[AWS] Athena: 파티션 전략
Athena는 기본적으로 S3 디렉터리를 기반으로 테이블 단위를 생성하고, 해당 디렉터리와 하위 디렉터리를 모두 재귀적으로 읽어서 처리하는 방식을 취한다.
하지만 데이터 규모가 정말 방대하고, 항상 모든 부분을 조회할 필요가 없다면 폴더 단위로 파티션을 나누고 부분적으로 쿼리를 돌리는 것도 좋은 선택이 된다.
여기서는 파티션을 설정하고 사용하는 방법을 간단히 정리해본다.
기본 세팅
먼저 폴더 단위로 데이터가 분리된 csv 데이터셋을 준비한다.
첨부파일testset.zip파일 다운로드
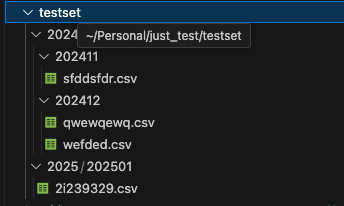
 내 경우에는 적당히 연도-월 단위로 2중 디렉터리를 구성했다.
내 경우에는 적당히 연도-월 단위로 2중 디렉터리를 구성했다.
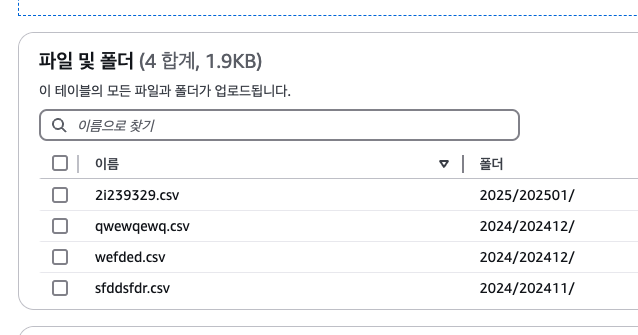
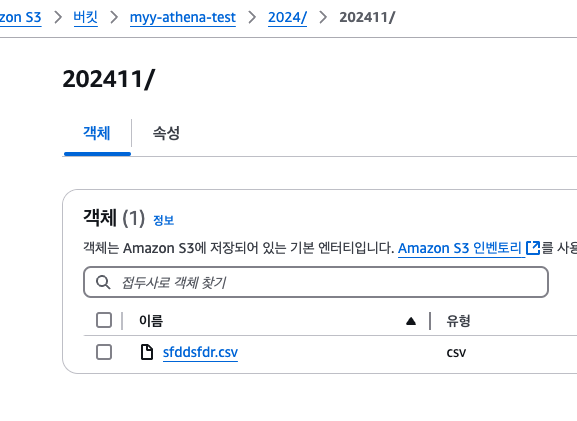 그리고 올렸다.
그리고 올렸다.
테이블 생성은 기본 옵션으로 했다.
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`transactions` (
transaction_id INTEGER,
time VARCHAR(20),
buyer_id INTEGER,
item_name VARCHAR(100),
transaction_amount INTEGER
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES ("separatorChar" = ",", "escapeChar" = "\\")
