이슈노트 #10: 서버가 너무 느려요...
1. 발단
어느날부터, 특정 서비스의 서버 응답 레이턴시가 급격하게 느려지는 문제가 발생했다.
 .png?type=w800)
밀리초 단위로 완료되어야 하는 기능들이 몇초, 혹은 몇십초까지 지연되기 시작한 것이다.
.png?type=w800)
밀리초 단위로 완료되어야 하는 기능들이 몇초, 혹은 몇십초까지 지연되기 시작한 것이다.
거의 장애에 준하는 문제였고, 바로 파악에 나섰다.
2. 분석
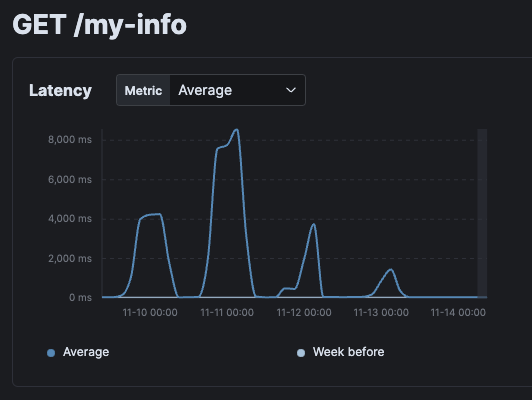
일단 현상으로 보았을때, 새 버전이 배포된 시점의 다음날 즈음부터 성능 문제가 도드라졌다.
.png?type=w800)
그리고 항상 성능 문제가 있던건 아니고, 통상적으로 유저들이 몰리는 자정-6시 정도 즈음에 성능 문제가 반복적으로, 심각하게 튀었다.
일단 뭔가 변경사항으로 인해서 문제가 생긴 것은 확실해보였다.
오고 가는 트래픽 양에는 큰 차이가 없었기 때문이다.
3. DB가 문제인가?
통상적으로 서버 API들의 레이턴시는 DB 사용에 의존적인 경우가 많으니, 일단은 DB를 먼저 의심했다.

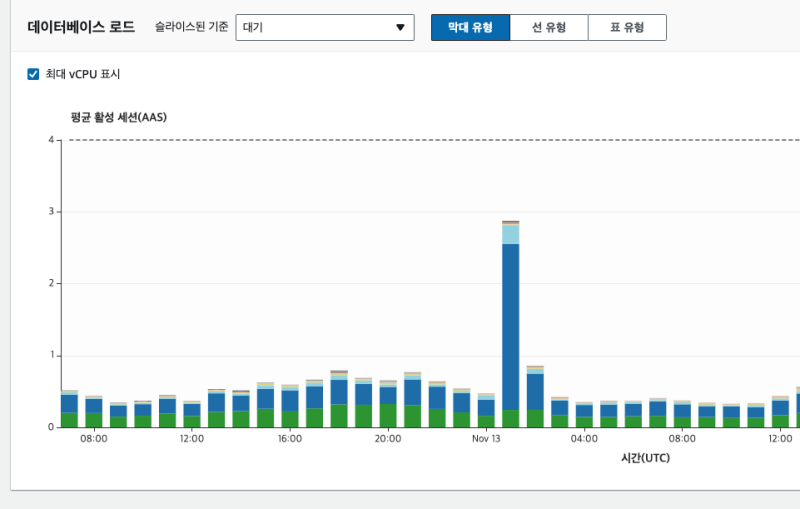 하지만 DB 자체의 리소스 메트릭에는 별반 이상이 없었고, 평소와 같았다.
하지만 DB 자체의 리소스 메트릭에는 별반 이상이 없었고, 평소와 같았다.
slow query가 발생하는 것도 딱히 없었다.
뭔가 테이블에 Lock이 걸려서 그런가 싶어서 문제 발생 시점에 Lock 걸린 목록도 다 조회해보고 그랬는데, 그것도 아니었다.
4. 서버가 문제인가?
