[Database] Offset과 성능 문제
 RDB, NoSQL을 불문하고 데이터를 N번째부터 걸러서 조회하는 기능들은 다 제공된다.
RDB, NoSQL을 불문하고 데이터를 N번째부터 걸러서 조회하는 기능들은 다 제공된다.
용어는 offset, skip 등 몇가지가 있지만 근본 원리나 동작 방식은 대동소이하다.
근데 문제는 이게 결과가 배열에서 인덱싱하는 것처럼(arr[i:]) 보인다고 해서, 정말 배열처럼 동작하는게 아니라는 것이다.
배열은 그냥 메모리에 전부 로드해놓고 쓰니까 어느 지점에서의 직접 접근이든 빠른 성능을 보장할 수 있지만, 데이터베이스들은 소스가 디스크에 있고 필터도 있기 때문에 그리 간단하지만은 않다.
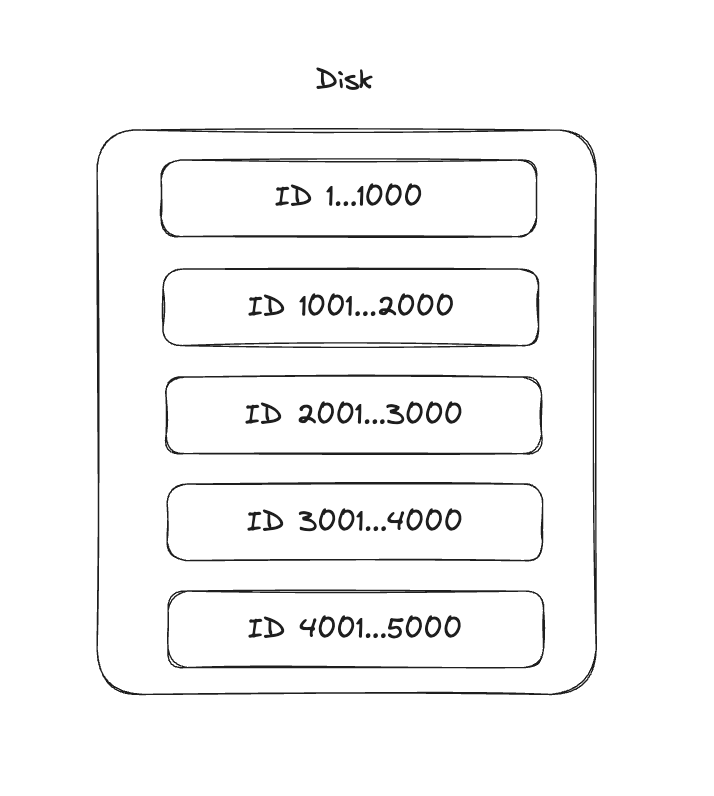 이렇게 데이터가 5000개 정도 있다고 가정해보자
이렇게 데이터가 5000개 정도 있다고 가정해보자
그리고 저기서 데이터를 1000개씩 가져온다 치면, 쿼리를 이렇게 날릴 것이다.
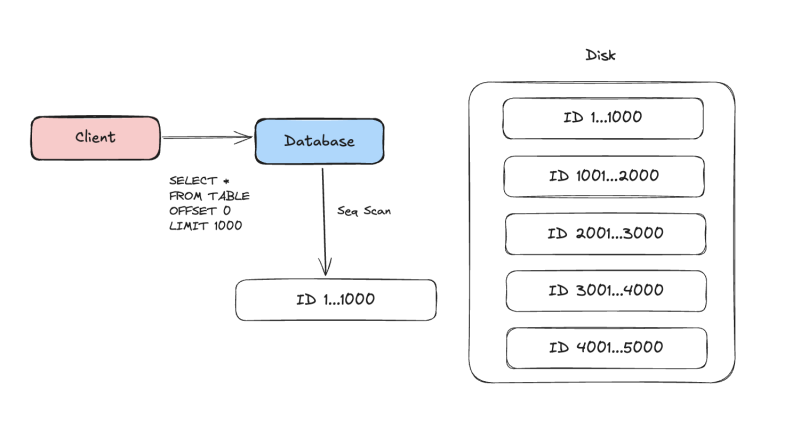 이렇게 오프셋이 0일때는 문제가 없다.