LOCATION 's3://myy-athena-test/' -- 읽어올 csv 파일이 존재하는 디렉터리
TBLPROPERTIES ("skip.header.line.count"="1") -- 첫번째 row는 생략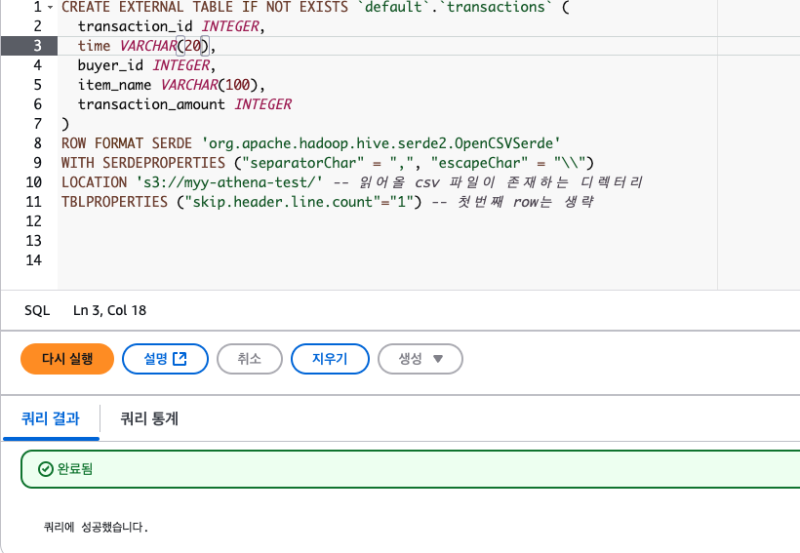 만들고
만들고
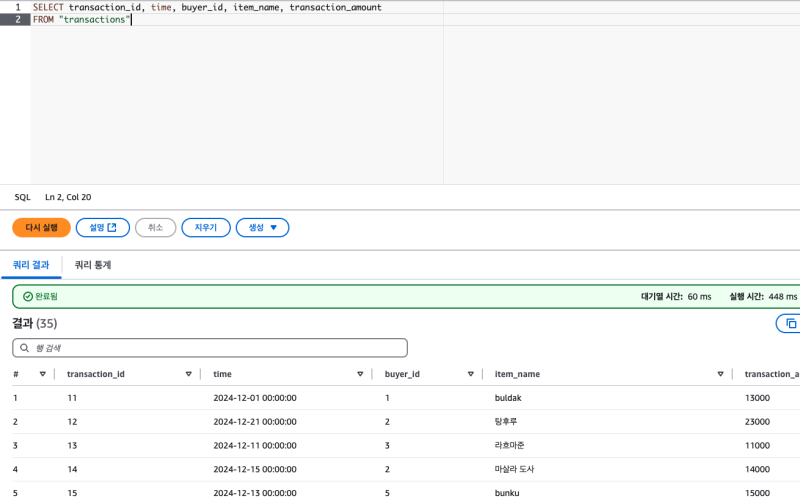 조회하면, 잘 동작한다.
조회하면, 잘 동작한다.
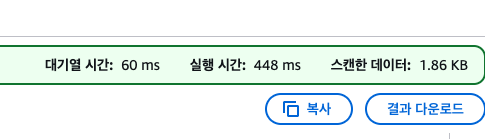 우리가 파티션을 통해 얻고자 하는 것은, 상황에 따라서 부분 데이터만 스캔해서 조회를 하는 것이다.
우리가 파티션을 통해 얻고자 하는 것은, 상황에 따라서 부분 데이터만 스캔해서 조회를 하는 것이다.
성능도 성능이고, 아테나는 스캔한 데이터 크기 기준으로 요금을 부과하기 때문이다.
아테나는 기본적으로 디렉터리 풀스캔이라서, 범위를 좁혀서 쿼리를 날린다 해도
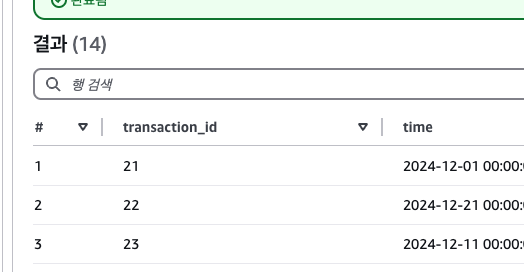
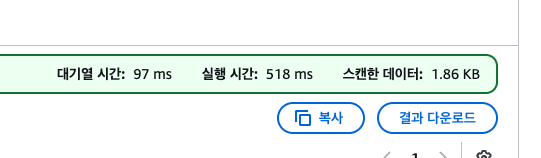
스캔 데이터는 동일해서 비용도 거의 동일하게 나온다.
이제 파티션을 적용해보자.
Athena 파티션에는 수동으로 파티션을 나누는 방법과, Partition Projection을 기반으로 자동으로 파티션을 나누는 방법이 있다.
수동 파티션 사용하는법
수동 파티션을 적용하려면, 우선 파티션의 기준이 될 각 디렉터리들이 키=값 쌍으로 구성이 되어야 한다.
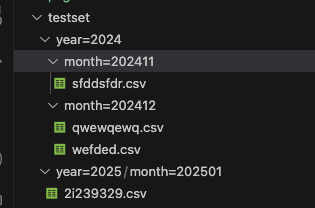 예를 들면 이런 식이다.
예를 들면 이런 식이다.