그래서 서버 리소스를 잡아먹는 쿼리가 있어서 그런가 싶었는데,
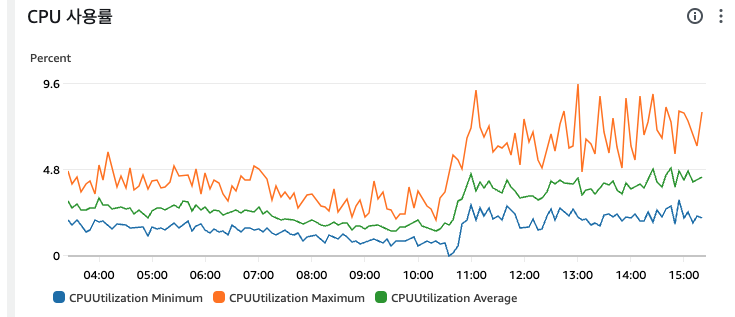
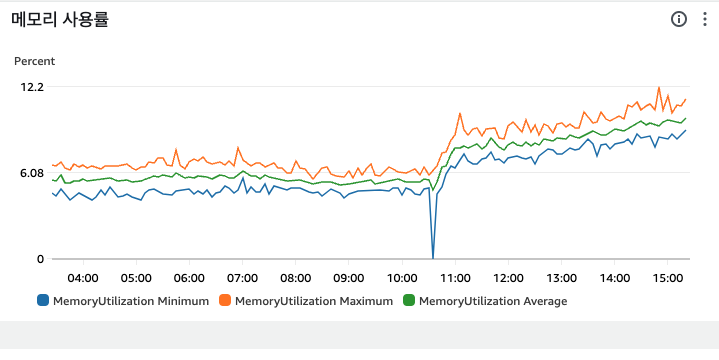 메모리나 CPU를 크게 점유하지는 않았다.
메모리나 CPU를 크게 점유하지는 않았다.
확실한 것은 CPU나 Memory 리소스가 부족해서 생긴 문제는 아니었다는 것이다.
5. Trace 분석
원인 지점을 어떻게든 모든 모니터링 수단을 총동원했다.
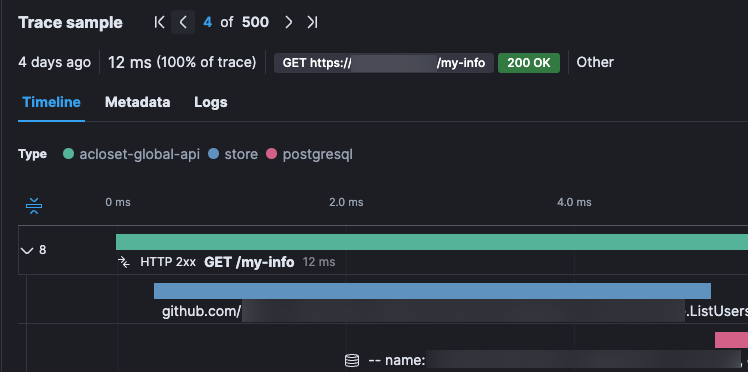
API 기록에 찍힌 Transaction-Span으로 구간별 레이턴시를 확인해봤는데, 좀 이상한 것이
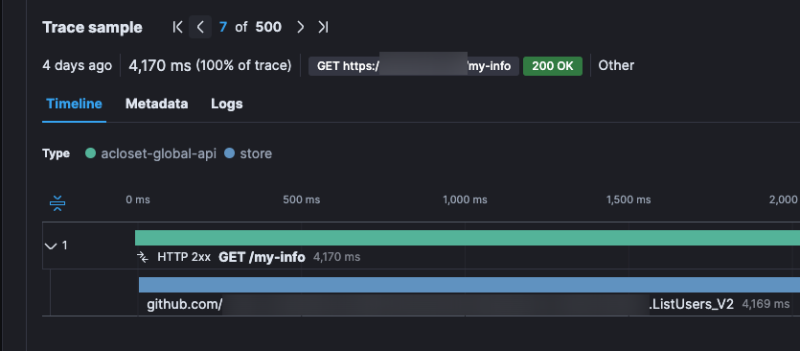 어떤건 DB 쿼리 자체가 오래 걸린 것도 있고
어떤건 DB 쿼리 자체가 오래 걸린 것도 있고
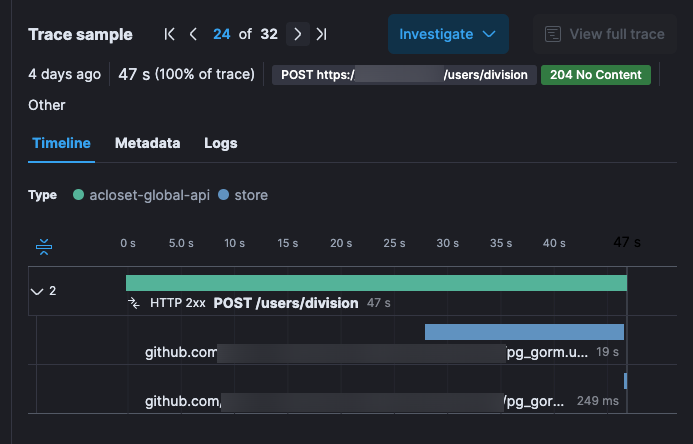 DB 쿼리 사용 전부터 오래 걸린 것도 있었다.
