[Clickhouse] 저장 방식과 최적화 구조
clickhouse는 bigquery나 redshift 같은 고성능 빅데이터 DB의 오픈소스 대안 중 하나다.
하드웨어만 받쳐준다면 수백 페타바이트급의 데이터도 빠르게 처리할 수 있는 능력을 갖고 있다.
clickhouse에서 데이터를 저장하고 쿼리를 최적화하는 방법에 대해서 간략히 다뤄보겠다.
Column Base 구조
기성 데이터베이스들은 데이터를 항상 디스크에 행(row) 단위로 저장하고 사용했다.
그래서 인덱스를 통해서 디스크에서 데이터를 스캔할 때도 행 단위로만 가져왔다.
column base는 반대로, 데이터를 column 단위로 쪼개서 저장하는 것이다.
그래서 column base에서 row를 가져오려면 각 column 데이터를 가져온 다음에 조합하는 형태가 된다.
column base의 장점
column base 구조는 모든 데이터를 스캔하지 않고도 특정 컬럼의 값만으로도 빠르게 데이터를 가져올 수 있다.
그래서 많은 행, 적은 열에 대해서 데이터를 가져오고, 더불어 그 결과의 크기가 작을 때는 column base 구조가 월등히 빠르다.
통상적으로 모든 필드를 볼 필요까지는 없는 집계, 통계 분석용 빅데이터 DB에 주로 사용되는 이유다.
column base의 단점
row의 column 값들을 일부가 아니라 대부분 사용해야 하는 경우(select *)는 column base가 row base보다 느리다.
그리고 최종 결과로 가져오는 row 개수가 크다거나 한 경우에도 column base가 비효율적이다.
또한 column base는 한 행의 데이터가 분산 저장되어있기 때문에 강력한 일관성이나 트랜잭션 수준을 보장하기 어렵다.
행 단위로 데이터를 insert하는 일반적인 행위도 row base에 비하면 무거운 편이다.
Primary Key와 Merge Tree
clickhouse도 기본키(Primary Key)가 존재한다.
기본키가 걸려있지 않아도 column 단위 스캔으로 꽤 빠르게 데이터를 가져올 수 있지만, 그럼에도 기본키를 기반으로 필터를 거는게 당연히 더 빠르다.
clickhouse는 기본키 알고리즘에 대해 몇가지 옵션을 제공하지만, 아무래도 가장 권장되는 기본값은 Merge Tree다.
Merge Tree는 LSM 트리와 유사한 로그-append 기반의 인덱스 구조다.
그래서 데이터의 즉시 반영을 보장하지는 않는 대신 데이터가 insert될때 read 작업들에 대해 lock을 걸지 않는다는 장점이 있다.
Merge Tree와 저장 구조
Merge Tree는 인덱스지만, 단일 row를 가리키는 일반적인 DB들의 인덱스와는 다르다.
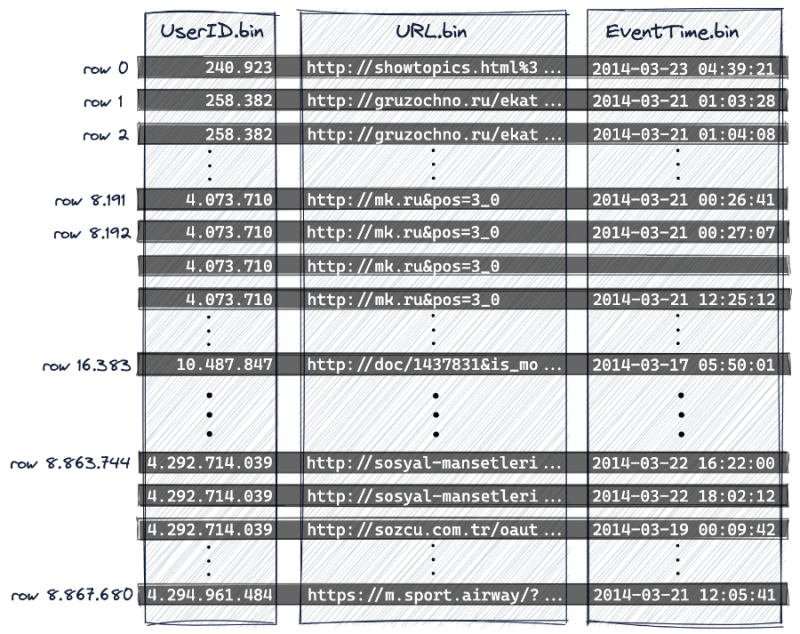
clickhouse에서는 최대 8192행의 데이터를 하나의 블록으로 묶어서 "granule"이라고 부르는데, Merge Tree는 이 각각의 granule을 가리키는 인덱스다.