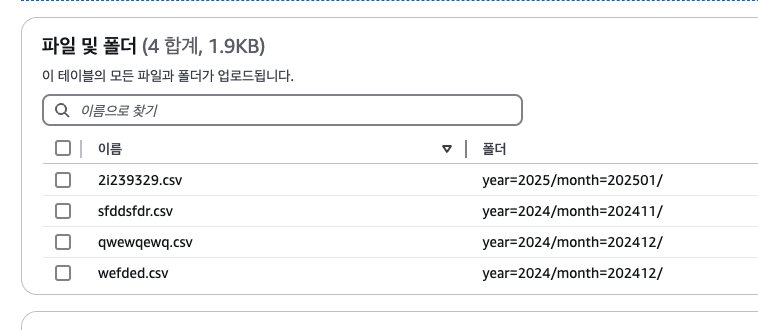
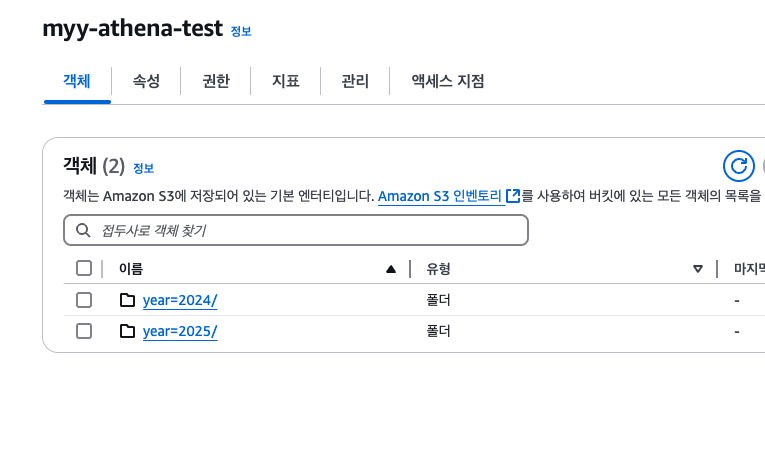
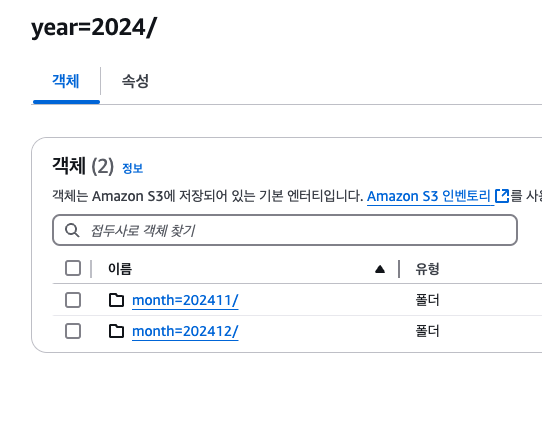 적당히 이렇게 올리고
적당히 이렇게 올리고
PARTITIONED BY (year string, month string)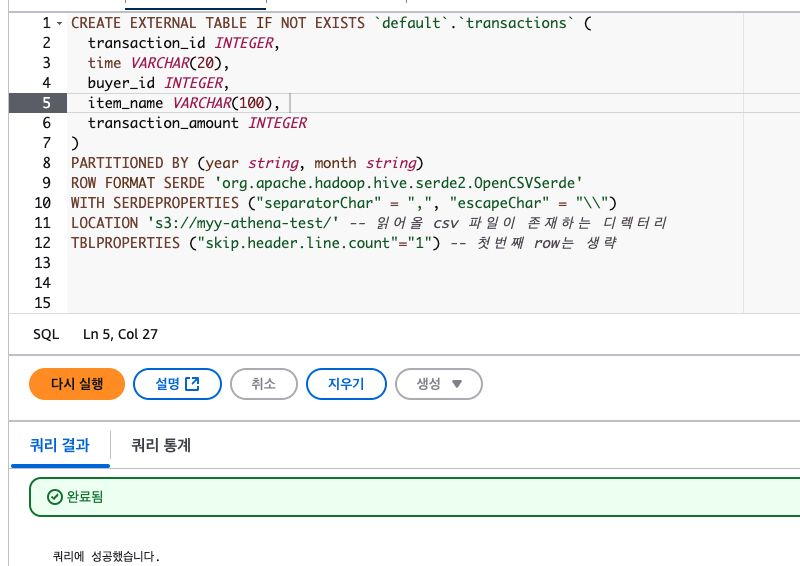 테이블 생성시에 partition 옵션을 넣어주면 된다.
테이블 생성시에 partition 옵션을 넣어주면 된다.
