[InfluxDB] 데이터베이스 구조
influxDB가 다른 범용 DB 시스템들과 비교해서 무엇이 다르고, 어떤 특징과 한계를 가지고 있는지 정리해본다.
목표
influxDB와 같은 시계열DB가 목표로 하는 것은 극단적으로 높은 append 처리량이다.
다른 많은 것들을 희생하는 대신, 초당 10만~100만건의 삽입도 감당하는 쓰기 처리량을 얻을 수 있었다.
또한 시계열, 시간값을 기준으로 하는 조회 연산의 성능이 꽤 뛰어나다.
하지만 시간이 기준이 되지 않는다면 성능을 장담할 수 없다. 시간 요소를 배제한 일반적인 필터나 집계는 사실 제대로 처리하지 못한다고 봐도 된다.
그리고 저장공간에 대한 절약도 주요한 부분 중 하나다. 시간이 지날 경우에 대한 만료 처리를 지원하며, 데이터 압축을 통한 저장 효율화를 제공한다.
테라바이트-페타바이트 급의 대규모 데이터 세트도 효율적으로 관리할 수 있어야 한다.
아무튼 그래서 influxDB와 같은 시계열 데이터베이스는 비즈니스 로직을 담당하는 메인 DB로 사용하는 것은 거의 불가능하고, 2차 가공을 위한 데이터 수집에 주로 사용된다.
모든 것은 시간을 기준으로
시계열은 모든 데이터의 기준이 시간이 된다.
그래서 기본 키(Primary Key)와 같은 것이 따로 존재하지 않고, 타임스탬프 값이 해당 데이터 row의 기준이 된다.
시간값은 최대 나노세컨드 단위까지 표현할 수 있다.
물론 시간만을 기준으로 하면 동일 시간에 삽입된 데이터가 여러개 있을 수 있기 때문에, 태그라는 필터용 값을 두고서 유일성을 판단한다.
그러니까, 타임스탬프+태그값을 기준으로 개별 데이터 row를 식별할 수 있다는 것이다.
그리고 타임스탬프 값은 구조상의 한계로 항상 오름차순으로 append되어야만 최상의 성능이 나온다. 중간에 끼워넣을 수도 있긴 하지만, 그러면 시계열을 쓰는 의미가 퇴색된다.
TSM (Time-Structured Merge Tree)
InfluxDB는 데이터를 실제로 파일로 저장할때 TSM이라는 인덱스 구조를 사용한다.
이건 사실 저장 단위를 시간으로 한 LSM의 변종이라고 할 수 있다.
https://blog.naver.com/sssang97/223232181952
데이터가 들어오면 먼저
-
인메모리 캐시에 기록하고
-
거의 동시에 WAL도 생성한다.
-
시간이 지나면 완전한 파일 단위로 모아서 저장한다. (TSM)
그래서 쓰기가 발생하더라도 바로 디스크에 반영하지는 않고, 메모리에 쌓아뒀다가 주기적으로 병합해서 디스크에 저장하는 방식을 취한다. 이를 통해 RDB 대비해서 높은 쓰기 처리량을 감당할 수 있다.
TSM 파일들은 사실상 읽기 전용 블록이며, 최적화를 명목으로 삭제나 수정에 대한 고려가 별로 되어있지는 않다.
TSM 파일은 3가지 압축 단계로 나뉜다. (L2->L3->L4)
시간이 지나면 지날수록 작은 단위들을 더 큰 단위로 합치고 압축한다.
WAL (Write Ahead Log)
influxDB는 쓰기를 최적화하기 위해서 WAL 개념을 중간에 넣어놨다.
큰 파일로 합치기 전에 일단 빠르게 쓰기 위해서 자잘한 파일들을 별도로 생성하는 것이다.
쓰기가 들어오면 먼저 인메모리에 데이터를 넣고, 그와 거의 동시에 WAL에도 데이터를 쓴다.
각 WAL 세그먼트 파일은 10mb를 넘지 않는다. 제한에 도달하면 새로운 WAL 세그먼트를 만들어서 이어붙인다.
WAL에 기록된 파일들은 주기적으로 TSM 파일로 flush되어서 합쳐진다.
WAL->TSM flush 주기는 wal-fsync-delay 옵션을 통해 조절할 수 있다.
