳에 쓰레기가 많은가?", "어딜 정리해야 이득인가?"를 중점으로 접근하는 것이다.
물론 세대기반 시스템을 사용하는 것은 동일하지만, 관점을 달리한다는 것이다.
구세대/신세대로 메모리를 쪼개는게 아니라 일단 바둑판처럼 region이란 단위로 메모리를 쪼갠다.
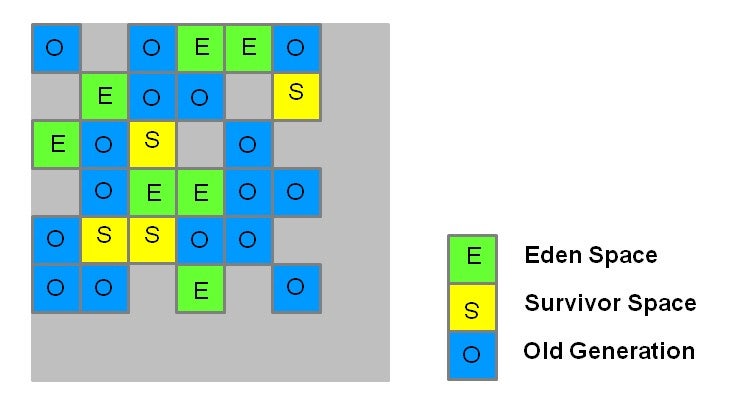 https://backendbrew.com/docs/java/gc/g1_gc
https://backendbrew.com/docs/java/gc/g1_gc
각각의 칸은 신세대(Eden/Survivor)가 될 수도 있고, 구세대가 될 수도 있다.
통상적으로 region의 크기는 1MB~32MB 정도다.
또, 거대한 객체를 관리하기 위한 거대 region이란걸 또 둔다.
 https://thinkground.studio/2020/11/07/%EC%9D%BC%EB%B0%98%EC%A0%81%EC%9D%B8-gc-%EB%82%B4%EC%9A%A9%EA%B3%BC-g1gc-garbage-first-garbage-collector-%EB%82%B4%EC%9A%A9/#google_vignette
https://thinkground.studio/2020/11/07/%EC%9D%BC%EB%B0%98%EC%A0%81%EC%9D%B8-gc-%EB%82%B4%EC%9A%A9%EA%B3%BC-g1gc-garbage-first-garbage-collector-%EB%82%B4%EC%9A%A9/#google_vignette
이런 느낌이다.
기존 GC 추적이 트리베이스로 이뤄진 것과 다르게, 이건 해시테이블 기반으로 서로를 참조하게끔 구성된다.
게다가 G1은 쓰레기를 정리할때 무턱대고 풀스캔을 돌리면서 지우지도 않는다.
일단 각 리전에 쌓인 쓰레기 크기를 지속적으로 추적한다.
그리고 크기만 쌓는게 아니라, 정리했을 때 얻을 수 있는 추가 메모리와 정리에 드는 예측 시간까지 종합해서 관리한다.
여기서 중요한건 "예측 시간"이다. GC가 정지해도 괜찮은 허용 시간 내에서, 효율적인 리전부터 순서대로 쓰레기를 정리해나간다. GC 정지 허용시간의 기본값은 200ms다.
그러다 다 못하면 그냥 다음 GC로 미루는 것이다.
청소 대상 리전에서 살아남은 객체는 전부 빈 리전으로 예쁘게 모아서 옮긴다. 파편화 문제도 없다.
이걸 통해서 G1는 정지시간을 최소화하면서도 처리량도 뽑아내고, 파편화까지 해결하는 꽤 안정적인 구조를 만들어냈다.
ZGC처럼 레이턴시에 최적화된건 아니지만, 모든 부분이 균등하면서도 통상적인 성능도 예전 것들보다 훨씬 낫다. 밸런스형이라 할 수 있다.
그래서 Java 9부터 기본 GC는 이 G1이다.
Java: ZGC(Z Garbage Collector)
ZGC는 Java 15부터 정식 도입된 저지연 GC 기법이다.
이건 무려 TB 수준의 메모리를 저지연으로 제어하기 위한 목적에서 도입됐다.
최대 16TB의 메모리를 10ms만에 정리하는 것을 보장한다.