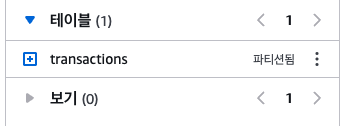 그럼 파티션 모드로 테이블이 생성될 것인데,
그럼 파티션 모드로 테이블이 생성될 것인데,
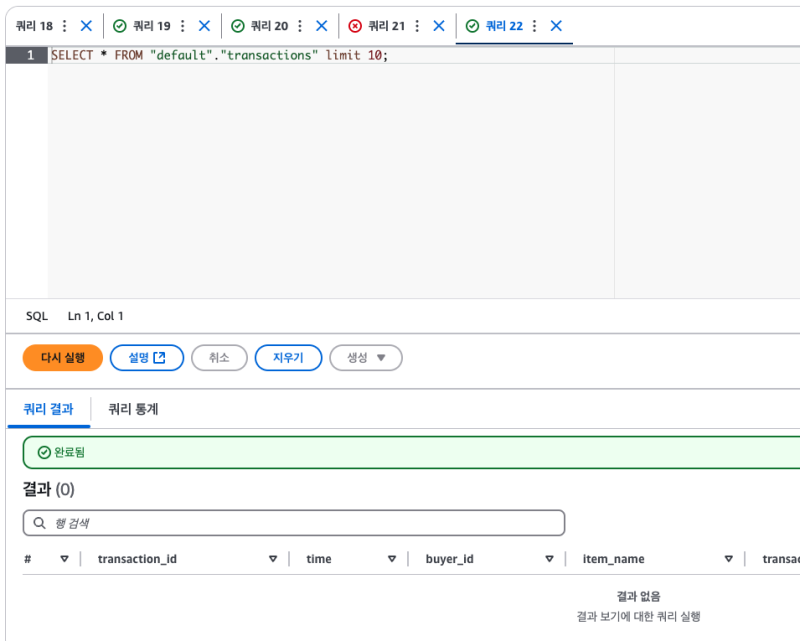 문제는, 파티션 테이블은 데이터 동기화가 실시간으로 되지는 않는다는 것이다.
문제는, 파티션 테이블은 데이터 동기화가 실시간으로 되지는 않는다는 것이다.
파티션을 수동으로 트리거해야 한다.
다음 명령어는 해당 경로 아래에 존재하는 모든 경로를 읽어서 파티션을 만든다.
MSCK REPAIR TABLE default.transactions;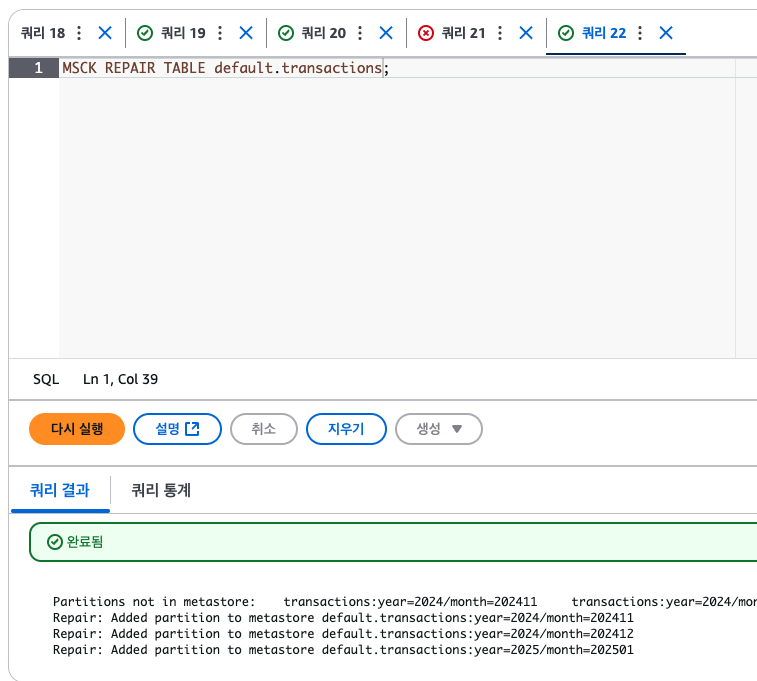 이렇게 자동으로 매핑을 해주고
이렇게 자동으로 매핑을 해주고
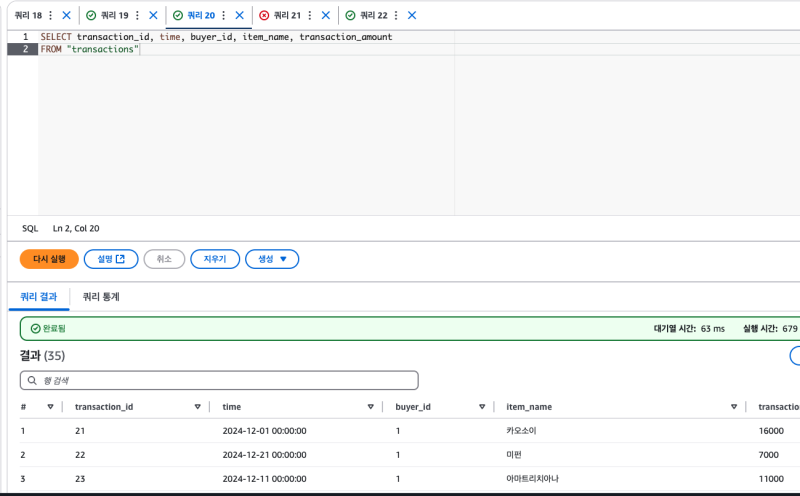 이제는 조회가 될 것이다.
