스킵 리스트 (Skip List)
스킵 리스트는 Linked List의 주요 변형 중 하나다.
Sorted Array와 Linked List, Tree의 특성들을 어정쩡하게 섞은 듯한 혼란스런 구조를 가지고 있다.
일반적인 응용프로그램에서는 잘 쓰이지 않지만, 데이터베이스 환경에서는 인덱스 자료구조로, B-Tree나 Tree 기반 구조들의 대안으로서 활발하게 사용되고 있다.
검색 복잡도는 평균 O(log N), 최악 O(N)
삽입 복잡도는 평균 O(log N), 최악 O(N)
삭제 복잡도는 평균 O(log N), 최악 O(N)
이다.
최악 복잡도가 O(N)으로 느린 편이지만, 사실 그렇게 나올 일은 잘 없다. 평균 성능을 보고 쓴다.
기본 원리
Skip List는 일단 Linked List에 기반해서 확장된 구조다. 그래서 일단, 중간 삽입/삭제에 유연하다.
 https://ohgym.tistory.com/10
https://ohgym.tistory.com/10
그리고 각 요소들은 정렬되어서 순서대로 배치되어야 한다.
근데 이 형태로는 뭐 어떻게 써먹기가 애매하다.
저 상태에서 5.5라는 값이 삽입되면 어떻게 집어넣을까?
삽입/삭제는 O(1)이지만, 삽입/삭제할 위치를 찾을때 거의 O(N)의 비효율적인 탐색이 발생할 것이다. 배열이 아니라 인덱싱이 불가능하기 때문이다.
여기까지는 그냥 정렬되는 Linked List에 불과해보인다.
Linked List와 다른 주요한 차이점은 이름 그대로 Skip 가능하게 노드끼리 추가 연결을 만들어둔다는 것이다.
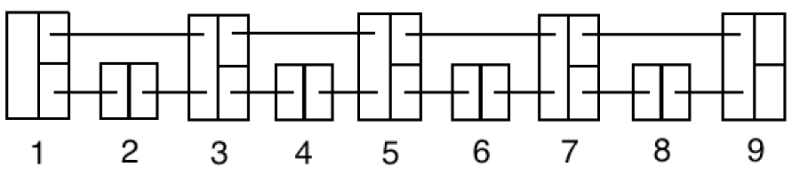 https://ohgym.tistory.com/10
https://ohgym.tistory.com/10
 https://ohgym.tistory.com/10
https://ohgym.tistory.com/10
최대 몇개나 Skip을 가능하게 만들지는 구현 선택에 따라 다를 수 있다.
그리고 당연히 Skip 경로를 늘릴수록 메모리 사용량이 늘어날 것이다.
아무튼 이러면 배열의 Binary search만큼은 못하겠지만, 꽤 빠르게 값 범위를 쫓아갈 수 있다.
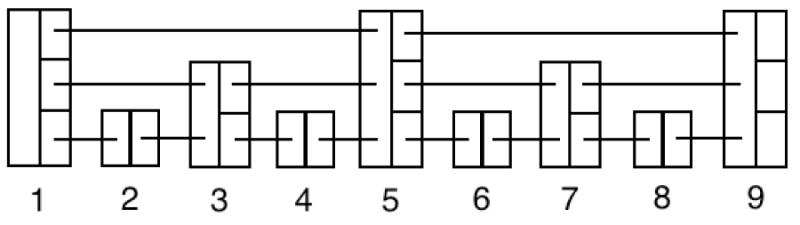
 예를 들어 여기서 6의 존재 여부를 찾는다면 이런 식으로 처리할 수 있을 것이다.
예를 들어 여기서 6의 존재 여부를 찾는다면 이런 식으로 처리할 수 있을 것이다.
- 1 노드 진입
- 1의 최대 값 5을 참조
- 6은 5보다 크므로, 5 노드로 이동
- 5노드의 최대값 9를 확인
- 6은 9보다 작으니까 그 다음 값 7 확인
- 6은 7보다도 작으니까 그 다음 6 확인
- 탐색 성공
이런 식으로 최대 Skip 개수가 적당히 많을수록 전체 노드를 덜 탐색하고 값을 찾을 수 있다는게 장점이다.
그리고 다음과 같은 유별난 특징들이 있디.
불균형성
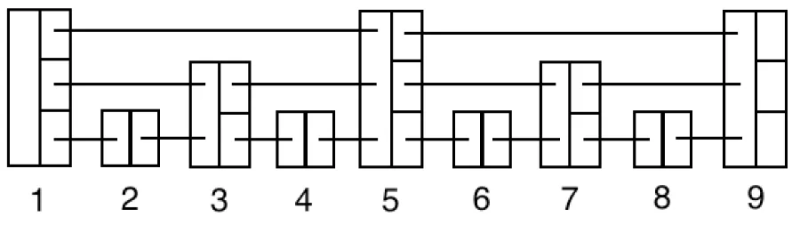
아래 상태에서 중간의 5나 7을 삭제한다면 어떻게 해야할까?