 이런 구조 덕분에 거대한 데이터 세트를 스캔할 때도 하나의 블록을 메모리에 통째로 올릴 수 있고, 디스크 액세스 효율성 또한 괜찮다.
이런 구조 덕분에 거대한 데이터 세트를 스캔할 때도 하나의 블록을 메모리에 통째로 올릴 수 있고, 디스크 액세스 효율성 또한 괜찮다.
인덱스가 데이터 행을 직접 가리키지 않고 블록을 간접적으로 가리키는 이러한 접근법을 Sparse Index라고 부른다.
그리고 column base 구조이기 때문에 실제로 파일 저장도 컬럼 단위로 이루어진다.
granule도 각각의 column에 대해서 별도로 저장되는 것이다.
non-Primary Key
clickhouse는 column base 구조를 갖고 있기 때문에 기본키가 아닌 다양한 필드로 필터를 걸더라도, 꽤 빠르게 데이터를 선별해서 가져올 수 있다.
하지만 기본키 필터와 비교하면 명백하게 느릴 수 밖에 없다. 사실 Key가 아닌 필드로 필터를 걸면, clickhouse는 해당 컬럼 데이터에 풀스캔을 때린다... 그나마 행 전체를 가져오는게 아니라 특정 column을 가져오는 거라서 덜 느릴 뿐이다.
이럴때 최적화를 사용하는 기법이 Skipping Index라는 독특한 구조다.
Skipping Index
일반적인 DB들에서는 기본키 외 필터들에 대해서 최적화를 원할때 보조 인덱스를 마구잡이로 추가한다.
하지만 clickhouse에서는 디스크에 행 단위로 저장하는게 아니라 블록(granule) 단위로 저장하므로 이런 방식이 효율적으로 작동하지 않는다.
이 스타일에 맞춰서 그냥 안맞는 블록을 빠르게 버리고 지나갈 수 있게 해주는 풀스캔 방지 수단이 skipping index다.
skipping index의 생성 방식은 다음과 같다.
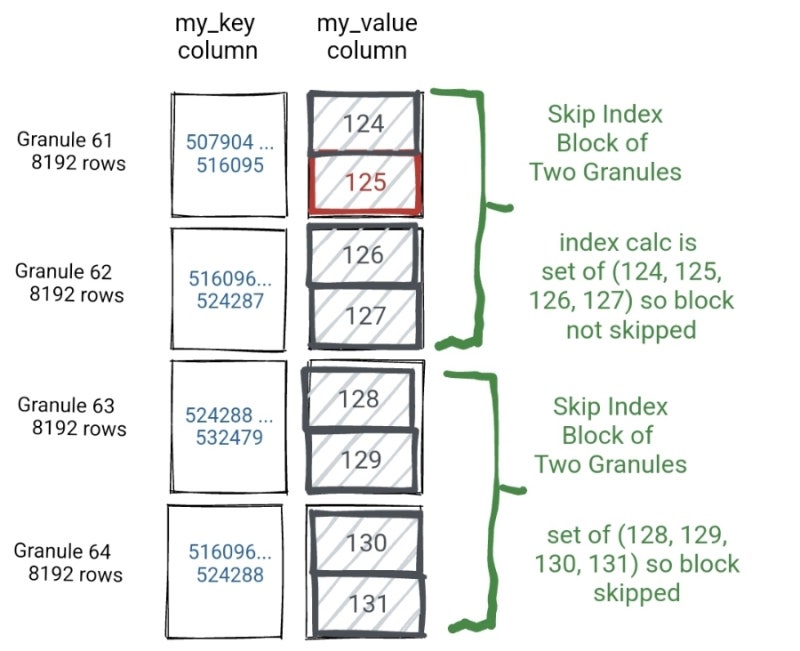
ALTER TABLE 테이블명 ADD INDEX 인덱스명 컬럼명 TYPE 인덱스타입 GRANULARITY N;skipping index는 granule을 또 몇개를 묶어서 블럭-그룹으로 만들고 관리한다.