이제는 조회가 될 것이다.
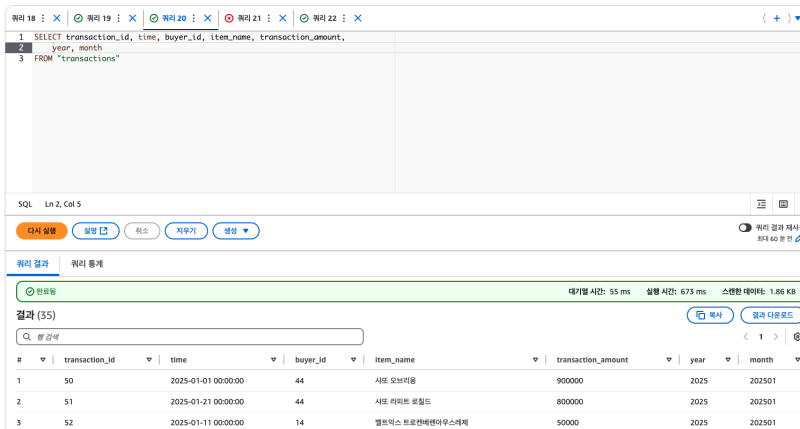 그리고 파티션에 사용한 필드는 암시적으로, 실제 데이터의 필드로 취급되어서 SELECT나 필터 등에 사용할 수 있다.
그리고 파티션에 사용한 필드는 암시적으로, 실제 데이터의 필드로 취급되어서 SELECT나 필터 등에 사용할 수 있다.
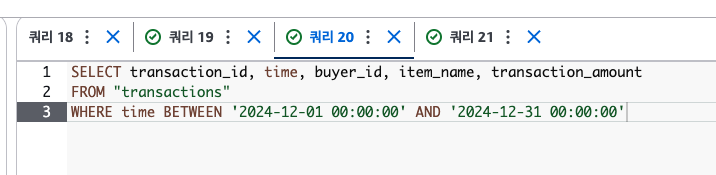
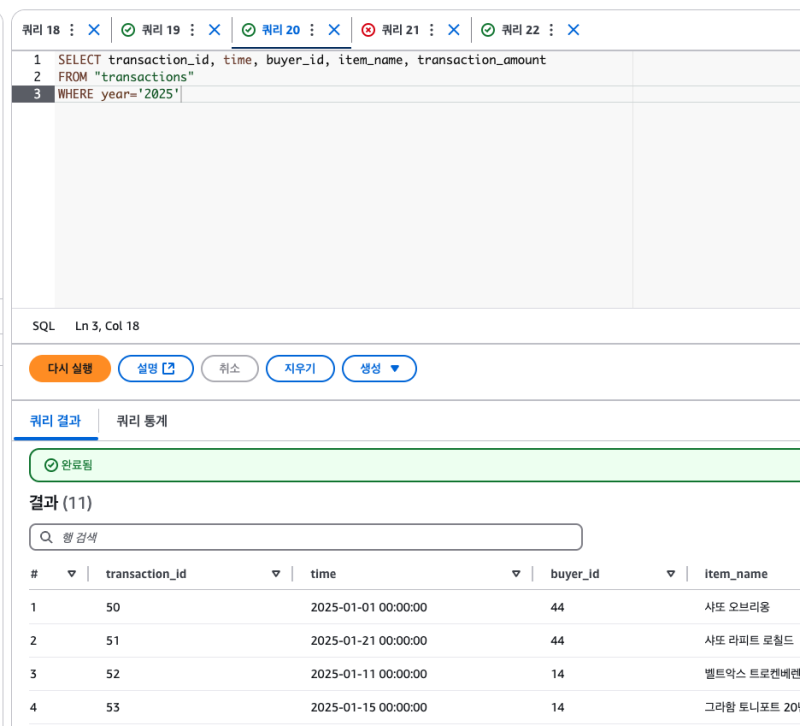 그리고 파티션 필드를 기준으로 필터를 시도하면
그리고 파티션 필드를 기준으로 필터를 시도하면
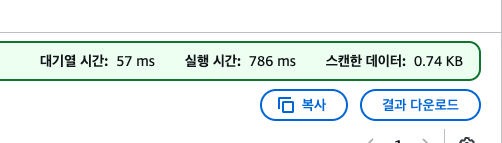 실제로 스캔도 그만큼만 한다. 스캔 크기가 줄어든 것을 볼 수 있다.