이렇게 오프셋이 0일때는 문제가 없다.
딱 1000개만 스캔해서 빠르게 가져온다.
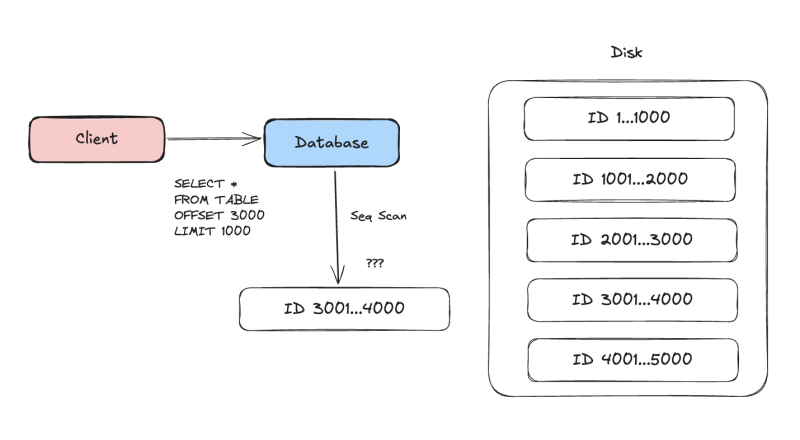 근데 좀 건너뛰어서 3000-4000을 조회하려고 한다면 어떻게 동작할까?
근데 좀 건너뛰어서 3000-4000을 조회하려고 한다면 어떻게 동작할까?
딱 3000부터 순서대로 가져올 거라고 기대할 수도 있지만, 그렇지 않을 확률이 더 높다.
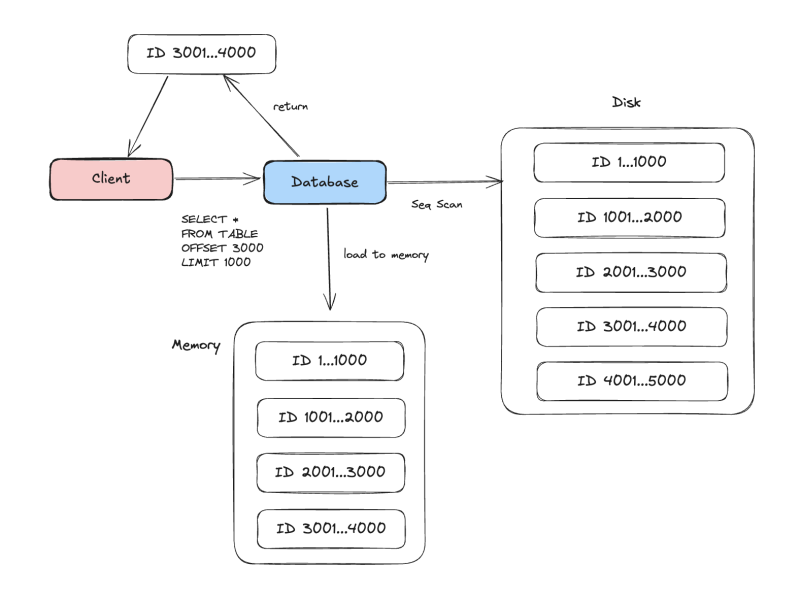 대부분의 데이터베이스는 이 상황에서, 처음부터 다 스캔한 다음에 그 메모리 뭉치에서 마지막 3000번째부터를 잘라서 반환한다.
대부분의 데이터베이스는 이 상황에서, 처음부터 다 스캔한 다음에 그 메모리 뭉치에서 마지막 3000번째부터를 잘라서 반환한다.