데이터의 수정과 삭제
influxDB에서 특정 데이터에 대한 삭제는 매우 비효율적으로 동작한다. 그래서 만료를 제외한 삭제 기능은 거의 없다고 생각하는 것이 좋다.
수정도 마찬가지다. 새 데이터의 insert만을 처리하는 것이 권장되는 사용 형태다.
쓰기 딜레이
InfluxDB는 Elasticsearch 등과 비슷하게 쓰기의 반영에 항상 딜레이가 있을 수 있다.
데이터를 insert하고 바로 조회해도 그 값이 반환되지 않을 수 있다는 것이다.
쓰기 처리량을 최적화하기 위해서 기본적으로 쓰기를 모아서 처리하는 방식을 취하기 때문이다.
과부하가 걸린다면 그 딜레이는 더 커질 수 있다.
샤드 (Shard)
InfluxDB는 데이터를 효율적으로 저장하고 조회하게 하기 위해서 샤딩이 기본 동작이다.
특정 기간 범위에 속하는 데이터 그룹마다 하나의 샤드로 만든다.
데이터 양을 기준으로 고르게 분산하는 다른 데이터베이스들과 다르게, InfluxDB는 오직 시간만을 기준으로 샤드를 나누고 분산한다. 샤드를 나누는 범위를 지정하는 옵션을 Shard Group Duration이라고 한다.
예를 들어, Shard Group Duration이 1일이라면 1일 범위의 데이터 그룹 하나마다 하나의 샤드가 되는 것이다.
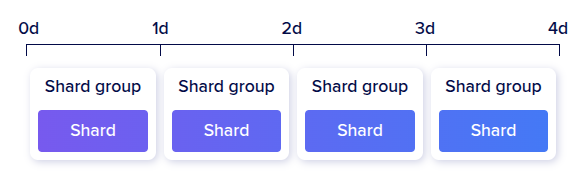
샤드 범위를 넓게 잡아서 하나의 샤드에 많은 데이터가 저장되게 한다면, 압축 효율성이 올라가서 저장공간 절약 효과를 볼 수 있다는 장점이 있다. 조회 쿼리 성능이 올라갈 수도 있다.
샤드 범위를 좁게 잡아서 하나의 샤드 크기가 줄어들면 만료시 데이터 삭제 성능이 올라간다. 찾아서 지우는게 아니라 그냥 샤드 단위 자체를 통째로 지울 수도 있기 때문이다.
샤드에 대한 설정은 Retention policy를 통해서 이루어진다. 이걸로 데이터 보존 정책, 샤드 범위, 복제(Replication)을 정의할 수 있다.
샤드 압축
시계열 데이터베이스라 해도 처음부터 압축해서 저장하는건 아니다.
최근의 샤드에 데이터를 데이터를 append할때는, 압축되지 않은 상태로 샤드에 데이터를 밀어넣는다.
압축되지 않은 상태의 샤드를 Hot Shard라고 부른다.
이후에 시간이 지나고 특정 샤드에 쓰기가 들어오지 않는다면 고정되었다고 판단하고 샤드를 다시 압축해서 저장한다. 이 샤드 고정 시기를 판단하는 시간 옵션이 compact-full-write-cold-duration인데, 기본값은 4시간이다.
4시간동안 쓰기가 없으면 일단 압축을 시도하는 것이다.
이 시점부터는 Cold Shard라고 부른다.
복제 (Replication)
데이터를 샤드로 쪼개는 것은 단순히 큰 데이터를 나눠서 저장하고 write 성능과 부분 조회의 성능을 끌어올리기 위해서다.
데이터의 유실을 예방하려면 Shard와는 별개로 복제 또한 고려해야 한다. 이를 통해 혹시라도 데이터가 유실거나 특정 노드에 장애가 발생했을 경우, 다른 노드의 복제 데이터를 가져와서 문제없이 처리할 수 있다.
데이터베이스 노드가 4개 이상이라면 기본적으로 3개의 복제본을 서로 다른 노드에 복제하고, 4개 미만이라면 노드 개수와 동일한 복제본을 만든다. 그러니까, 노드 하나마다 복제를 하나씩 두는 것이다.
분산시스템과 CAP
influxDB는 대규모 세트를 처리하고 보관하기 위한 용도로 만들어졌기 때문에, 수평 확장과 가용성 증가를 위한 분산시스템 구조를 기본적으로 제공한다.
influxDB의 분산 구조는. read/write 같은 기본적인 부분에 대해서는 AP라고 보는게 맞다.
