[Rust] 꼬리 호출 최적화 (Tail Call Optimization)
꼬리 호출 최적화(Tail Call Optimization)는 재귀 호출 표현법에서 사용되는 메모리/성능 비효율성을 완화할 수 있는 최적화 기법 중 하나다.
여기서는 피보나치를 예로 들어보겠다.
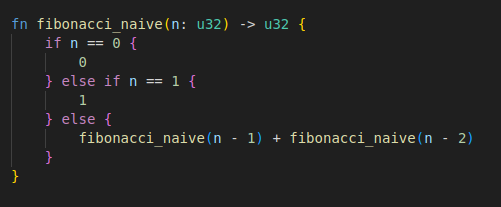
fn fibonacci_naive(n: u32) -> u32 {
if n == 0 {
0
} else if n == 1 {
1
} else {
fibonacci_naive(n - 1) + fibonacci_naive(n - 2)
}
}이런 수학적이고 재귀적인 표현이 적합한 경우에는 "표현성"과 "간결함" 측면에서는 재귀호출 표현이 뛰어나다.
근데 간결하다고 해서 효율적이란건 아니다.
재귀함수는 특성상 함수 호출 과정이 굉장히 많이 일어나는데, 함수 호출은 필연적으로 스택을 추가적으로 쌓기 때문에 스택 메모리를 비효율적으로 낭비한다. 게다가 스택 쌓고 내리고 하는 것도 실행속도에 영향을 준다.
그래서 재귀호출은 루프의 반복보다는 훨씬 느리다.
저 예제 코드의 경우에도 한 50 정도까지는 그럭저럭 실행이 되지만, 60을 넘어가면 엄청나게 느려질 것이고, 그보다 더 넘어가면 스택오버플로로 터지기 딱 좋다.
저런 형태의 코드는 어셈블리를 까봐도
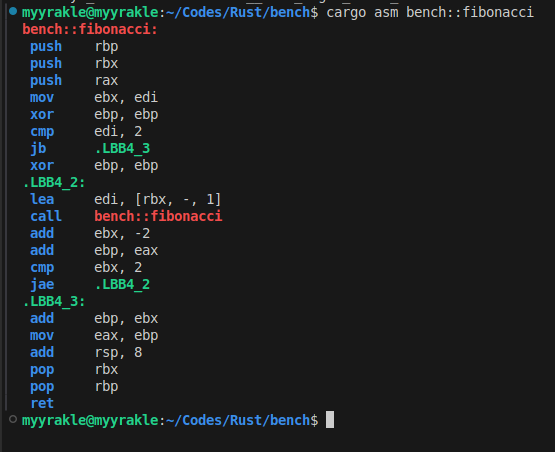 그냥 순진하게 스스로를 호출한다.
그냥 순진하게 스스로를 호출한다.
꼬리 호출 최적화
꼬리 호출 최적화는 특수하게 정의된 형태의 재귀호출 함수를 루프로 치환하는 최적화 기법이다.
재귀호출과 반복문의 장단점을 적절히 절충한 형태라고 할 수 있다.
그리고 Rust는 암시적으로 꼬리 호출 최적화를 지원한다. 직접 구현한건 아니고 그냥 LLVM에 짬때린 것 같다.
꼬리호출은 대략 다음과 같은 형태를 가진다.
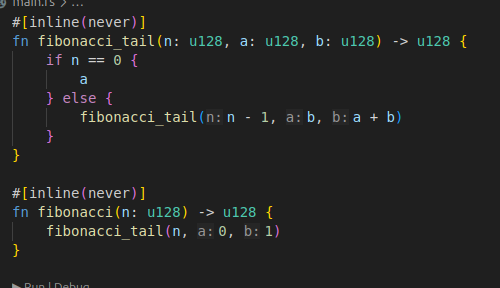
#[inline(never)]
fn fibonacci_tail(n: u128, a: u128, b: u128) -> u128 {
if n == 0 {
a
} else {
fibonacci_tail(n - 1, b, a + b)
}
}
#[inline(never)]
fn fibonacci(n: u128) -> u128 {
fibonacci_tail(n, 0, 1)
}처음 보면 이해하기 쉽지 않을 수도 있다.
