[PostgreSQL] pgvector: 벡터 인덱스 다루기
이전 포스트
https://blog.naver.com/sssang97/223785241957
pgvector에서 효율적인 벡터 검색을 위해 인덱스를 구성하는 방법을 다뤄본다.
데이터 세팅
일단 테이블을 적당히 만들고
CREATE TABLE vector_index_test (
id serial8 PRIMARY KEY,
embedding vector(40)
);벡터 길이는 40으로 했다.
그리고 난수 기반으로 벡터열을 1000만개 정도만 넣어놨다.
INSERT INTO vector_index_test(embedding)
SELECT
ARRAY(
SELECT ((random() * 255)::INTEGER + t.n) % 255
FROM generate_series(1, 40)
) AS random_vector
FROM (
select n
from generate_series(1, 10000000) as n
) as t; 들어가는건 금방 들어간다.
들어가는건 금방 들어간다.
기본 성능
한번 그냥 적당히 쿼리를 때려보자.
explain(analyze) SELECT *
FROM vector_index_test
WHERE 1=1
ORDER BY embedding <#> '[165,94,53,1,253,53,142,126,1,194,46,162,189,69,107,100,153,161,30,225,165,201,264,42,29,86,2,185,98,81,49,82,119,183,46,21,222,81,227,187]'
LIMIT 10;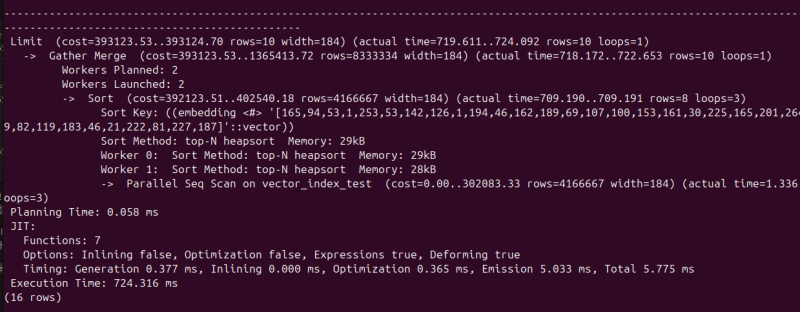 그러면 풀스캔을 때릴테니, 당연히 좀 느릴 것이다.
그러면 풀스캔을 때릴테니, 당연히 좀 느릴 것이다.
하드웨어 스펙이 꽤 괜찮음에도 724밀리초나 걸렸다.
그럼 인덱스를 걸면 좀 나아질까?
CREATE INDEX vector_normal_index on vector_index_test(embedding);
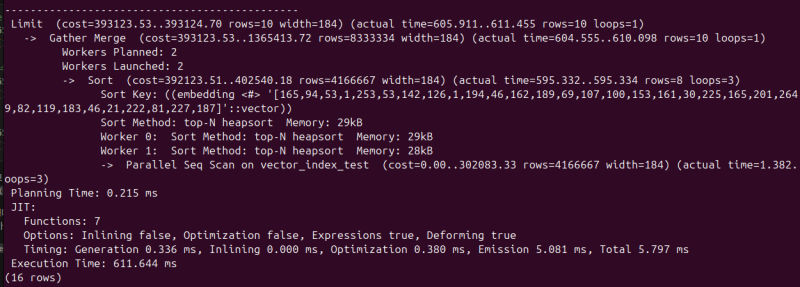 그렇지는 않다.
그렇지는 않다.
이 벡터 유사도 연산이란 것 자체가 단순한 동등 비교나 정렬이 아니라서, 순진한 인덱스로는 인덱싱이 거의 불가능하기 때문이다.
효율적으로 벡터 검색을 하게 하려면 pgvector에서 제공하는 특수한 인덱스 타입들을 사용해야 한다.
ANN과 벡터 전용 인덱스
일단 알아둬야할건, vector 전용 인덱스들은 approximate nearest neighbor(ANN) 개념에 기초한 인덱스다.
다시 말해, 성능을 위해 정확한 검색이 아니라 근사치에 의한 검색을 한다는 것이다. 그래서 정확하지 않을 수 있다.
그래서 속도와 별개로 적중률 수치, recall을 유지하는 것도 중요한 과제다.
예를 들어 exact 검색으로 100개를 찾았을때, ANN으로 그 중에 95개를 찾았다면 recall은 95%라고 말한다.
pgvector에서는 다음 2가지 타입의 인덱스가 제공된다.
- HNSW
- IVFFlat
HNSW는 벡터들에 대해서 다중 그래프를 구성하는 무거운 인덱스다.
빌드 시간이 매우 느리고, 메모리도 많이 먹는 대신 쿼리 성능이 빠르다.
IVFFlat은 파티션 기반으로 구성되는 비교적 작은 인덱스다.
