[Elasticsearch] 인덱스 구조
이 글에서는 Elasticsearch, 더 나아가 Lucene에서 인덱스를 어떻게 구성하고 스캔하는지를 간단히 정리해본다.
보통 Elasticsearch를 가리켜 검색엔진용 DB라고 하고, Inverted Index 기반으로 고성능의 텍스트 검색을 지원하는 DB라고도 한다.
Inverted Index에 대한 것은 별도 포스트를 참조한다.
https://m.blog.naver.com/sssang97/223639069654
하지만 Elasticsearch의 특별함은 Inverted Index에만 기인한 것은 아니다.
Inverted Index 자체는 DB 세계에서 생각보다 평범하고 흔한 구조고, 심지어 RDB들도 Inverted Index 자체는 무난하게 지원하기도 한다.
의문
그런데 Elasticsearch의 경우에는 매우 복잡한 필터 조건과 정렬 조건에 대해서도 꽤 뛰어난 성능을 발휘한다.
전통적인 RDB들이 최대한의 성능을 내기 위해서는 사용사례에 맞는 커버링 인덱스를 하나씩 만들어줘야 하는 것과 대비된다.
Elasticsearch는 RDB들과 어떤 차이가 있길래 모든 조합의 필터 조합에도 빠른 것처럼 보이는 걸까?
Inverted Index는 그냥 텍스트 검색을 위한 것이라서 이런 것과는 연관이 없고, Elasticsearch만의 복잡한 인덱스/최적화 구조가 있기에 가능한 것이라 할 수 있다.
Elasticsearch/Lucene이 이를 달성한 방법을 간략하게 정리해보겠다.
Apache Lucene
Elasticsearch는 Lucene을 기반으로 한 검색엔진 시스템이다. 사실 Elasticsearch이 자랑하는 고성능 인덱스 능력은 전부 Lucene에서 나오는 것이다.
좀 더 상세하게 내려가보면, Elasticsearch와 Lucene의 관계는 이렇게 펼쳐진다.
 Elasticsearch의 인덱스는 알다시피 샤드 단위로 데이터를 분할하는 기능을 제공하고, 덕분에 대규모 수평 확장에 용이한 편이다.
Elasticsearch의 인덱스는 알다시피 샤드 단위로 데이터를 분할하는 기능을 제공하고, 덕분에 대규모 수평 확장에 용이한 편이다.
바로 여기서 각각의 인덱스 샤드가 Lucene Index인 것이다.
이런 관점에서 보면, Elasticsearch가 제공하는 것은 Lucene Index를 샤딩해주고 쿼리 결과를 조합해주는 그럴듯한 껍데기라 할 수 있다.
아무튼 여기선 Lucene의 구조에 대해서 주로 설명을 해보겠다.
Index Segment
 바로 위에서도 봤지만, 루씬 인덱스는 내부적으로 수많은 "인덱스 세그먼트"들로 구성된다.
바로 위에서도 봤지만, 루씬 인덱스는 내부적으로 수많은 "인덱스 세그먼트"들로 구성된다.
루씬 인덱스는 검색을 할때 document에서 바로 가져오는게 아니라, 여러개의 세그먼트에서 각각 데이터를 가져온 다음에 조합해서 사용한다.
여기서 좀 특이한 점은, 세그먼트들은 수정이란 개념이 없다는 것이다.
이는 최적화를 위한 선택 중 하나라고 할 수 있다.
유연성을 잃는 대신에 다음을 얻었다.
- 세그먼트는 생성 후 수정되지 않으므로 파일 수준 캐시에 친화적이다.
- 세그먼트는 변경되지 않으므로 동시성 문제에서 자유롭다. 동시 쓰기로 인해 발생하는 부작용들이 존재하지 않고, 동시 읽기도 매우 빠르게 처리할 수 있다.
삽입(Insert)
세그먼트는 수정이란 개념이 존재하지 않는다고 했었다.
그래서 루씬의 데이터 삽입은 필연적으로 새로운 세그먼트의 생성으로 이어진다.
근데 데이터 하나 넣을때마다 세그먼트를 하나씩 만드는건 비효율적이기 때문에 가급적 삽입은 몰아서 한번에 대량처리를 하는 것이 권장된다.