원래 리턴값을 통해 상위 호출자로 결과를 넘기던 것을, 이제는 파라미터를 통해 계승하도록 바뀌었다.
그래서 이제 이걸 어셈으로 까보면
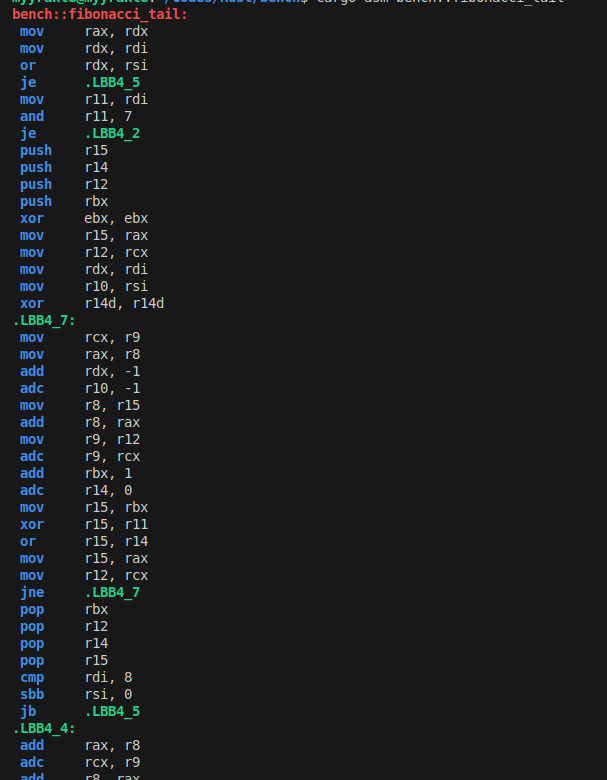 이제는 재귀호출이 전부 라사지고 단순한 점프 구문만 남았다.
이제는 재귀호출이 전부 라사지고 단순한 점프 구문만 남았다.
루프로 치환된 것이다.
이러면 이제 Stackoverflow 문제도 없어졌을뿐만 아니라, 성능도 압도적으로 증가한다.
 원래는 60만 넘겨도 거의 뻗던 것이, 1000을 넘게 넘겨도 1초 미만으로 완료된다.
원래는 60만 넘겨도 거의 뻗던 것이, 1000을 넘게 넘겨도 1초 미만으로 완료된다.
보장하지 않음 (No Guarantee)
아직 Rust는 꼬리 호출 최적화를 명시적으로 지원하지는 않는다.
LLVM 최적화 패스에 기대서 어쩌다보니 나오게끔 되어있는 거지, Rust가 명시적인 최적화 보장을 제공해주거나 하는건 없는 것이다.
예전에 Tail Call에 대한 보장을 문법적으로 지원하려고 be/become 같은 키워드를 예약해두긴 했는데, 현재로서는 요원하다. 우선순위가 굉장히 낮게 잡혀서 작업이 전혀 진행되지 않고 있는 것 같다.
https://rust-lang.github.io/rfcs/0601-replace-be-with-become.html
아무튼 그래서 Tail Call Optimization이 적용되었는지를 검증하는 가장 확실한 방법은, 위처럼 어셈블리를 까보는 것이다.
혹은 매크로 기반으로 Tail Call이 잘 적용되는 형태의 정형화되 코드를 생성해주는 crate이 하나 있다.
이런걸 써도 된다.
https://docs.rs/tailcall/latest/tailcall/
참조
https://docs.rs/tailcall/latest/tailcall/
https://stackoverflow.com/questions/59257543/when-is-tail-recursion-guaranteed-in-rust