ZGC도 G1GC와 비슷하게 바둑판 형태로 메모리를 쪼개서 사용한다.
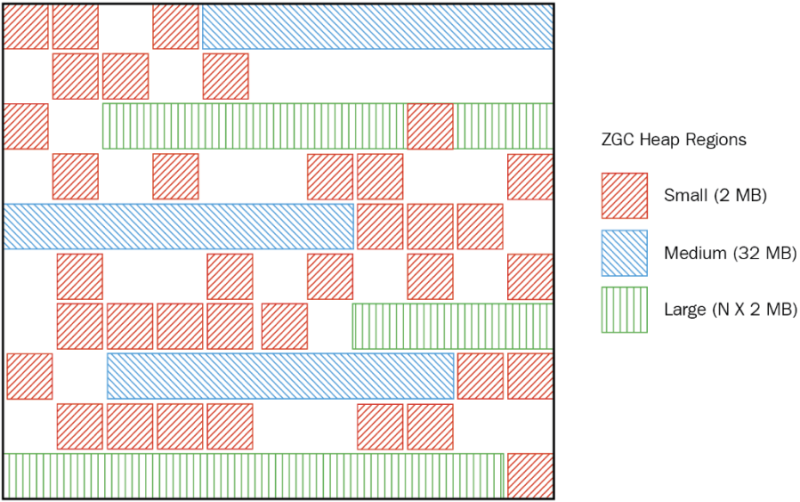 https://d2.naver.com/helloworld/0128759
https://d2.naver.com/helloworld/0128759
여기서는 저 블럭 하나하나를 region이 아니라 ZPage라고 부른다. 여기선 그냥 페이지라 부르겠다.
특이하게 세대별 구분이 존재하지 않고, 크기의 구분만이 존재한다.
세대의 구분이 없는건 특별한 이유가 있는건 아니고, 그냥 힘들어서 안넣은거다. 그래서 나중에 세대별 ZGC란게 따로 나왔다. (Java 21)
ZGC를 대표하는 특징 중 하나는 colored pointer다.
예전에는 GC 관련된 정보를 저장할때 객체 헤더에다가 정직하게 때려넣었다. 객체의 세대나 해시코드, 그런거 말이다.
ZGC는 그런 메타 정보를 포인터에다가 때려박는다.
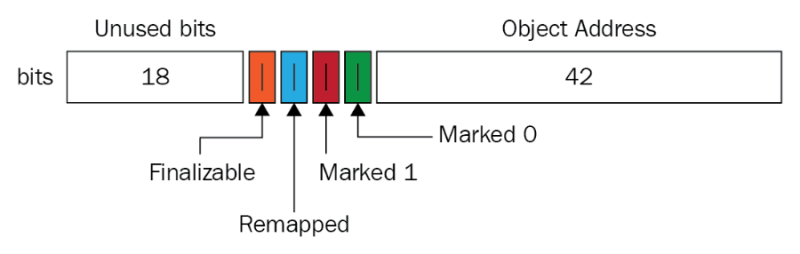 https://www.oreilly.com/library/view/java-11-and/9781789133271/99bc8b28-9595-4065-aec8-5eaddddbdda4.xhtml
https://www.oreilly.com/library/view/java-11-and/9781789133271/99bc8b28-9595-4065-aec8-5eaddddbdda4.xhtml
64비트 플랫폼에서는 주소에 보통 여유 비트가 좀 남는다는걸 활용한 트릭이다.
보통 amd64에서는 256TB(48비트) 제약이 있고, 리눅스는 128TB(47비트)의 제약이 있다.
windows는 심지어 16TB(44비트)가 한계다.
ZGC에서는 그냥 일반적인 하한선인 16TB(44비트)로 제약을 걸고, 저렇게 4비트를 구겨넣어버린다.
저 그림은 42비트라 쓰여있는데, 옛날 버전인거같다.
아무튼 컬러포인터 비트를 단순 마킹용으로만 쓰는건 아니고, 각각의 비트를 기반으로 가상주소들을 만들어쓴다.
