검색 최적화 지표: MRR, mAP
텍스트 검색 기능은 성능과 별개로 "품질"이 매우 중요하다.
대충 Elaticsearch 박고 텍스트검색 넣으면 성능은 잘 나오니 괜찮겠지 싶을 수도 있지만, 사실 여기에는 변수가 매우 많은 편이다. 검색 자체의 정확도와 유저의 선호도 2가지를 동시에 다 챙겨야 하기 때문이다.
사전 데이터 잘 넣어야지 분리돼서 검색이 되고, 카테고리 필터링같은 것도 잘 적용해줘야 하고, 정확도와 별개로 실제 인기도 반영해서 관심있을 만한 것을 위에 올려줘야 하고... 머리가 아프다.
그래서 검색의 품질을 정량화하고 개선하는 것부터가 상당한 난관이다.
사람이 감으로 그냥 보는 정성적인 방법에는 한계가 있고, 정량화하자니 뭘 어떻게 해야할지가 난감하다.
그래도 약간 모범답안처럼 나도는 공식들이 몇가지 존재하고, 여기서는 검색의 "정렬"이 잘 동작하는지에 대한 지표를 설정하는 법을 간단히 정리해보겠다.
기본 가정
사용자가 어떤 액션을 취해야 좋은 검색 결과라고 말할 수 있을까?
아마도 검색하고 클릭을 아예 하지 않으면 나쁜 검색이라고 할 수 있을 것이다.
그리고 검색을 클릭했더라도, 페이지를 최대한 넘어가지 않고 상위 정렬의 검색 결과를 클릭했다면 괜찮은 검색 결과라고 판단할 수 있을 것이다.
이제 여기서 말하는 공식들은 이 상위 클릭에 대한 가중치나, 뭐 그런 것들을 어떻게 계산할지를 말하는 것이다.
Mean Reciprocal Rank(MRR)
사용자가 클릭한 상위 아이템을 기준으로 역수를 잡고, 총합해서 평균을 내는 방법이다.
예를 들어 특정 유저의 검색 결과가 [A, B, C, D, E, F]이고, C와 D를 클릭했다면 C(3)이 상위 아이템이다.
그러므로 1/3=0.3이 해당 유저의 점수가 되는 것이다.
그리고 이러한 점수들로 평균을 내서 품질을 계산한다.
구현하기에 간편하지만 사용자가 여러개의 아이템을 클릭했을 때를 충분히 반영하지 못한다는게 단점이다.
이것저것 들어가봤으면 그것도 나름 의미있는 검색 아니겠는가?
mean Average Precision(mAP)
MRR에서 단계가 하나 추가된 방법이다.
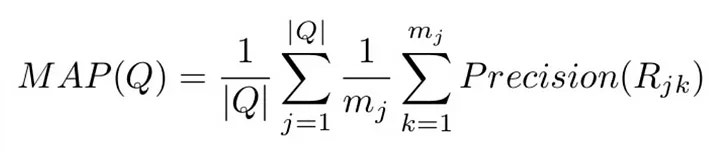 수식으로 보면 복잡한데, 사실 뜯어보면 어려운게 아니다.
수식으로 보면 복잡한데, 사실 뜯어보면 어려운게 아니다.
사용자가 여러개의 아이템을 클릭했다면, 그 각각의 아이템에 대해서 역수를 잡은 수치를 뽑는다.
그리고 그 수치들을 다시 평균내서 User의 점수를 뽑은 다음에, 각 User 점수들로 평균을 잡아서 다시 최종 품질을 계산한다.
예를 들어 특정 유저의 검색 결과가 [A, B, C, D, E, F]이고, C와 D를 클릭했다면 C(3) 점수는 1/3=0.333.., D(4) 점수는 1/4=0.25다.
이 2개를 다시 평균을 내면 (0.333 + 0.25) / 2 = 0.29...가 된다.
그리고 이 각각의 User 점수들을 평균내면 mAP 점수가 되는 것이다.