RDB의 경우에는 LIMIT/OFFSET이 가장 마지막에 처리되는 프로세스고, 애초에 DB 입장에서는 디스크에서 데이터를 로드하지 않고서는 3000번째 데이터가 뭔지를 알 수가 없다.
그러니 일단 메모리에 다 올린 다음에 확인할 수 밖에 없는 것이다.
때문에 row가 많은 데이터에서 큰 offset으로 조회하는 쿼리는 매우 무겁고 느리게 동작한다.
딱 정렬조건에 맞는 인덱스가 컴팩트하게 걸려있고 필터가 뭐 없다면 offset 인덱스를 탈 수도 있지만, 현실세계의 쿼리들은 복잡한 필터를 수반하므로 인덱스가 걸릴 확률은 없다.
애당초 offset 자체가 필터를 거친 다음에 이뤄지는 것이기 때문에 오프셋 기준으로 딱 맞춰서 인덱스 스캔을 하는게 사실상 불가능하기 때문이다.
이건 RDB만 그런게 아니고 거의 모든 DB들이 공유하는 근본적인 한계점이다.
해결책 A: 오프셋에 최대값 지정
offset의 대표적인 사용처는 아무래도 페이지네이션일 것이다.
근데 사실 페이지네이션이 존재하는 대부분의 서비스에서는... 성능 문제때문에 그냥 페이지 접근을 어느 한도 이상으로는 하지 못하게 막는다.
네이버도 그렇고, 구글도 그렇고 다 그렇다. 이름난 서비스 중에서 페이지네이션을 무한하게 제공하는 서비스는 못본거같다.
해결책 B: 커서
아무튼 이런 성능 문제 때문에 요즘 나오는 대부분의 서비스는 페이지 숫자로 접근하는 페이지네이션 대신, "커서(cursor)" 기반의 방식을 사용한다.
무한 스크롤이라고도 부른다.
이 기법에서는, 일단 정렬 기준을 정해야 한다.
ID로 오름차순 정렬을 한다 치자
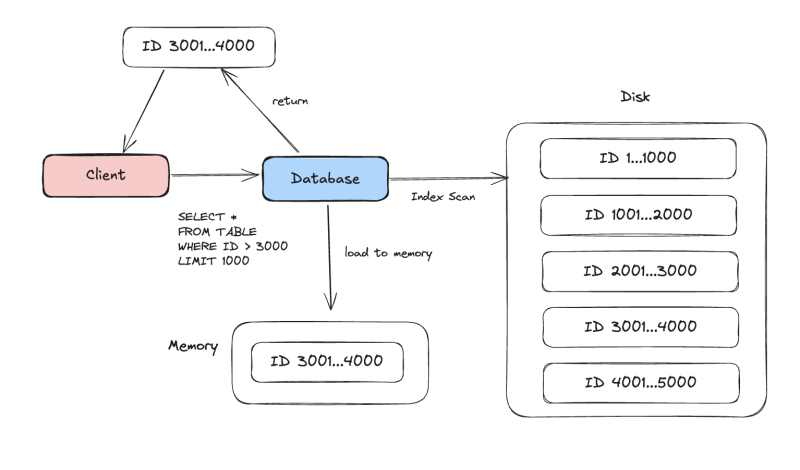 먼저 1...1000를 조회해서 받아왔다면, 그 다음에는 1000보다 큰 값을 기준으로 필터링을 하도록 하는 것이다. 여기서 전달하는 값 기준을 커서라 한다.
먼저 1...1000를 조회해서 받아왔다면, 그 다음에는 1000보다 큰 값을 기준으로 필터링을 하도록 하는 것이다. 여기서 전달하는 값 기준을 커서라 한다.
이러면 딱 3000인 지점부터 빠르게 긁어서 가져올 수 있고, 복잡한 필터가 달린 상황에서도 최적화가 비교적 수월하게 된다.