실제로 스캔도 그만큼만 한다. 스캔 크기가 줄어든 것을 볼 수 있다.
근데 이 기능의 불편한 점은, 파티션이 지속적으로 추가될 경우에 대해서는 대응을 하기가 불편하다는 것이다.
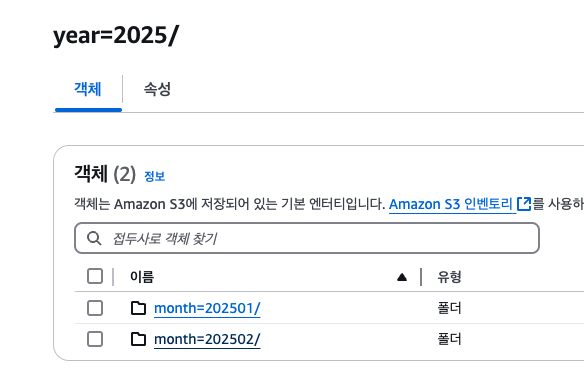 이렇게 그냥 하나 추가하면
이렇게 그냥 하나 추가하면
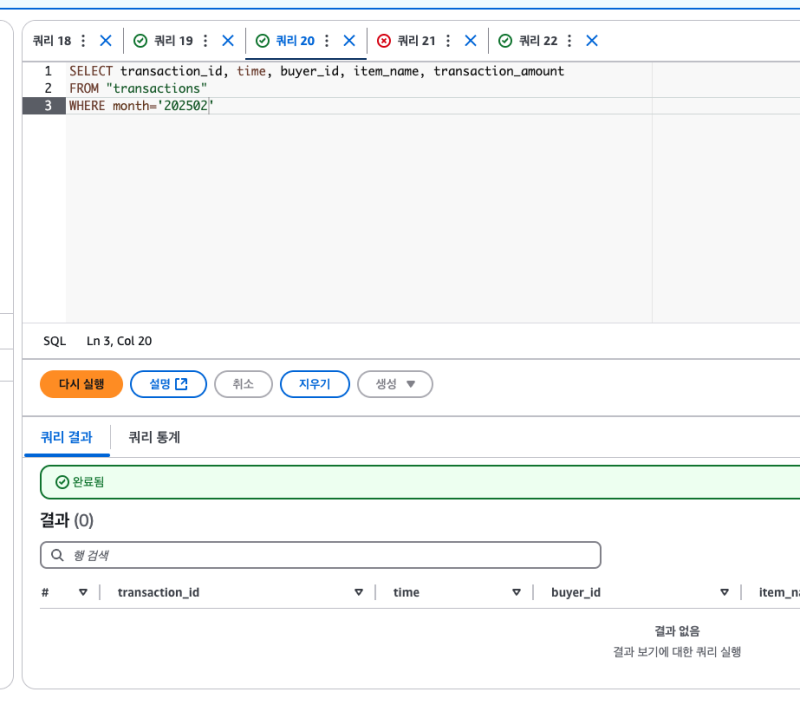
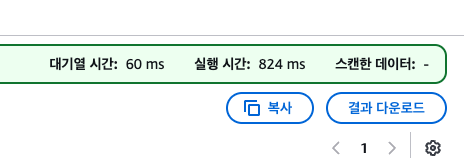 조회가 안된다. 스캔도 하지 않았다.
조회가 안된다. 스캔도 하지 않았다.
이걸 다시 반영하려면 파티션을 매핑해줘야 하는데, 위에서 한 MSCK REPAIR는 모든 범위를 풀스캔하는 것이라서 지속적으로 사용하기엔 비효율적이고, 처음에만 사용하는 용도라고 봐야 한다.
지금 추가한 폴더만 파티션에 매핑하고 싶다면, 이렇게 하면 된다.