빌드 시간이 비교적 빠르고, 메모리도 덜 먹는 대신 쿼리 성능이 조금 느리다.
HNSW 인덱스
HNSW 인덱스는 위에서 언급했듯, 다중 그래프 기반으로 구성되는 무거운 인덱스다.
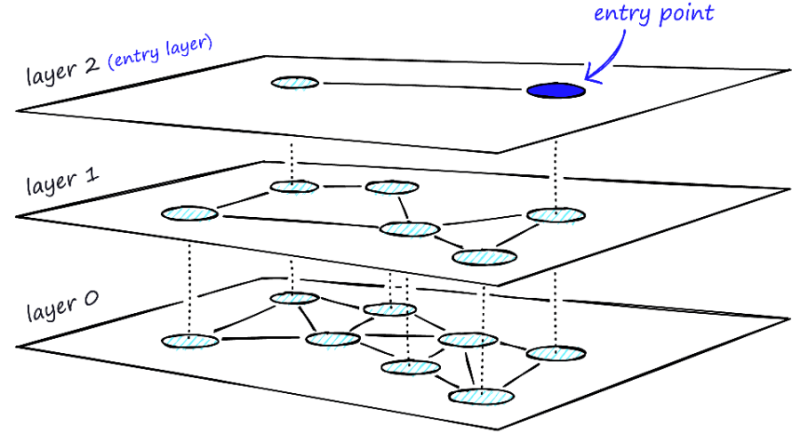 https://www.pinecone.io/learn/series/faiss/hnsw/
https://www.pinecone.io/learn/series/faiss/hnsw/
원본 데이터 크기의 약 50-100% 정도를 메모리로 점유한다.
모든 vector database들이 공통으로 지원하는 기본 인덱스 알고리즘이다.
아래와 같은 식으로 만들 수 있는데, 유사도 검색 방법까지 미리 지정해야 한다.
CREATE INDEX hnsw_index_test ON vector_index_test USING hnsw (embedding vector_ip_ops); 근데 이건 인덱스 만드는 것부터 쉽지 않아서, 그냥 만들면 세월이 다 간다.
근데 이건 인덱스 만드는 것부터 쉽지 않아서, 그냥 만들면 세월이 다 간다.
메모리를 좀 더 주고 만들어야 그나마 빠르게 만들 수 있다.
길이 40짜리 벡터가 1000만개일때 기준으로 10GB 정도는 있어야 정상적으로 빌드가 된다.
SET maintenance_work_mem = '10GB';
CREATE INDEX hnsw_index_test ON vector_index_test USING hnsw (embedding vector_ip_ops); 가용 메모리가 많지 않다면 포기하고 램을 더 사라.
가용 메모리가 많지 않다면 포기하고 램을 더 사라.
인덱스 적용 후에 다시 이전의 유사도 쿼리를 때려보면
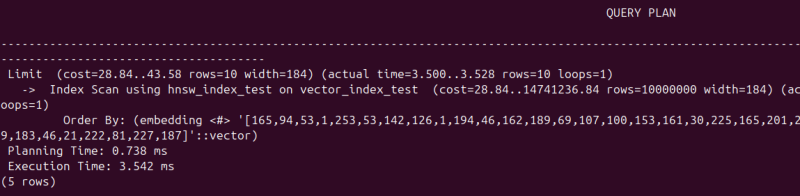 굉장히 빨라진 것을 볼 수 있다.
굉장히 빨라진 것을 볼 수 있다.
3.5 밀리초밖에 걸리지 않았다. 반복해서 실행하다보면 1밀리초 미만으로도 실행이 된다.
인덱스 옵션으로는 m과 ef_construction 값이 제공된다.
CREATE INDEX ... ON ... USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);m은 그래프에서의 각 레이어가 가리키는 연결 개수다. 기본값은 16이다. 높일수록 속도가 올라가는 대신 메모리 사용량이 증가한다.
ef_construction은 그래프를 구성하기 위한 dynamic candidate list의 개수다. 기본값은 64다. 이게 커질수록 삽입속도가 느려지는 대신 recall이 올라간다.
IVFFlat 인덱스
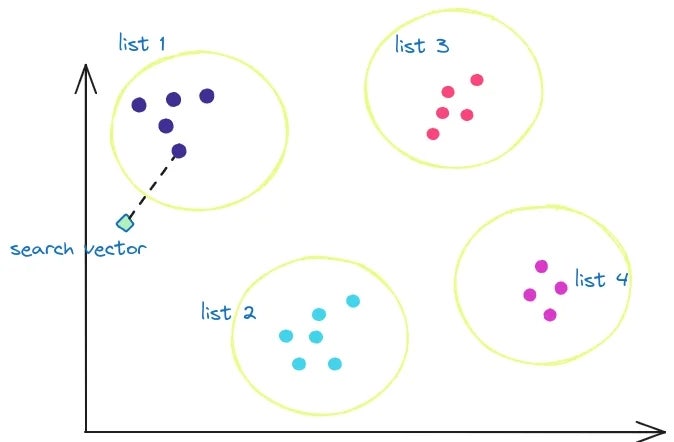
IVFFlat은 파티션 단위로 데이터 그룹을 분할해서 탐색을 수행하는 비교적 작은 크기의 인덱스다.
 https://tembo.io/blog/vector-indexes-in-pgvector
https://tembo.io/blog/vector-indexes-in-pgvector
원본 데이터 크기의 약 20-30% 정도를 메모리로 점유한다.
