Redis와 Key-Value 벤치마크
캐시 데이터가 필요하다면 Redis를 박고 보는게 당연한 공식이 된 세상이다.
하지만 기술 도입에는 항상 엄밀한 자문이 필요하다.
"왜 Redis가 필요한가? 왜 Redis여야 하는건가? Redis를 쓰면 뭐가 좋은가?"
사실 Redis가 하는건 RDB들로도 전부 할 수 있다. 인메모리 데이터베이스가 일반 데이터베이스에 대해 가지는 유일하고도 가장 강력한 이점은 "레이턴시", 처리 시간 뿐이다.
데이터소스를 메모리에만 올려서 쓰니, 데이터가 디스크에 있는 일반 데이터베이스에 비해서는 빠를 수 밖에 없는 것이다.
근데 사실 또 그거 외에는 일반 데이터베이스에 비해서 후달리는 부분밖에 없다. 데이터 확장성에 취약하고, 데이터 손실 위험도 높다.
그래서 요지는, 일반적인 사용사례에서는 그냥 RDB를 KV로 쓰는게 더 좋을 수도 있다는 것이다.
물론 레이턴시가 중요한 사용사례에서는 Redis가 필요할 수 있다.
이번 벤치마크는 그 판단근거로 삼기 위해서 돌려서 기록해둔 것이다.
벤치마크에 사용한 코드는 깃헙에 있다.
https://github.com/myyrakle/benchmarks/tree/master/kv_latency
DB들
벤치마크에 사용한 DB는 Redis, Memcached, PostgreSQL, MySQL이다.
services:
memcached:
image: memcached:1.6.9
ports:
- "21211:11211"
deploy:
resources:
limits:
cpus: "1"
memory: 1024M
redis:
image: redis:7.0.11
ports:
- "16379:6379"
deploy:
resources:
limits:
cpus: "1"
memory: 1024M
postgres:
image: postgres:16.0
ports:
- "15432:5432"
environment:
POSTGRES_USER: testuser
POSTGRES_PASSWORD: testpassword
POSTGRES_DB: testdb
deploy:
resources:
limits:
cpus: "1"
memory: 1024M
mysql:
image: mysql:8.0.34
ports:
- "13306:3306"
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: testdb
MYSQL_USER: testuser
MYSQL_PASSWORD: testpassword
deploy:
resources:
limits:
cpus: "1"
