데이터베이스와 MVCC
MVCC는 DB에 있어서 중요한 근간 중 하나다.
이걸 모르면 DB에 대해서 안다고 할 수 없다.
MVCC란?
MVCC는 다중버전 동시성 제어(MultiVersion Concurrency Control)의 준말로, write나 read가 동시적으로 들어왔을 때 발생하는 문제에 대응하기 위한 기반 구조를 말한다.
흔히 ACID라고 부르는 RDB들의 요구사항을 충족시키기 위해 존재하기도 한다.
데이터가 수정되거나 삭제되더라도 트랜잭션에 기반해 언제든 롤백할 수 있어야 하고, 트랜잭션들이 서로 다른 시점의 데이터를 조회할 수 있어야 하기 때문이다.
MVCC를 구현하는 방법은 DB 구현체마다 크게 다르고, 그 방식에 따라서 DB 자체의 한계나 운영 방식이 결정되기도 해서 서버 측 개발자라면 좀 아는게 좋다.
PostgreSQL의 MVCC
PostgreSQL은 어떻게 보면 가장 단순하고 직관적인 방법으로 MVCC를 구현했다고 말할 수 있다.
실제로 모든 삽입/수정/삭제에 대해서 새 데이터를 생성하고, 새 버전을 지정해서 버전 기반으로 데이터에 접근하도록 한 것이다.
그래서 일반적으로 PostgreSQL의 update는 update가 아닌 append이며, delete는 데이터를 실제로 제거하지 않는다.
이것 때문에 PostgreSQL에는 저 쓰레기를 정리하는 vacuum이라는 관리 포인트가 존재한다.
https://blog.naver.com/sssang97/223617798663
MySQL과 Oracle의 방법
MySQL과 Oracle은 MVCC를 달성하기 위해 Undo Segement라는 특수한 영역을 할당해서 사용한다.
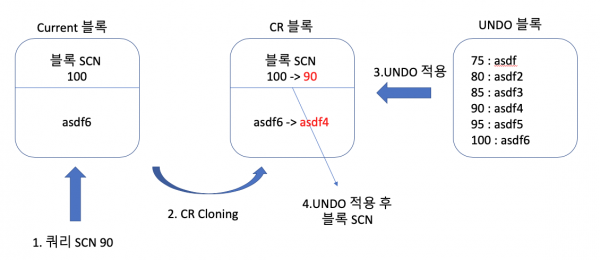 특정 Row의 데이터가 변경된다면, 그 변경사항을 Linked List로 줄줄이 이어서 할당하는 것이다.
특정 Row의 데이터가 변경된다면, 그 변경사항을 Linked List로 줄줄이 이어서 할당하는 것이다.
기본적으로 최신 버전의 데이터를 가리키나, 예전 버전의 데이터가 필요하다면 체인을 타고 이전 버전으로 시간여행을 할 수 있다.
그리고 Transaction Rollback이 발생했을 때도 Undo Segment를 통해서 과거 데이터로 롤백을 한다.
어떻게 보면 PostgreSQL과 비슷하다고 할 수도 있지만, 구조가 좀 다르다.
이건 최신 버전만을 테이블 자체에 보관하고, 이전 데이터는 일종의 로그 공간에 따로 저장하는 것이다.
이것들도 PostgreSQL의 vacuum과 마찬가지로 관리포인트가 존재한다.
MySQL은 OPTIMIZE TABLE/PURGE를 사용해서 낭비되는 디스크 공간을 회수해야 하고, Oracle도 SHRINK SPACE 같은 명령을 사용해야 한다.
사실 auto vacuum처럼 자동으로 정리하는게 없다 뿐이지, 이것들도 수동 관리 지점은 명확히 존재한다.
MSSQL(SQL Server)도 MySQL과 비슷한 방법을 사용하고, CockroachDB, MongoDB(WiredTiger) 등 많은 DB들이 이에 기반한 방법론을 사용한다.
MySQL vs PostgreSQL
그러면 이 2가지 방식은 어떤 부분에서 장점과 단점을 갖고 있을까?
딱 짚어서 말할 수는 없고, 서로 일장일단이 있는 편이다.
vacuum 같은 정리작업에 있어서는 PostgreSQL이 부하가 좀 큰 편이다.
- mysql은 정리해야할 예전 버전 데이터를 찾아서 지우기가 비교적 가볍고 쉽다. 테이블 데이터에 바로 이전버전에 대한 히스토리가 잘 남아있기 때문이다.
- 반면 postgresql은 그런 구조가 아니라서, 제대로 정리를 하려면 거의 풀스캔이나 그에 준하는 작업을 해야 한다. 역사적으로 쌓여있는 쓰레기들이 얼마나 있는지 바로 추적할 방법이 그리 많지 않기 떄문이다. 그래서 postgresql은 정리 작업이 좀 무거운 편이다.
update 같은 작업에 있어서는 mysql의 방식이 조금 비효율적일 수 있다.
- postgresql은 update가 단순한 새 버전의 append이기 때문에, 거의 단일 작업으로 update가 이루어진다고 볼 수 있다.
- 그런데 mysql의 경우에는 새 버전으로 update도 해줘야 하고, undo segment에 기존 버전을 옮겨넣는 작업까지 함께 해줘야 한다. 그래서 크게 2개의 작업으로 이루어진다고 볼 수 있다.
번외: Timestamp-based concurrency control
타임스탬프 기반 동시성 제어(Timestamp-based concurrency control)는 낙관적 동시성 제어(Optimistic concurrency control)의 일종이다.
DB에서 동시성을 관리하는 방법에 MVCC만 있는 것은 아니다.
요즘에 사용되는 꽤 많은 NoSQL DB들은 타임스탬프에 기반한 동시성 관리 또한 사용한다.
방법론은 어렵지 않다. 모든 트랜잭션에는 생성시의 타임스탬프가 할당되는데, 충돌이 발생한다면 "가장 최신의" 데이터가 반영되도록 하는 것이다.
MVCC에서 비관적인 락을 걸고 버전을 쌓으면서 구버전, 신버전 가리키면서 처리하는 것과 대비되기 때문에 낙관적인 형태의 동시성 구조라고 부르기도 한다.
DB 입장에서는 적은 딜레이로 좀더 빠르고 확장성 있게 데이터를 받을 수 있지만, Application 수준에서 처리할 게 많아진다는게 단점이다.
CassandraDB, Couchbase, DynamoDB, Elasticsearch 등의 DB들이 이러한 방식을 취한다.
보통 분산시스템을 표방하는 DB들이 이런 방식을 사용한다.
참조
https://stackoverflow.com/questions/57746567/try-to-understand-mvcc
https://stackoverflow.com/questions/6235268/a-question-about-oracle-undo-segment-binding
https://lefred.be/content/a-graph-a-day-keeps-the-doctor-away-mysql-history-list-length/
https://stackoverflow.com/questions/25153532/why-is-it-a-vacuum-not-needed-with-mysql-compared-to-the-postgresql
https://www.enterprisedb.com/blog/mysql-vs-postgresql-part-2-vacuum-vs-purge
https://www.cockroachlabs.com/blog/mvcc-range-tombstones/
https://hoing.io/archives/6576
https://aws.amazon.com/ko/compare/the-difference-between-cassandra-and-mongodb/
https://www.cs.cmu.edu/~pavlo/blog/2023/04/the-part-of-postgresql-we-hate-the-most.html