ALTER TABLE default.transactions ADD
PARTITION (year=2025, month=202502) LOCATION 's3://myy-athena-test/year=2025/month=202502'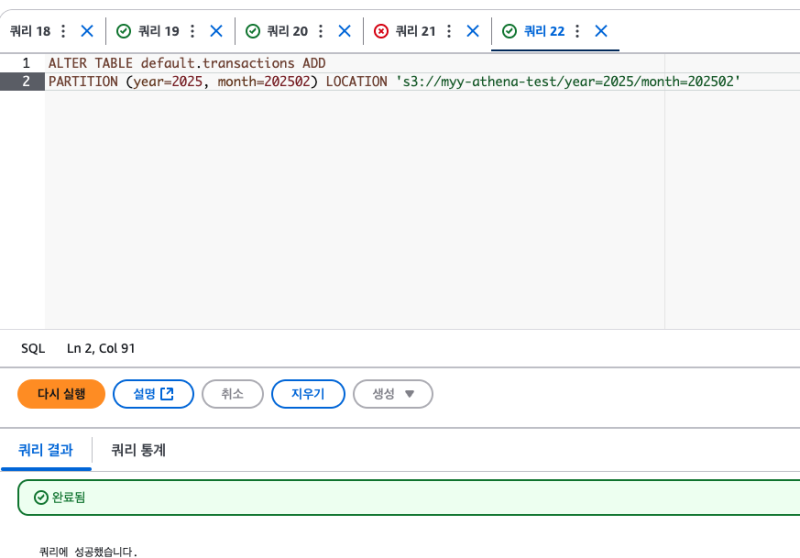 추가하면
추가하면
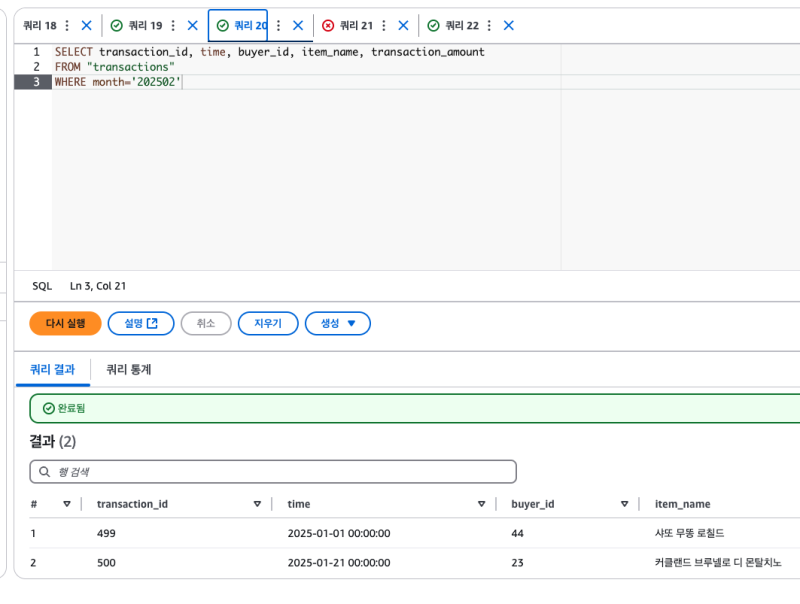 이제 동작은 잘 할 것이다.
이제 동작은 잘 할 것이다.
자동 파티션 적용하는법 - Partition Projection
athena에서 제공하는 partition projection이란 기능을 활용하면, 지속적으로 추가되는 파티션 세트에 대해서도 자동으로 매핑이 되게 구성할 수 있다.
그 대신 제약이 좀 추가된다.
Key-Value 형식의 디렉터리명은 사용할 수 없고, 다시 이런 식으로
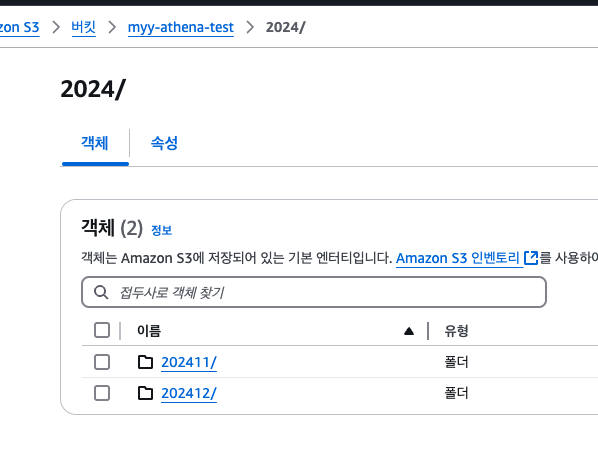 숫자값을 넣어주는 형태로 바꿔줘야 한다.
숫자값을 넣어주는 형태로 바꿔줘야 한다.
파티션 프로젝션- 폴더명에 지원되는 형식은 숫자, 날짜, 사전 정의된 enum 정도에 불과하다. 문자열 같은 자유로운 값은 넣을 수 없다.