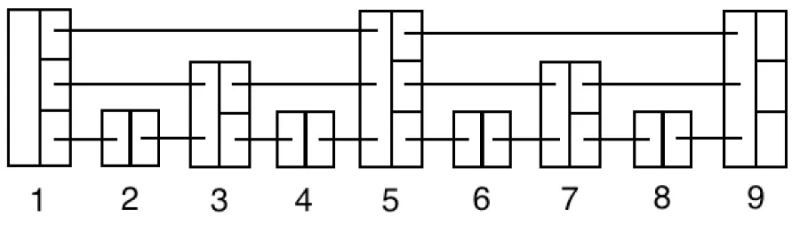 만약 저 레벨을 예쁘게 다 유지해서 균형을 맞춰야 한다면, 왔다갔다 옮겨서 붙이는 리밸런싱 작업이 필요하고, 삭제/삽입 비용이 늘어날 것이다.
만약 저 레벨을 예쁘게 다 유지해서 균형을 맞춰야 한다면, 왔다갔다 옮겨서 붙이는 리밸런싱 작업이 필요하고, 삭제/삽입 비용이 늘어날 것이다.
이것도 그렇고 후술할 확률성도 있어서 Skip List는 일정한 높이와 비율을 유지하지 않고 울퉁불퉁한 구조를 갖게 만든다.
확률성
요소를 생성할때는 랜덤값을 기반으로 노드의 Level을 결정한다.
사실 랜덤 로직이 들어가지 않아도 알고리즘의 구현에는 문제가 없다.
확률성을 굳이 집어넣은 이유는 사실 "삭제의 안정성" 때문이다.
level 결정 알고리즘을 결정론적으로 넣으면 삭제시 재배치에 있어서 병목이 되는 지점이 생길 수 있고, 이건 HashDOS처럼 인위적인 공격 지점이 될 수 있다.
확률론을 넣은 것은 이러한 성능 취약점을 안정적으로 분산시키기 위함이다.
인덱싱
스킵 가능한 접근 구조 탓에 배열만큼은 아니지만, N번째 인덱싱을 비교적 빠르게 처리할 수 있다.
복잡도는 O(log N)이다.
vs B-Tree (in Database)
https://m.blog.naver.com/sssang97/223262254364
스킵리스트의 비교대상은 거의 항상 B-Tree다.
모든 것이 다 그렇지만, 서로 trade-off가 있다.
그리고 딱히 뭐가 우위라고 할만한 상황도 아니다.
오히려 종합 성능에서는 B-Tree가 안정적인 부분이 많아서, Skip List가 Hype으로 뜨고있는 것처럼 보이는 지금에도 특별한 이유가 없다면 B-Tree를 선택하곤 하는 것 같다.
B-Tree의 장점
B-Tree는 알고리즘 자체가 디스크에서 블록을 효율적으로 읽고 쓰는 데에 최적화되어있다. 디스크<>메모리 전송 효율 측면에서는 B-Tree를 따라올 것이 딱히 없다.
인메모리 작업에 있어서도 캐시를 나름 잘 타서 꽤 효율적인 편이다.
그리고 Skip List와 비교하면, 최악의 경우 성능이 높아서 아주 안정적인 속도와 신뢰성을 보장할 수 있다.
Skip List의 장단점
일단 구현이 비교적 간단한 편이다. 골치아픈 Tree 고유의 리밸런싱과 Merge 단위가 존재하지 않는다.
그리고 동시성 처리에 있어서 꽤 강점을 보인다.
B-Tree는 수정이 발생할 때 Tree 전체나 일부를 잠그고 리밸런싱을 할 수 있는데, 스킵리스트는 이런 문제에 있어서는 상대적으로 자유로운 부분이 있기 때문이다.
하지만 제대로 된 동시성 제어를 구현하는 데에는 마찬가지로 많은 어려움이 존재한다.
캐시 효율성은 의외로 B-Tree 구현들보다 못하다. 애초에 Linked List 기반 구조라 참조 요소들이 온 메모리에 분산되어있고, 참조 계층도 끝없이 들어가기 때문이다.
요즘은 그다지 큰 문제는 아니지만, B-Tree 구현들에 비해서 메모리 사용량이 좀 더 많을 수 있다. 노드마다 포인터를 N개씩 들고 있기 때문이다.
사용사례
데이터베이스 스토리지 엔진인 RocksDB은 Memtable 구현에 Skip List를 쓴다.
(Cassandra, CockroachDB, Kafka 등에 사용)
Redis는 Sorted Set 구현에 Skip List를 쓴다.
Elasticsearch(Lucene) 또한 인덱스 구현에 Skip List를 응용한다.
참조
https://en.m.wikipedia.org/wiki/Skip_list
https://stackoverflow.com/questions/234560/skip-lists-ever-used-them
https://stackoverflow.com/questions/17642197/skip-list-without-randomization
https://stackoverflow.com/questions/66804510/lucene-index-modeling-why-are-skiplists-used-instead-of-btree
https://opensource.googleblog.com/2013/01/c-containers-that-save-memory-and-time.html?m=1
https://stackoverflow.com/questions/256511/skip-list-vs-binary-search-tree/28270537#28270537
https://ryogrid.github.io/articles/skiplist_en
https://stackoverflow.com/questions/3489560/purely-functional-concurrent-skip-list/32261808#32261808
https://ketansingh.me/posts/lets-talk-skiplist/