"GRANULARITY N"에서 "GRANULARITY 4;"로 한다면 8192x4 크기가 하나의 skipping index 블럭이 되는 것이다.
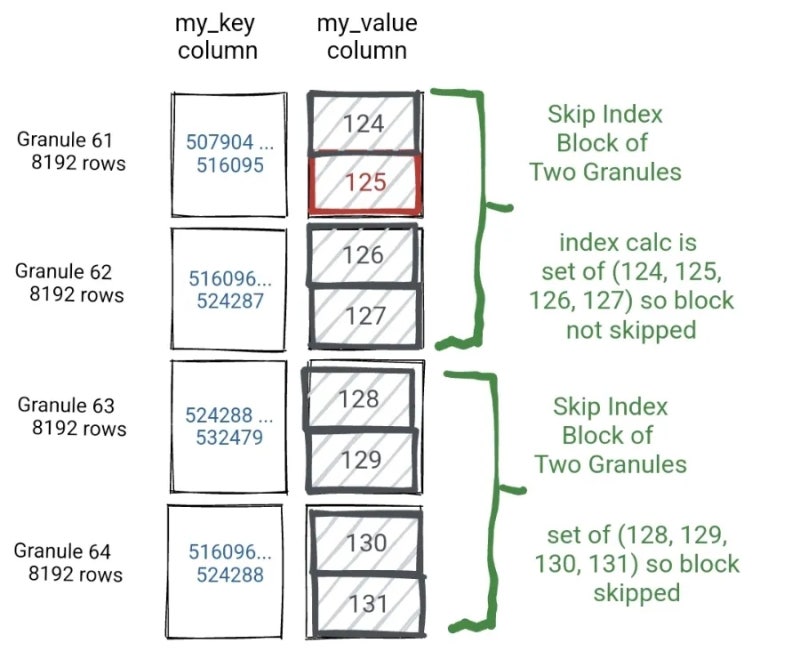 그리고 필터를 받아서 데이터를 스캔할때, 해당 skipping 블럭에 "필터에 존재하는 값이 없으면" 스캔 자체를 skip할 수 있게끔 하는 것이다.
그리고 필터를 받아서 데이터를 스캔할때, 해당 skipping 블럭에 "필터에 존재하는 값이 없으면" 스캔 자체를 skip할 수 있게끔 하는 것이다.
인덱스 타입에는 bloom_filter, minmax, set(max_rows) 등이 제공된다.
-
minmax는 가장 단순한 구조의 skipping 인덱스다.
해당 블록의 최소-최대값을 저장해두고, 거기에 걸리지 않으면 skip하게 하는 것이다.
범위기반 필터에 잘 작동한다. -
**set(max_rows)**는 단순하고 가볍지만 성능 이점에 한계가 있는 인덱스다.
여기엔 블록의 모든 값을 저장해둔다. 그리고 이 set에 필터 대상 값이 있으면 스캔하고, 없으면 skip하는 것이다.
set(0)이라면 한계 없이 저장하고, set(100)이라면 100개까지 저장한다. 한계를 정했을때 한계를 넘으면 빈 것으로 처리해서 skip을 하지 않는다. -
bloom_filter는 해시테이블의 변종인 블룸필터를 응용한 skip 구조다.
오차가 있는 알고리즘이지만 "없다"고 판단한 것은 정확하기 때문에 매우 큰 데이터에 대해서 상당히 효율적으로 skip을 처리할 수 있다.
원리에 대해서는 별도 포스트를 참조한다. https://m.blog.naver.com/sssang97/223231946274
Join 최적화
clickhouse는 테이블들을 join할때 기본적으로 hash join을 선택한다. 단, join 대상에 큰 테이블이 2개 이상 있다면 merge join을 선호한다.
참조
https://clickhouse.com/docs/en/optimize/sparse-primary-indexes
https://clickhouse.com/docs/en/about-us/distinctive-features#true-column-oriented-dbms
https://stackoverflow.com/questions/18831699/column-oriented-database-vs-row-oriented-database
https://ko.m.wikipedia.org/wiki/%EC%BB%AC%EB%9F%BC_%EC%A7%80%ED%96%A5_DBMS
https://en.m.wikipedia.org/wiki/Data_orientation
https://clickhouse.com/docs/en/optimize/skipping-indexes
https://clickhouse.com/docs/en/optimize/sparse-primary-indexes
https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree#table_engine-mergetree-data_skipping-indexes