DB 쿼리 사용 전부터 오래 걸린 것도 있었다.
사실 DB 쿼리가 오래걸린거라면 사용하려고 시도한 테이블에 락이 걸려있다거나 하는 판단이 가능한데, I/O나 연산이 아무것도 없는 부분에서 오래걸린건 미스테리였다.
그래서 우리는 뭔가가 코어를 점유하고 있어서 각각의 API 호출 스레드가 블락되었다거나, mutex 등으로 락이 걸려서 진행이 안된다거나 하는 가설을 세워서 추가로 프로파일링도 하고 그랬다.
하지만 프로파일링 결과는 그것이 절대 아니라는 말만을 반복했다.
6. 문제
이것저것 뒤져보다가 현재 서버에서 들고 있는 DB 커넥션 수가 6개 뿐이라는 것을 봤다.
알다시피 RDB에서 하나의 커넥션이 동시에 처리할 수 있는 트랜잭션은 단 하나뿐이다. 커넥션이 6개라는 것은 동시에 처리할 수 있는 트랜잭션이 6개라는 뜻이다.
그래서 트랜잭션으로 모든 커넥션을 소모해서 커넥션 풀에서 커넥션을 가져오기 못하고 블락된 것이라는 가설을 세우고 분석해봤다.
그리고 범인은... 트랜잭션이 맞았다.
사실 DB를 거의 사용하지 않고, AI 추론도 돌리고 이것저것 많이 해서 몇초 정도 걸리는 무거운 API가 있었는데, 여기에 트랜잭션을 걸어버린 것이다.
원래 이런 식으로
 트랜잭션 처리를 위한 미들웨어를 하나 만들어놓고 무지성으로 박아서 쓰고 있었다. 저건 심지어 API가 시작되고 종료되는 기간 전체 동안 트랜잭션을 걸어버리는데, Span도 찍지 않아서 APM으로도 식별이 되지 않았던 것이다.
트랜잭션 처리를 위한 미들웨어를 하나 만들어놓고 무지성으로 박아서 쓰고 있었다. 저건 심지어 API가 시작되고 종료되는 기간 전체 동안 트랜잭션을 걸어버리는데, Span도 찍지 않아서 APM으로도 식별이 되지 않았던 것이다.
7. 해결
해결 방법 자체는 단순했기 때문에 불필요한 트랜잭션을 제거하고, 하는김에 서버가 들고 있는 DB 커넥션도 넉넉하게 늘렸다.
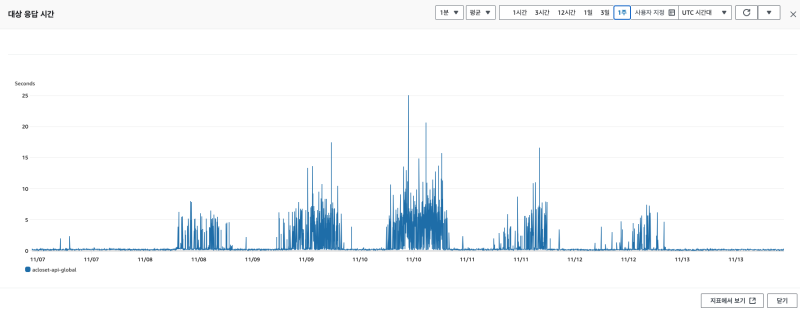 그러고 나서는 잠잠해졌다.
그러고 나서는 잠잠해졌다.
8. 교훈
-
트랜잭션은 신중히, 필요한 영역에만 좁게 걸자
-
I/O와 연관되어있거나 오래 걸릴 여지가 있는 미들웨어에 대해서는 반드시 Span 등을 찍어서 추적 가능하게 하자
-
애매하게 동작을 감추는 hidden flow는 언뜻 보면 편해보일 수 있지만, 문제 파악을 어렵게 만들고 오용의 여지를 높인다. 위의 트랜잭션 같은 경우에도 API 단위로 걸어버릴 게 아니라 트랜잭션 세션을 명시적으로 생성해서 로직 수준에서 처리하는 것이 명확하다.