삭제
루씬 인덱스에서 데이터의 삭제는 즉시 반영되지 않는다. "가짜 삭제" 플래그를 0/1 비트로 표시하고, 읽을때 무시하게 할 뿐이다.
물론 주기적으로 세그먼트 병합을 거치면서 최종적으로 삭제를 해주긴 한다.
수정
Lucene의 데이터 Update는 다른 DB들에 비해서 그 효율성이 매우 낮은 편이다.
사실 Lucene에는 "수정"이란 동작은 존재하지 않는다. 기존 데이터를 "가짜 삭제"로 표시한 후에 새 데이터를 Insert하는 것이다.
아무튼 Lucene의 Update가 비효율적이란 것만 알면 된다.
Bitset과 Filter 캐싱
Lucene은 텍스트 검색이나 스코어링을 빼더라도, 필터 성능 또한 꽤 훌륭한 편이다.
사실 이런 뛰어난 필터 성능은 적극적인 캐싱에서 나온다.
일단 최초로 필터가 들어왔을 때는 캐시 없이 다 확인해서 내려줄 것이다.
하지만 결과를 버리지 않고, 필터쿼리와 그 결과를 부분적으로 캐싱한다. 해당 필터에 대한 결과를 Bitset으로 컴팩트하게 저장하고, 동일한 필터 쿼리가 들어온다면 그걸 다시 들고서 재사용하는 것이다.
여기서 Bitset은 [0,0,1,0,1,1...] 같은 순수한 비트 시퀀스고, 비트 기반으로 저장하기 때문에 비교적 크기가 작게 저장된다.
아무튼 이 뛰어난 필터 성능도 결국 디스크나 메모리를 더 쓰는 것으로 내는 것이라고 할 수 있겠다.
모든 것은 트레이드오프다.
Skip List 기반의 인덱싱
Lucene은 다른 DB들과 다르게 Skip List를 기반으로 인덱싱 동작을 구현한다.
NoSQL을 포함한 대부분의 DB들이 Tree 기반 구조를 인덱스로 사용하는 것과 대비된다.
리밸런싱
Tree를 쓰지 않은 가장 큰 이유는 리밸런싱이다.
스킵리스트에는 트리 특유의 고질적인 오버헤드인 리밸런싱 비용이 적다. 리밸런싱이 일어나면 트리에 속한 데이터들을 잠가서 사용중단해야 할 수도 있는데, 그런 게 없는 것이다.
이를 통해 동시성 성능을 개선한다.
읽기성능
스킵리스트도 일반적인 읽기성능은 Tree에 밀리지 않는 O(log N) 정도로 나온다.
Iteration
스킵리스트를 쓰는 것에는 루씬의 추상화 구조와도 연관이 있다.
루씬은 데이터를 로드해서 처리할때 iteration 기반으로 데이터를 처리한다.
DocValues
루씬은 sort나 aggregate에 대해서도 꽤 훌륭한 성능을 제공한다.
이러한 최적화는 DocValues라는 column base 저장 구조를 통해서 이루어진다.
이건 데이터들을 행단위로 저장하는게 아니라, 열 단위, 필드별로 저장해서 매핑한다.
