[CassandraDB] 데이터베이스 아키텍쳐
 카산드라DB가 다른 데이터베이스들과 비교해서 어떤 내부 구조를 가지고 있고, 어떤 장점과 단점, 한계가 있는지를 정리해본다.
카산드라DB가 다른 데이터베이스들과 비교해서 어떤 내부 구조를 가지고 있고, 어떤 장점과 단점, 한계가 있는지를 정리해본다.
기본 속성
NoSQL
카산드라DB는 알다시피, NoSQL이다. 그 중에서도 Key-Value NoSQL 쯤으로 분류된다.
SQL 스타일의 스키마 정의 구조, SQL 쿼리 등을 제공하긴 하지만, RDB 수준의 복잡한 쿼리(Join 등), 일관성 보장을 제공하진 않는다.
글로벌 수준의 분산 DB
카산드라 DB는 수평적으로 대규모 확장 가능한 구조를 지향하며, 글로벌 서비스를 위한 글로벌 수준 복제까지도 염두에 두고 설계되었다.
그래서 여러개의 데이터센터 간에 연결되는 것까지 고려해서 많은 기능과 옵션을 제공한다.
분산 복제 구조에 있어서는 DynamoDB에 큰 영향을 받았다.
높은 쓰기 처리량
multi master 형태의 분산 구조를 제공하기 때문에, write 처리량을 확장하는 것이 매우 쉽다.
카산드라DB는 전반적으로 일관성이나 read 능력을 좀 포기하고 write 처리량에 집중한 데이터베이스다.
**대규모 데이터 클러스터 **
카산드라는 초대형 데이터세트를 감당하기 위해 만들어졌다. 넷플릭스나 디스코드(과거), 애플 같은데서도 노드 수천개짜리 대규모 Cassandra 클러스터를 메인급 DB로 사용하고 있다.
인덱스 구조: LSM 트리
CassandraDB를 포함한 NoSQL DB들이 전통적인 RDB들과 차별화되는 부분이 인덱스 구조다.
LSM 기반의 인덱스 시스템을 사용하고, 이를 기반으로 데이터를 저장하기 때문에 RDB 대비해서 write 성능, 그 중에서도 append(insert) 성능이 매우 뛰어나다.
자세한 원리나 구조는 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223232181952
Replication
카산드라는 가용성과 수평 확장성을 제공하기 위해 꽤나 독특한 복제 구조를 갖는다.
상당수의 DB들이 단일 master를 갖고, master가 write를 책임지고 slave가 read를 처리하게 한다.
이 구조는 구현하기에 간편하고 관리하기도 편하지만, write 처리량을 늘리는데 한계가 있고 마스터가 다운될 경우에 다운타임이 크게 발생한다는 문제가 있다.
카산드라는 쓰기 처리량까지 수평적으로 확장하고, 가용성을 보다 보장하기 위해서 multi master 구조를 가진다.
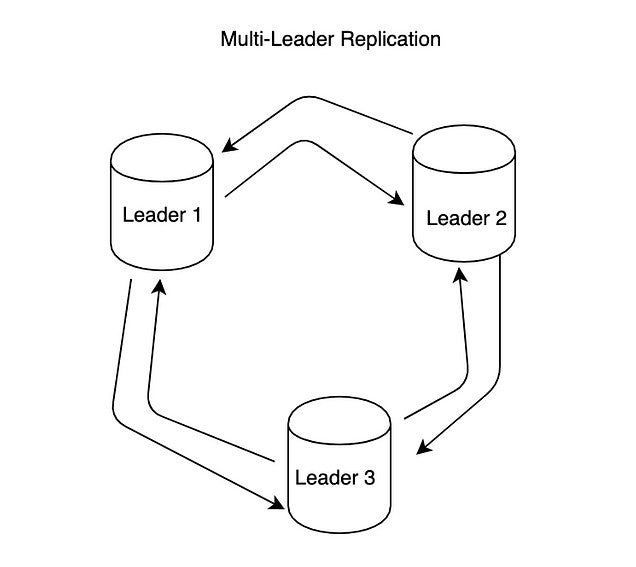 master나 slave가 따로 있는게 아니라, 모든 노드가 동등하게 read/write를 처리하는 것이다.
master나 slave가 따로 있는게 아니라, 모든 노드가 동등하게 read/write를 처리하는 것이다.
gossip 프로토콜
복제 형태도 메쉬 형태로 마구잡이로 서로 쏘는 게 아니라, 가쉽(gossip)이란 매커니즘을 통해 복제를 전송한다.