시계열 데이터베이스의 사용사례에서 일관성은 크게 중요하지 않기 때문이다. 애초에 단일노드 환경에서도 쓰기 딜레이가 발생할 수 있는데...
그래서 노드 하나 뻗어도 그냥 다른 노드에 쓰면 되고, 다른 노드의 복제본에서 읽어오면 된다.
하지만 클러스터 전체 메타데이터. 예를 들어 샤드 그룹, 노드-샤드 매핑 정보, 샤드 보존 정책 같은 것들은 CP 방식으로 동작한다.
핵심이 되는 부분이기 때문에 일관성이 깨질 바에야 실패하고 재시도하는 것이 낫기 때문이다.
복제 방식 자체는 꽤 직관적인 편이다. 클러스터에 공유된 샤드 매핑 정보를 통해서 write를 받은 노드가 복제 대상 노드들에 직접 복제를 수행한다.
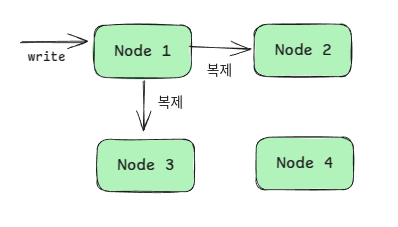 이것도 쓰기시의 consistency level을 통해서, 최종 클라이언트가 복제를 다 기다릴지, 과반수 복제만 기다릴지, 복제를 기다리지 않을지를 선택할 수 있다.
이것도 쓰기시의 consistency level을 통해서, 최종 클라이언트가 복제를 다 기다릴지, 과반수 복제만 기다릴지, 복제를 기다리지 않을지를 선택할 수 있다.
카디널리티 문제
높은 카디널리티 상황에서의 심각한 성능 저하 문제는 influxDB의 고질적인 한계였다.
influx에서 말하는 카디널리티란게 무엇이냐 하면, 예를 들어보겠다.
태그 값 email과 status를 가진 시리즈 6개가 있다고 가정해보자.
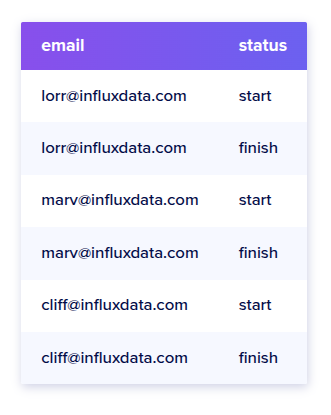 여기서 email의 고유한 값은 3개고, status의 고유한 값은 2개다.
여기서 email의 고유한 값은 3개고, status의 고유한 값은 2개다.
그러면 여기에서의 카디널리티는 3x2 = 6이다.
influx는 tag로도 빠른 필터가 가능하게 tag index라는 걸 별도로 관리하는데, 이것 때문에 카디널리티가 커질수록 tag index의 크기가 급증하고 메모리 사용량이 대폭 늘어나는 문제가 있는 것이다.
그래서 태그에 사용되는 값들에는 지나치게 고유한 값들이 들어가도록 하지 않는 것이 좋다.
타임스탬프나 기타 고유코드 같은 것들은 가급적 넣지 말아야하고, 어느 정도 고정된 범위의 메타데이터만이 들어가야 한다.
참조
https://docs.influxdata.com/influxdb/v1/concepts/schema_and_data_layout/
https://docs.influxdata.com/influxdb/v1/concepts/insights_tradeoffs/
https://stackoverflow.com/questions/35428606/difference-between-time-series-database-and-relational-database
https://docs.influxdata.com/influxdb/v1/concepts/storage_engine/
https://docs.influxdata.com/influxdb/v2/write-data/best-practices/resolve-high-cardinality/
https://docs.influxdata.com/influxdb/v2/reference/internals/shards/
https://docs.influxdata.com/influxdb/v1/query_language/manage-database/#replication
https://docs.influxdata.com/influxdb/v1/concepts/schema_and_data_layout/#avoid-too-many-series
https://docs.influxdata.com/influxdb/v1/troubleshooting/frequently-asked-questions/#how-does-influxdb-handle-duplicate-points
https://docs.influxdata.com/influxdb/v2/write-data/best-practices/resolve-high-cardinality/
https://www.influxdata.com/blog/influxdb-clustering-design-neither-strictly-cp-or-ap/