아래는 Postgres 기반의 간단한 성능테스트 예제다.
create table test_table (
id INT primary key,
num INT not null
);
insert into test_table(id, num)
select t.n, (random()*100)::INTEGER
from (
select generate_series(0, 10000000) as n
) as t;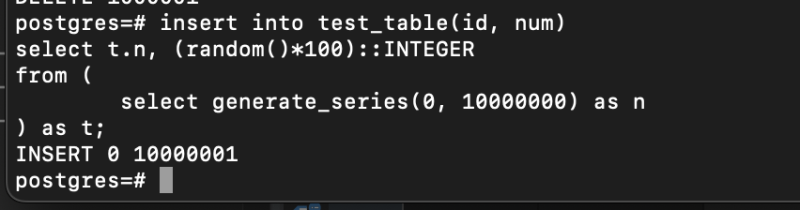 1000만개쯤 넣고
1000만개쯤 넣고
explain(analyze)
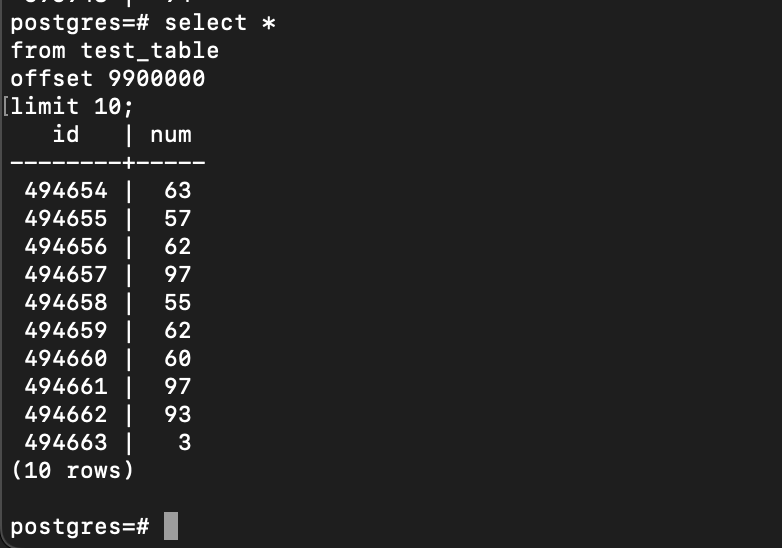
select *
from test_table
offset 9900000
limit 1000;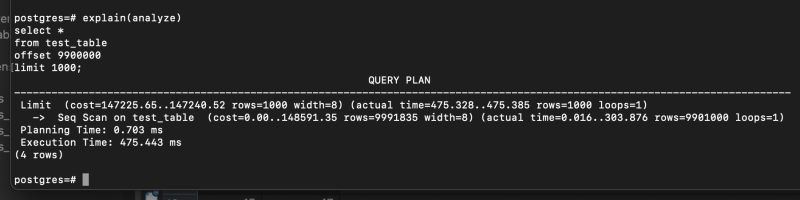 그냥 뒷부분부터 조회하면, 0.5초 가까이 걸렸다.
그냥 뒷부분부터 조회하면, 0.5초 가까이 걸렸다.
풀스캔때린다음에 맨 뒷부분까지 다 가서 조회한 것이기 때문이다.
하지만 커서 기반으로 처리하면
explain(analyze)
select *
from test_table
where id >= 9900000
limit 1000;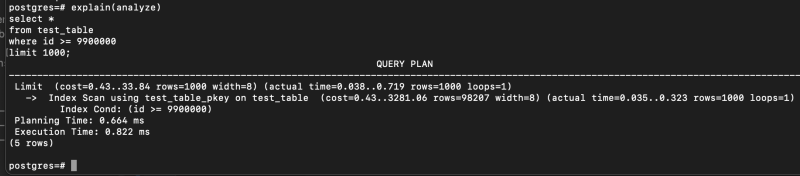 인덱스로 긁어오니 이번엔 매우 빨라졌다.
인덱스로 긁어오니 이번엔 매우 빨라졌다.
0.02초가 걸렸다.