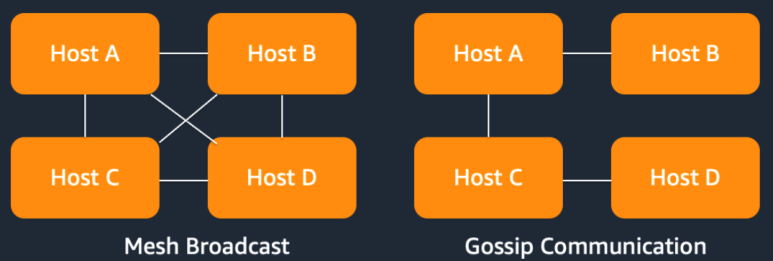 4개의 노드가 있더라도 서로를 다 바라보고 다 쏘는게 아니라, 무작위의 노드에게 데이터를 연속적으로 날리면서 주고받을 뿐이다.
4개의 노드가 있더라도 서로를 다 바라보고 다 쏘는게 아니라, 무작위의 노드에게 데이터를 연속적으로 날리면서 주고받을 뿐이다.
영희가 철수에게, 철수가 스미스에게, 소문(Gossip)을 퍼트리듯이 정보가 전달된다고 해서 가십 프로토콜이라 한다. 결국에는 소문이 모든 사람을 거쳐가므로 데이터 동기화는 똑같이 된다.
그리고 송신자와 수신자가 명확하게 결합되어있지 않은 이러한 통신 구조 덕에 노드의 추가나 삭제가 매우 유연한 편이다.
복제 전략
카산드라는 replication factor라는 옵션을 통해서 데이터의 복제본을 몇개나 만들지를 결정한다.
그리고 Replication Strategy를 통해서 복제가 어떻게 배치될지를 정할 수도 있다. 예를 들어, 각 복제본이 서로 다른 데이터센터에 배치되게 한다거나 하는 세부설정들이 가능하다.
데이터 파티션
Cassandra는 무제한의 규모 확장을 달성하기 위해 복잡한 추가 설정 없이도 자동으로 데이터 파티셔닝, 샤딩을 수행한다.
그러니까, 데이터가 insert되면 그 복제본을 모두가 공유하는게 아니라 적당히 파티션으로 분산해서 저장한다는 것이다.
파티션 키
카산드라는 테이블의 Primary Key가 파티션을 결정하는 파티션 키가 된다. primary key가 복합컬럼이라면, 첫번째 컬럼이 파티션 키다.
파티션 키를 기준으로 어느 노드에 저장될지를 결정한다.
파티션
"클러스터링 키"를 사용한다면, 복합 키이니 당연히 같은 파티션 키의 값은 여러개 중복될 수 있다. 이 경우 같은 파티션 키를 가진 데이터 집합을 파티션이라고 부른다.
각각의 파티션은 하나의 디스크 영역에 모아서 저장하는데, 개별 파티션이 수만, 수십만 row 단위를 넘어가면 성능이 극심하게 저하된다. 이런 쏠림 현상을 skew라고 부른다.
그래서 파티션 키는 중복성이 낮고 적당히 분배가 잘 되는 값을 사용해야 한다.
클러스터링 키
primary가 복합 컬럼으로 구성되었다면, 첫번째 컬럼을 제외한 나머지 컬럼들이 모두 클러스터링 키가 된다.
클러스터 키는 이 파티션 단위를 정렬해서 저장하는 기준이 된다. 그래서 dynamo에서는 이걸 정렬 키라고 부른다.
토큰 링
카산드라는 token ring이라고 하는 consistent 해싱 기법을 사용해서 파티션을 노드 간에 분산한다.
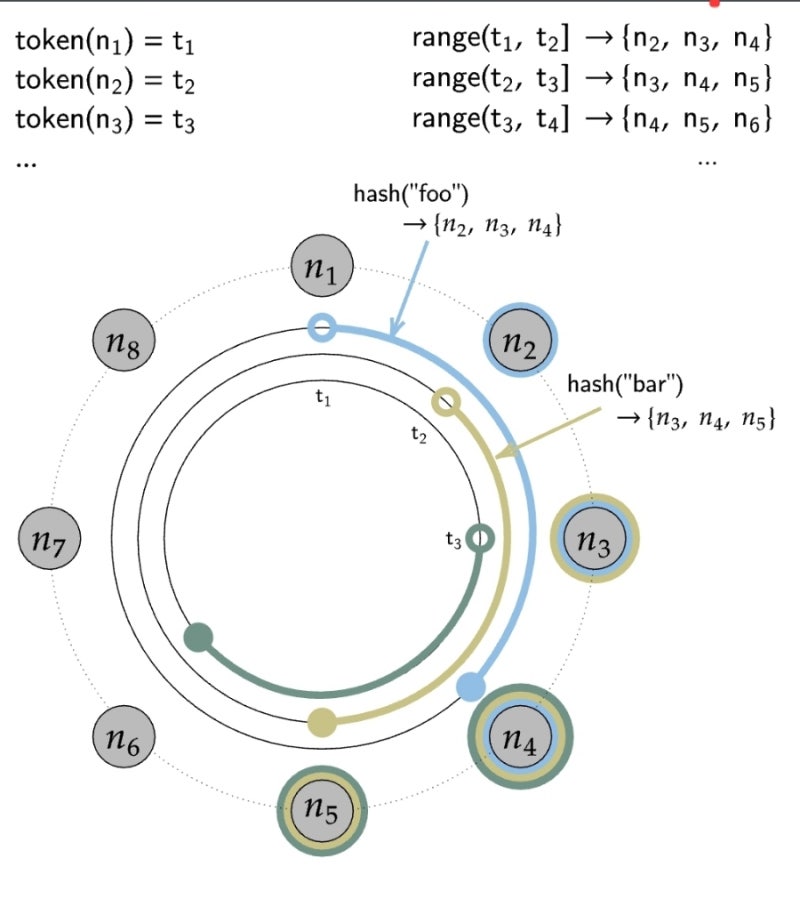 이를 통해 동적으로 추가되거나 삭제되는 노드들이 발생해도 파티션을 적절히 분산할 수 있다.