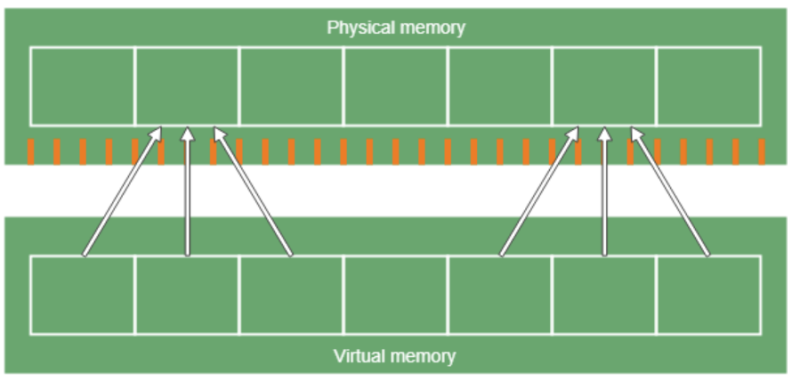 marked0, marked1, remapped 3가지 비트를 주로 사용하기 때문에 3가지 가상주소가 추가로 나온다. 물론, 가라로 만든 가상주소이기 때문에 주가적인 메모리 매핑 작업을 직접 또 한다.
marked0, marked1, remapped 3가지 비트를 주로 사용하기 때문에 3가지 가상주소가 추가로 나온다. 물론, 가라로 만든 가상주소이기 때문에 주가적인 메모리 매핑 작업을 직접 또 한다.
linux에 한해서는 mmap을 사용해서 가상주소의 접근 속도를 최적화한다.
아무튼 돌아가서, ZGC는 크게 4가지 스텝으로 실행된다.
모든 스텝은 User 스레드를 통째로 차단하지는 않지만, 중간마다 약간의 정지포인트가 있다.
- 동시 mark
- 동시 재배치 준비
- 동시 재배치
- 동시 재매핑
1. 동시 mark
모든 객체 그래프를 탐색하며 도달가능성을 분석한다. 약간의 일시정지가 발생할 수 있다.
여기에서 컬러포인터에 마킹을 한다.
2. 동시 재배치 준비
청소할 페이지들을 골라서 relocation set이란걸 만든다.
리전 안의 생존자들을 옮기고 page를 치울지 여부만 결정한다.
3. 동시 재배치
가장 핵심적인 단계다.
relocation set의 생존자들을 새 페이지로 옮기고, 페이지의 테이블 정보에 그 이동 관계를 기록한다.
컬러포인터 덕분에 객체가 relocation set에 속하는지 더 빠르게 알 수 있다.
User 스레드가 이동중인 값에 접근하려 들면 메모리 베리어와 이동 기록을 기반으로 올바르게 바로잡는다. 이래서 동시성 문제가 적다.
4. 동시 재매핑
relocation set에 있던 이주자들을 가리키던 참조들을 찾아서, 새 페이지의 새 주소로 재매핑한다.
게다가 이 과정은 별로 급한게 아니라 lazy하게 이뤄진다.
그것뿐만 아니라 아예 1단계와 통합해서 동시에 실행하기까지 한다. 이를 통해 객체 풀스캔 부하를 줄인다.
물론 ZGC에도 단점은 있다. 평균적인 처리량이 G1GC에 비하면 좀 떨어지는 편이다.
코어를 쥐어짜는 것도 있고, 빠른 정리를 위해 할당 단계에서 하는게 많아서 메모리 할당 자체가 느려진 것도 크다.
GC 옵션 사용해보기
java.exe로 코드를 실행하는 시점에 GC 옵션을 줘서 동작 방식을 선택할 수 있다.
자세한 사용법은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223619188163
참조
https://d2.naver.com/helloworld/0128759
https://stackoverflow.com/questions/31684862/how-fast-is-the-go-1-5-gc-with-terabytes-of-ram
https://wiki.openjdk.org/display/zgc/Main
https://stackoverflow.com/questions/64252590/how-does-clr-gc-compare-to-latest-zgc-and-shenandoah-gc-on-jvm
https://stackoverflow.com/questions/25512146/how-jvm-ensures-thread-safety-of-memory-allocation-for-a-new-object
https://www.google.com/amp/s/blog.gceasy.io/what-is-javas-default-gc-algorithm/amp/
https://d2.naver.com/helloworld/1329
https://www.baeldung.com/jvm-zgc-garbage-collector