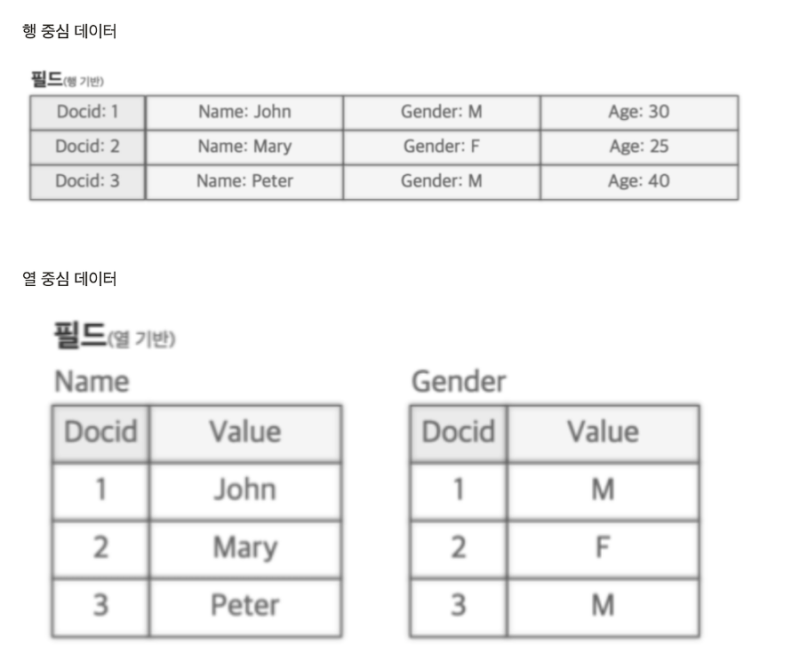 https://ksk-developer.tistory.com/m/29
https://ksk-developer.tistory.com/m/29
만약 Gender라는 값으로 정렬을 한다면, Gender 순으로 정렬된 DocID만 빠르게 가져와서 그 순서대로 정렬을 처리하는 것이다.
그리고 이 구조는 메모리를 직접적으로 사용하지 않고 OS 수준 파일시스템 캐시를 적극적으로 사용한다.
이 덕분에 메모리 사용량을 줄이면서도 꽤 괜찮은 성능을 낼 수 있다.
BKD-Tree
루씬은 인덱싱에 BKD 트리라는 다차원트리를 사용한다.
이건 좌표검색에도 쓰이지만 숫자 범위 검색에도 적극적으로 사용된다.
0-5 같은 작은 범위의 검색이 아니라, 간격이 수만-수십만에 달하는 범위를 검색할 때 이 Tree를 통해 데이터를 스캔한다.
B-Tree처럼 디스크 기반으로 동작하지만, 데이터를 직사각형 형태의 셸로 재귀적 분할해서 데이터를 관리하는게 특징이다.
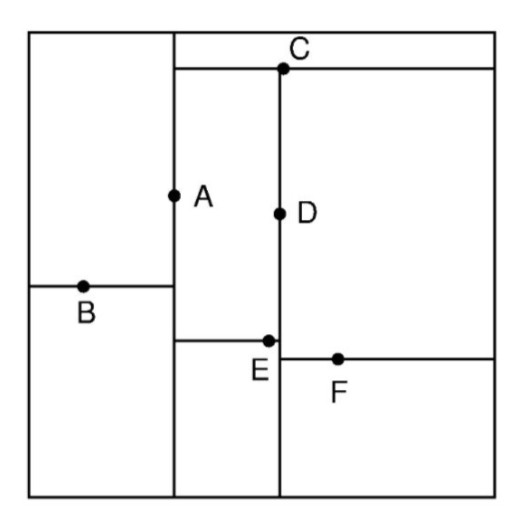 이전까지는 2-3차원 좌표상의 검색에나 주로 쓰였었는데, 1차원 범위 검색에도 꽤 뛰어난 성능을 발휘한다는게 입증돼서 루씬에도 들어갔다.
이전까지는 2-3차원 좌표상의 검색에나 주로 쓰였었는데, 1차원 범위 검색에도 꽤 뛰어난 성능을 발휘한다는게 입증돼서 루씬에도 들어갔다.
하지만 이건 다른 구조들과는 다르게 스캔의 결과로 정렬되지 않은 데이터를 가져온다. 그래서 BKD로 스캔한 데이터는 추가적인 정렬 프로세스를 한번씩 거친 후 사용된다.
교집합과 합집합
Lucene은 RDB처럼 필요한 조합에 대한 커버링 인덱스를 하나하나 만들 필요 없이도 거의 모든 형태의 필터에 대해 뛰어난 성능을 발휘하는 것 같다.
이는 위에서 언급했던 bitset, skip list 등 다양한 요인이 있지만, 최적화 트릭들을 이것저것 많이 사용해서 그걸 여기서 다 다룰 수는 없을 것 같다.
일단, 루씬은 모든 조합에 대한 가능한 인덱스 조합을 다 만들거나 그러지는 않는다.