이를 통해 동적으로 추가되거나 삭제되는 노드들이 발생해도 파티션을 적절히 분산할 수 있다.
자세한 매커니즘은 별도 포스트를 참고한다.
https://m.blog.naver.com/sssang97/223457713545
CAP과 데이터 일관성
데이터베이스의 성질을 대표하는 지표 중에 하나로 CAP이란 것이 있다.
https://blog.naver.com/sssang97/223115732041
카산드라의 경우에는 multi master 구조로 고가용성을 보장할 수 있다. 일부 노드가 터져도, 그 역할을 나머지가 땜빵하면 되기 때문이다. (Availablity)
그리고 파티션 내구성(Partition tolerance) 또한 충분히 보장한다. 각각의 노드는 거의 독립적으로 동작한다.
하지만 노드간의 모든 데이터 복제가 비동기적으로 전송되고, 복제 지연에 대한 책임이 거의 누구에게도 없어서 일관성(Consistency)을 보장하기가 매우 어렵다는 단점이 있다.
따라서 카산드라는 일반적으로 AP 시스템으로 본다.
일관성 레벨 (consistency level)
하지만 카산드라도 일관성 부족을 메꿀만한 기능들을 일부 제공한다.
이걸 극단적으로 활용한다면, 일관성을 얻는 대신 가용성을 포기하는 CP 시스템처럼 쓸 수 있다.
consistency level이란 옵션을 통해서 쿼리를 날릴때 복제되는 것을 기다릴지 말지를 기다리도록 할 수 있다. mongodb의 read/write concern과 동등한 개념이라 보면 된다.
consistency level을 결정할때는 노드 중에 coordinator node라는 것을 뽑아서 그 노드가 완료 여부를 확인해주도록 한다.
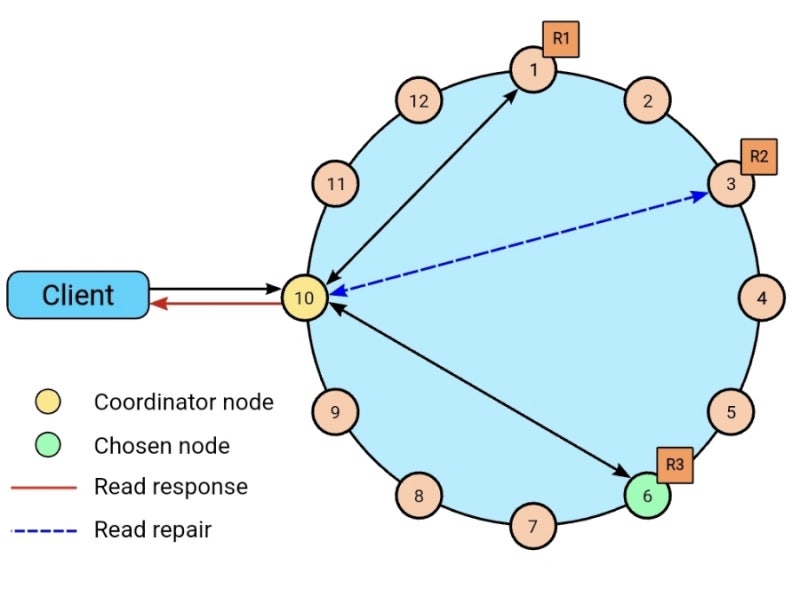 이건 고정적으로 정해져있는게 아니라, 그때그때, 알고리즘으로 판단해서 선별한다.
이건 고정적으로 정해져있는게 아니라, 그때그때, 알고리즘으로 판단해서 선별한다.
여기서 쓰기와 읽기에 대한 consistency level은 동작이 좀 다르다.
