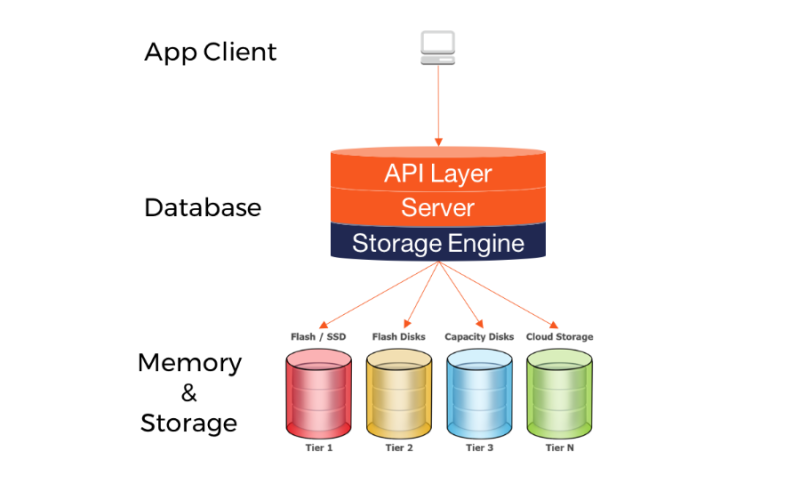
[Database] 스토리지 엔진
웹서비스가 프론트/백엔드 나누고, 컴파일러가 렉서/파서 나누는 것처럼 데이터베이스도 레이어가 어느 정도 나뉘어있다.
그리고 데이터베이스에서 가장 낮은 수준의 스토리지 액세스를 주관하는 시스템을 "스토리지 엔진"이라고 한다.
엔진의 종류
엔진은 인덱스 구조와도 연관이 깊다.
엔진을 구분할 때도 인덱스 구조에 따라서 분류하는 것이 일반적일 정도다.
전통적인 엔진은 B Tree 기반 구현체고, 신세대들은 LSM Tree 기반의 구현체들이다.
https://m.blog.naver.com/sssang97/223232264453
https://m.blog.naver.com/sssang97/223232181952
엔진의 기본요소
엔진은 많은 것들을 책임진다.
트랜잭션, ACID 같은 쓰기 수준 보장, 블록 저장 방식 빠른 접근을 위한 인덱스 구조 등을 이미 완성형으로 제공한다.
그리고 데이터베이스들은 이에 기반해서 고급 문법이나 클러스터 같은 부가적인 기능들을 올리닌 것이다.
예시
우리가 아는 상당수의 데이터베이스들은 스토리지 엔진을 일체형으로 구현하기보단, 분리형으로 만들어 붙이거나 갖다쓰는 경우가 꽤 많다.
예를 들면, 이런 것들이 있다.
MySQL -> MyISAM or InnoDB
MongoDB -> Wired Tiger
CassandraDB -> RocksDB
Couchbase -> Couchstore or Magna
CockroachDB -> PebbleDB
yugabyte -> DocDB(RocksDB based)
예외
OracleDB는 스토리지 엔진의 개념이 아예 없다.
PostgreSQL도 스토리지 엔진을 직접 구현해서 사용한다.
시계열 데이터베이스들은 특성상 디스크 액세스 패턴이 많이 달라서, 엔진을 갖다쓰기보단 직접 구현하는게 일반적이다.
InfluxDB나 Prometheus가 모두 그렇다.
Clickhouse 같은 빅데이터 처리용 DB들도 마찬가지다. 일반적인 쓰기/조회 패턴을 가지지 않아서 직접 구현하기도 한다.
Elasticsearch 같은 경우는 Lucene을 통해 모든 제어를 위임하는데, 이걸 스토리지 엔진이라 부르기엔 애매하다. 아니 맞나...?
참조
https://www.yugabyte.com/blog/a-busy-developers-guide-to-database-storage-engines-the-basics/