다른 Vector DB들은 이상하게 HNSW만을 메인으로 지원하는데, 이건 pgvector 말고 구현자가 많지는 않은 것 같다. pgvector의 특이한 장점 중 하나다.
벡터들을 N개 단위로 파티셔닝하는데, 각각의 파티션들은 값 범위를 기반으로 배치되기 때문에, 범위 기반으로 인접한 파티션을 찾아서 조금 더 빠르게 인접 벡터를 탐지할 수 있다.
여기서 파티션 개수를 지정하는 N 값을 probe라고 한다.
행이 1000만개 미만이면 1000을 권장하고, 이상이라면 sqrt(행 개수)를 주는 것을 권장한다.
probe가 클수록 검색 속도가 빨라지는 대신 recall이 떨어진다.
이제 인덱스를 한번 만들어보자. 마찬가지로 inner product 유사도 기반으로 인덱스를 생성했다.
그리고 probe는 1000 정도로만 줬다.
CREATE INDEX ivfflat_index_test ON vector_index_test USING ivfflat (embedding vector_ip_ops) WITH (lists = 1000); HNSW에 비하면 상당히 빠르게 만들어진다.
HNSW에 비하면 상당히 빠르게 만들어진다.
그리고 쿼리를 날려보면
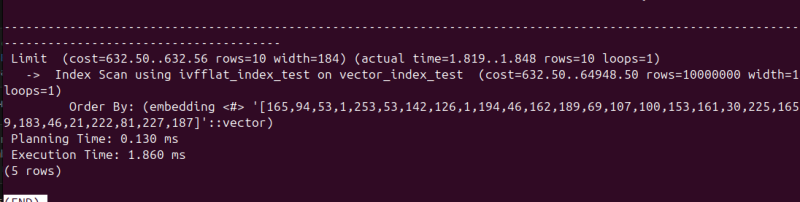 2밀리초 정도로, HNSW에 못지 않게 꽤 빠른 속도로 결과가 나왔다.
2밀리초 정도로, HNSW에 못지 않게 꽤 빠른 속도로 결과가 나왔다.
데이터 규모가 더 커진다면 뭔가 달라질 수 있겠지만, 이 정도 적당한 규모에서는 ivfflat으로도 대충 쓸만한 것 같다.
실제 성능은 데이터 규모와 형태, 리소스에 따라 많이 달라질 수 있을 것이다.
직접 데이터 밀어넣고 돌려본 다음에 선택할 것을 권한다.
기타 최적화 & 팁
쾌적하게 쓰려면 shared_buffers 크기를 좀 넉넉하게 주는 편이 좋다.
통상적으로 서버의 25% 정도를 권장한다.
SHOW shared_buffers;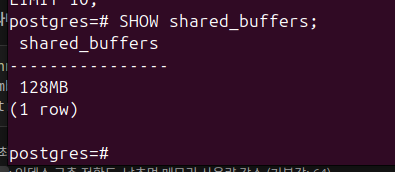 너무 적다면 SHOW config_file;로 설정파일 찾아서 옵션을 변경하고 재부팅을 해주자
너무 적다면 SHOW config_file;로 설정파일 찾아서 옵션을 변경하고 재부팅을 해주자
recall을 측정하려면 인덱스 미적용 버전과 적용 버전을 둘다 돌려봐야 한다.
그럴때는 현재 세션에서 인덱스 스캔을 임시로 끄고 돌리는게 편하다.
SET enable_indexscan = OFF; 그럼 다시 풀스캔을 돌 것이다.
그럼 다시 풀스캔을 돌 것이다.
그리고 인덱스 미적용버전을 빠르게 돌리려면, 워커를 강제로 늘려서 병렬처리를 시키는게 편하다.
SET max_parallel_workers_per_gather = 4;참조
https://neon.tech/blog/understanding-vector-search-and-hnsw-index-with-pgvector
https://velog.io/@bbkyoo/pgVector
https://github.com/pgvector/pgvector
https://discuss.pytorch.kr/t/2023-picking-a-vector-database-a-comparison-and-guide-for-2023/2625
https://tembo.io/blog/vector-indexes-in-pgvector