쓰기
쓰기 작업에 대해서 write consistency level을 적용할 경우, 해당 쓰기 요청은 특정 level만큼의 노드에 복제가 완료되기까지 대기한다.
예를 들어 level을 ALL로 준다면 모든 노드에 복제된 후에 완료되기 때문에 write 후에 바로 read를 하더라도 반드시 최신 데이터를 조회할 수 있다.
읽기
읽기 작업에 대해서 read consistency level을 적용한다면, 읽기 요청에 대해서 특정 level만큼의 노드가 응답해야 한다.
그렇지 않는다면 읽기가 실패한다.
level은 ALL이 가장 강력한 일관성을 제공하지만, 이러면 카산드라를 쓰는 의미가 없어서 잘 안 쓴다.
보통 일관성을 보장해야한다고 하면 쿼럼(정족수)이나 데이터센터 그룹 단위 쿼럼 기반으로 설정하는 경우가 많다.
스키마
카산드라는 테이블로 스키마를 먼저 정의하고 데이터를 저장하지만, 내부 저장 구조 자체는 대단히 유연한 편이다.
최종적으로 디스크에 저장되는 구조에는 사실 스키마에 대한 값이 없다. 그러니까, 테이블 스키마 구조를 변경해도 그 스키마 변경사항은 그 시점의 데이터부터만 적용된다는 것이다.
이를 wide column 지향의 구조라고 한다.
이것도 row base 구조이긴 한데, 각 row가 다른 모양으로 저장될 수 있다.
mongodb 같은 비정형 구조에 비할 정도는 아니지만, 스키마 변경에 대응하기에 유리한 편이다.
정렬
카산드라는 read보다 write에 집중한 DB라 읽기 쿼리에 있어서는 제한이 많은데, 대표적인 것이 정렬이다.
정렬(order by) 쿼리는, 파티션 키를 기반으로 단일 노드가 선택되었을 경우에 클러스터링 키를 기준으로만 정렬 가능하다. 그렇지 않고 order by를 막 걸어대면 쿼리가 에러를 던지면서 실패한다.
그래서 웬만한 읽기 수준 가공은 클라이언트에서 처리해야 한다.
데이터의 수정과 버전 관리
카산드라에서 데이터의 수정(update)은 사실상 새로운 데이터 버전을 삽입하는 형태로 이루어진다.
그래서 update 쿼리는 데이터가 없을때 시도하면 실제로 데이터를 insert해서 만든다! 카산드라에서 insert와 update 작업에는 차이가 별로 없다.
그리고 insert/update 쿼리는 항상 타임스탬프 값과 함께 값을 집어넣는다.
만약 동시적으로 동일 키에 대해서 다른 update 요청이 들어온다면, 카산드라는 가장 최신 타임스탬프의 쓰기만을 인정하고 나머지는 전부 버린다.
아무튼 최신 값을 기준으로 다 복제는 시키니까, 완벽한 일관성은 아니지만 되긴 된다는 점에서 최종 일관성(Eventual consistency)을 지킨다고 표현하기도 한다.
상당히 낙관적인 구조라고 할 수 있겠다.
트랜잭션
카산드라는 트랜잭션의 데이터 롤백, Lock 같은 기능을 제공하지 않는다.
그냥 ACID나 트랜잭션이 없다고 봐도 된다. CAS 형식의 낙관적인 write 정도를 제공하는게 다다.
알아서 잘 해야한다.
참조
https://cassandra.apache.org/doc/latest/cassandra/architecture/index.html
https://jins-dev.tistory.com/entry/%EA%B0%80%EC%8B%AD-%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C-Gossip-Protocol-%EC%9D%B4%EB%9E%80
https://cassandra.apache.org/doc/latest/cassandra/architecture/guarantees.html
https://cassandra.apache.org/doc/latest/cassandra/architecture/dynamo.html
https://cassandra.apache.org/doc/latest/cassandra/architecture/storage-engine.html
https://www.read.seas.harvard.edu/~kohler/class/cs239-w08/decandia07dynamo.pdf
https://stackoverflow.com/questions/20205797/which-part-of-the-cap-theorem-does-cassandra-sacrifice-and-why
https://docs.datastax.com/en/archived/cassandra/2.0/cassandra/dml/dmlAboutDataConsistency.html
https://blog.nullbus.net/91
https://stackoverflow.com/questions/32867869/how-cassandra-chooses-the-coordinator-node-and-the-replication-nodes
https://woooongs.tistory.com/m/89
https://docs.datastax.com/en/cassandra-oss/2.2/cassandra/dml/dmlTransactionsDiffer.html
https://medium.com/code-zen/cassandra-schemas-for-beginners-like-me-9714cee9236a
https://aws.amazon.com/ko/compare/the-difference-between-cassandra-and-mongodb/