필터+쿼리가 들어오면 위에서 다뤘던 여러가지 스캔 방식을 때에 맞춰 쓰고, 각각의 부분집합들을 모아다가 교집합이나 합집한 연산을 거쳐 결과를 완성하는 것이다. 여기에서는 DB에서 Sort-merge join하는 것과 비슷한 접근법을 응용한다.
디스크와 메모리 사용량
루씬의 빠른 검색 성능은 공짜로 이루어지는 것이 아니다. 여러가지 형태의 인덱스와 캐시를 저장하는 것으로, 루씬은 다른 DB에 비교하면 디스크 사용량이 큰 편이다.
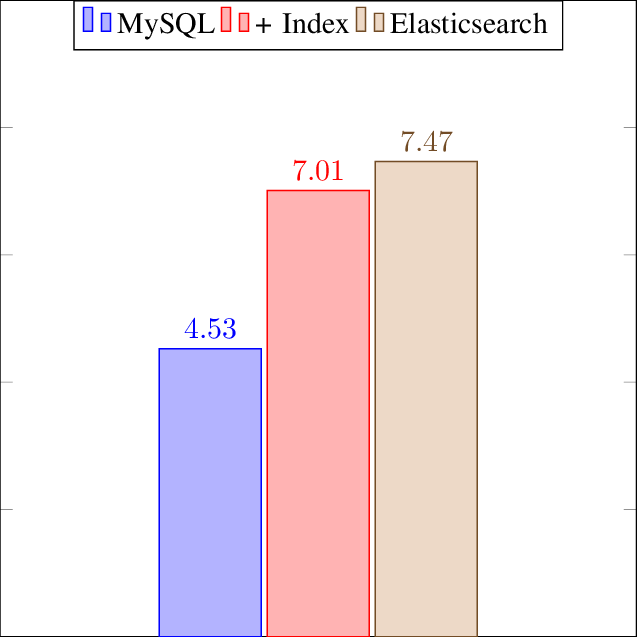 데이터 형태에 따라 다르겠지만, 두배 가까이도 벌어질 수 있다.
데이터 형태에 따라 다르겠지만, 두배 가까이도 벌어질 수 있다.
디스크뿐만 아니라 메모리도 많이 먹는 편이다. 메모리 낭비를 줄이기 위해 디스크 기반의 인덱싱을 많이 하긴 하지만, 결국 복잡한 조건으로 이래저래 가공해서 빠르게 결과를 만들려면 메모리가 많이 필요하다.
그래서 Elasticsearch는 기본 메모리 사양이 꽤 높은 편이다. 데이터 규모가 커지면 커질수록 급격이 증가한다.
참조
https://stackoverflow.com/questions/22617674/does-elasticsearch-have-compound-indexes
https://www.elastic.co/kr/blog/lucene-points-6-0
https://www.elastic.co/kr/blog/found-elasticsearch-from-the-bottom-up
https://www.reddit.com/r/rails/comments/66q413/why_is_elastic_search_faster_at_querying_compared/
https://j.blaszyk.me/tech-blog/exploring-apache-lucene-index/
https://j.blaszyk.me/tech-blog/exploring-apache-lucene-search-and-ranking/
https://j.blaszyk.me/tech-blog/exploring-apache-lucene-scale/
https://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html?m=1
https://stackoverflow.com/questions/2602253/how-does-lucene-index-documents
https://stackoverflow.com/questions/66804510/lucene-index-modeling-why-are-skiplists-used-instead-of-btree
https://stackoverflow.com/questions/256511/skip-list-vs-binary-search-tree/28270537#28270537
https://www.elastic.co/kr/blog/all-about-elasticsearch-filter-bitsets
https://stackoverflow.com/questions/7693897/how-does-lucene-calculate-intersection-of-documents-so-fast
http://philosophyforprogrammers.blogspot.com/2010/09/lucene-performance.html?m=1
https://alibaba-cloud.medium.com/analyzing-elasticsearch-performance-with-lucene-76245ee2f347
https://medium.com/swlh/bkd-trees-used-in-elasticsearch-40e8afd2a1a4
https://www.elastic.co/kr/blog/apache-lucene-numeric-filters
https://issues.apache.org/jira/plugins/servlet/mobile#issue/LUCENE-6697
https://www.elastic.co/kr/blog/lucene-points-6-0