memory: 1024MCPU는 1개, 메모리 제한은 1G로 걸었다.
그리고 띄웠다.
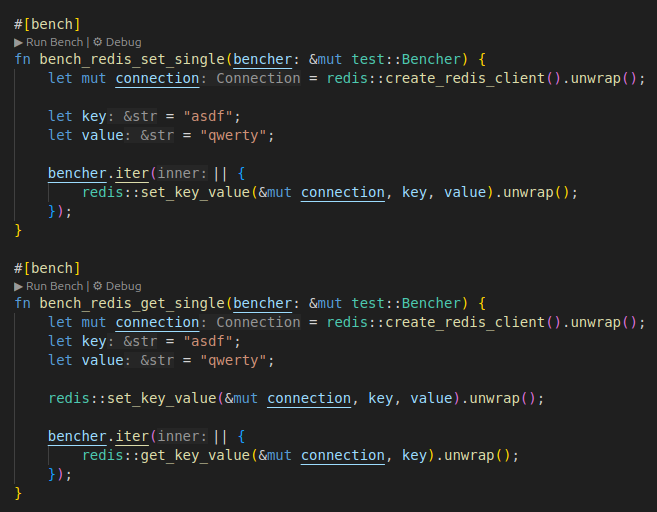
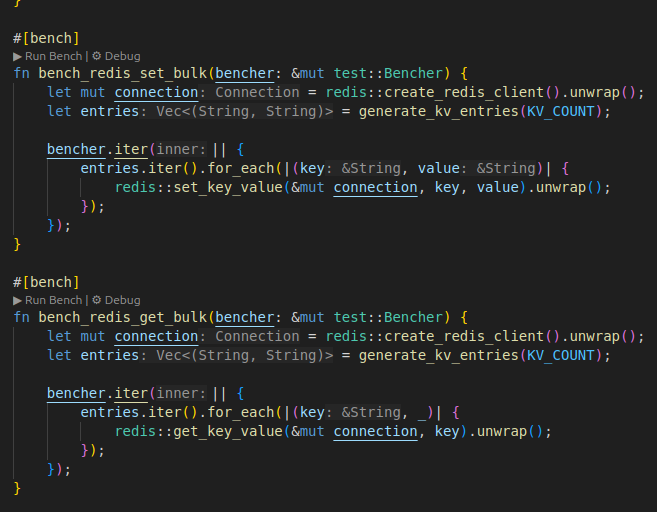
DB별로 set, get 함수 적당히 만들어놓고
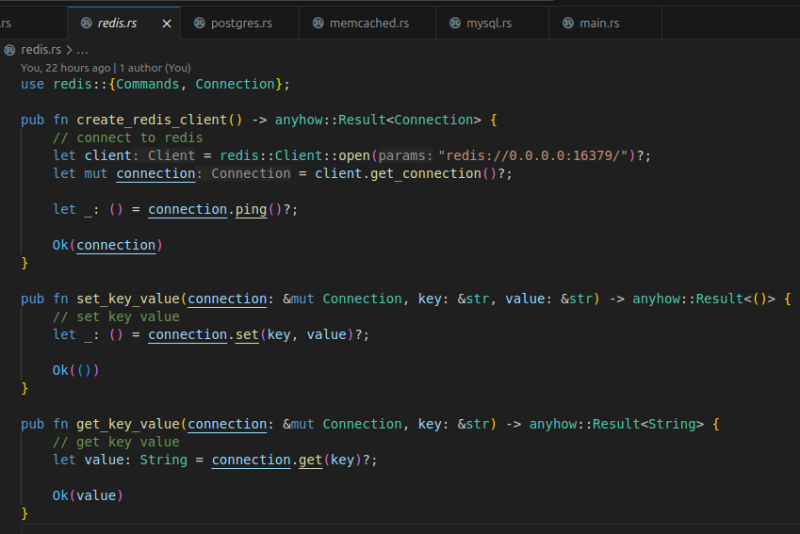
cargo bench를 통해 평균 레이턴시를 측정했다. 여러번 돌려서 평균 레이턴시와 오차를 구하는 식이다.
지표는 단일조회, 1000번 조회, 단일삽입, 1000번 삽입이다.
네트워크 지연은 고려하지 않았는데, 환경에 따라 상수값으로 더해서 고려하면 될 것이다. 어차피 이건 공평하게 적용될 것이다.
그리고 실제 라이브러리 구현 수준에 따른 오차도 존재할 수 있다. 그래서 엄밀한 수준의 비교가 되진 못함을 유의한다. 대략적인 참고용이다.
벤치마크 결과
역시 Redis가 일반적인 성능은 가장 좋았다.
 단일 조회 33마이크로초.
단일 조회 33마이크로초.
단일 삽입 38마이크로초.
1000번 조회 3.8밀리초
1000번 삽입 3.8밀리초
Memcached는 예상보다 매우 더디게 나왔다.
 단일조회 145마이크로초
단일조회 145마이크로초
단일삽입 183마이크로초
1000 조회 176밀리초
1000 삽입 173밀리초
Redis에 비하면 이상할 정도로 느렸다. 라이브러리 구현의 문제일 수도 있지만, 아무래도 멀티코어를 고려해서 최적화가 되어있는데 싱글코어의 단순한 사용례라서 손해를 많이 보는게 아닐까 싶었다.
postgres를 key-value로 썼을 때는
 단일조회 127마이크로초
단일조회 127마이크로초
단일삽입 1.7밀리초
1000조회 147밀리초
1000삽입 1.8초
정도가 걸렸다. Redis 등에 비하면 아무래도 쓰기가 조금 느린 편이었다.
하지만 이것도 단일연산은 한자릿수 단위 밀리초나 마이크로초 수준으로 처리가 된다. 그렇게 느리지는 않은 것이다.
mysql도 같은 RDB라 비슷하다.
 단일조회 143마이크로초
단일조회 143마이크로초
단일삽입 3.9밀리초
1000조회 147밀리초
1000삽입 3.9초
정리
대충 정리하자면, 네트워크를 고려해도 통신망만 잘 구성되어있다면 RDB도 10밀리초 미만의 레이턴시를 유지할 수 있을 것이다.
쓰기보다 읽기 레이턴시가 중요하다면 밀리초 단위 미만도 가능할테다.
하지만 읽기와 쓰기 모두에도 마이크로초 단위의 민첩한 처리가 요구된다면 Redis를 위시한 인메모리가 필요한 것은 맞다.
근데 일반적인 서비스에서 그 정도까지 필요할 일은 경험상 잘 없다. 알아서 잘 판단하길 바란다.