그리고 테이블을 생성할때 프로젝션 옵션을 적절히 정의하면 된다.
TBLPROPERTIES (
"skip.header.line.count"="1", -- 첫번째 row는 생략
"projection.enabled"="true", -- 프로젝션 파티셔닝 사용
'projection.month.digits'='6', -- 월을 YYYYMM 6글자 형태로 사용
'projection.month.type'='integer',
'projection.month.range'='197000,300000', -- 197000-300000 범위값만 사용
'projection.year.digits'='4', -- 연도를 YYYY 4글자로 사용
'projection.year.type'='integer',
'projection.year.range'='1970,3000', -- 1970-3000 범위값만 사용
"storage.location.template" = "s3://myy-athena-test/${year}/${month}" -- 경로 지정
);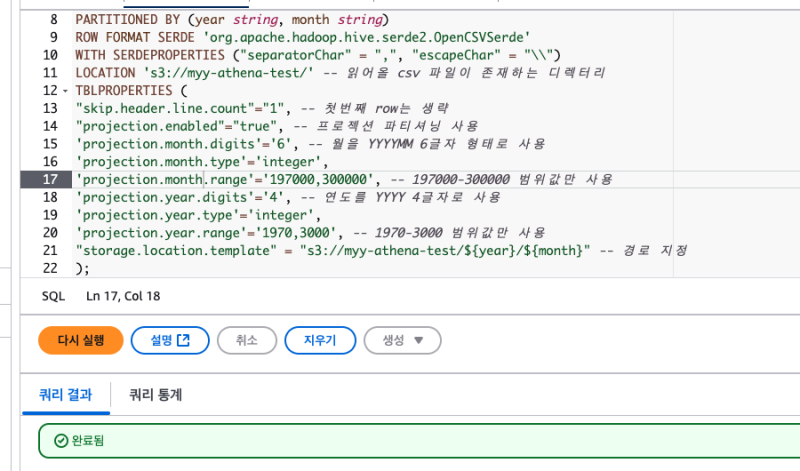 athena projection에서는 숫자값이든 날짜값이든 항상 범위가 사전 정의되어야 한다.
athena projection에서는 숫자값이든 날짜값이든 항상 범위가 사전 정의되어야 한다.
적절히 넣어주고 테이블을 생성하면
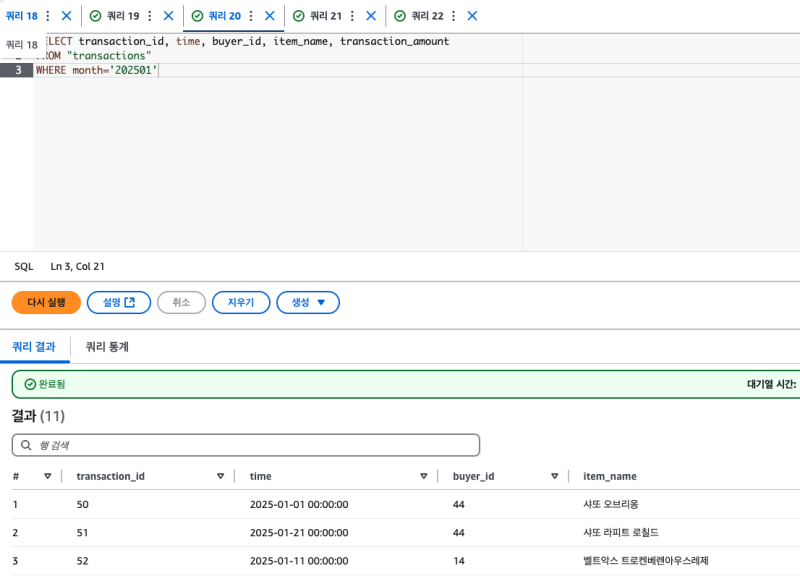 따로 손댈것도 없이 파티션이 적용되고, 파티션에 따른 스캔 분할도 잘 된다.
따로 손댈것도 없이 파티션이 적용되고, 파티션에 따른 스캔 분할도 잘 된다.
참조
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/partition-projection-supported-types.html
https://inpa.tistory.com/entry/AWS-%F0%9F%93%9A-Athena-%EC%84%B1%EB%8A%A5-%ED%96%A5%EC%83%81-TIP-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%95%95%EC%B6%95-%ED%8C%8C%ED%8B%B0%EC%85%94%EB%8B%9D
https://aws.amazon.com/blogs/database/export-and-analyze-amazon-dynamodb-data-in-an-amazon-s3-data-lake-in-apache-parquet-format/