[PostgreSQL] 인덱스 최적화: 커버링 인덱스와 분포, 순서
관련 포스트
https://blog.naver.com/sssang97/223531204143
https://blog.naver.com/sssang97/223498028986
최적화에 있어서 최소한의 방향성을 잡아줄 수 있기를 바라면서 정리한 글이다.
커버링 인덱스 사용시에 데이터 분포와 컬럼 순서에 따라 인덱스 성능이 어떻게 유의미한 차이를 보이는지 간단하게 다뤄본다.
사용한 DB는 PostgreSQL이다.
INSERT, UPDATE 시 발생하는 부하는 크게 고려하지 않는다.
테스트 데이터 세팅
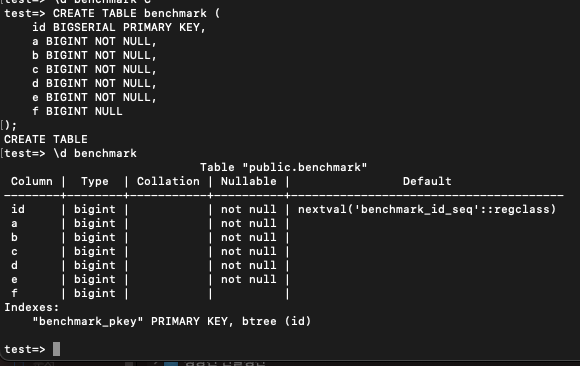
테이블을 하나 만들고
CREATE TABLE benchmark (
id BIGSERIAL PRIMARY KEY,
a BIGINT NOT NULL,
b BIGINT NOT NULL,
c BIGINT NOT NULL,
d BIGINT NOT NULL,
e BIGINT NOT NULL,
f BIGINT NULL
);
각 컬럼별로 분포가 다르게 퍼지게끔 랜덤값을 삽입했다.
INSERT INTO benchmark (a, b, c, d, e, f)
SELECT
(random() * 100)::INTEGER as a,
(random() * 1000)::INTEGER as b,
(random() * 10000)::INTEGER as c,
(random() * 100000)::INTEGER as d,
(random() * 1000000)::INTEGER as e,
CASE
WHEN (random() * 2)::INTEGER < 1 THEN NULL
ELSE (random() * 100)::INTEGER
END AS f
FROM
generate_series(1, 10000000) AS t;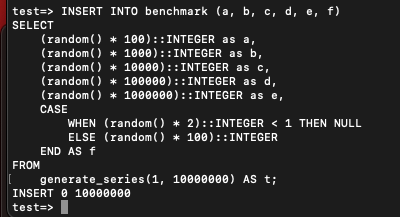
 그래서 적당히 잘 들어간 것을 확인했다.
그래서 적당히 잘 들어간 것을 확인했다.
분포도 확인
인덱스의 효과는 데이터 값의 분포에 따라 달라진다. 인덱스가 걸려있다고 무조건 그걸 타서 실행하는게 아니라 통계를 기반으로 실행하기 떄문이다.
예를 들어, 100개의 데이터에 5가지 값이 있다면 동등비교(=)로 필터를 걸더라도 평균적으로 20개 정도를 가져와서 처리를 한다고 가정할 수 있고, 100개의 데이터에 50가지 값이 있다면 평균적으로 2개 정도를 가져와서 처리를 한다고 볼 수 있다. 그리고 당연히 후자가 데이터를 덜 가져오기 때문에 더 빠르게 동작한다.
그래서 인덱스를 걸 때도 이를 확인하는 것이 중요하다.
SELECT
COUNT(DISTINCT a) as a,
COUNT(DISTINCT b) as b,
COUNT(DISTINCT c) as c,
COUNT(DISTINCT d) as d,
COUNT(DISTINCT e) as e,
COUNT(DISTINCT f) as f
FROM benchmark;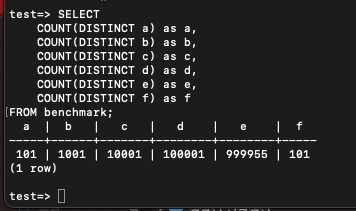 다행히도 딱 예상한 정도로 값이 분포했다.
다행히도 딱 예상한 정도로 값이 분포했다.
여기서 이런 값의 분포를 카디널리티라고 한다. a는 유일한 값의 개수가 적으니, 카디널리티가 낮고, e가 가장 카디널리티가 높다.
커버링 인덱스와 단일 컬럼 인덱스
실제 쿼리 사용사례에 (a) 단일 필터와 (a,c) 복합 필터가 존재한다면, 인덱스의 개수를 줄이기 위해서 (a, c) 복합 필터만을 거는 것을 고려해볼 수 있다.
(c) 필터는 (a, c) 뒤에 있어서 적용이 불가능하지만 앞머리에 있는 컬럼의 부분 인덱싱은 트리를 들어가다 말면 되는 것이기 때문이다.
근데 a 단일 필터에 대해서도 a,c 복합 필터가 충분히 효율적으로 동작할까?
그냥 생각해봤을 때는 a 필터에 대해서는 a 단일 인덱스가 더 잘 동작할 것 같다고 추상적으로 느껴지긴 하지만, 정확한 것은 실험을 해보는 것이 좋을 것이다.
한번 실험해보자. 먼저 테스트해볼 것은 단일 인덱스다.
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(e);
SELECT pg_size_pretty(pg_relation_size('benchmark_test')) AS index_size;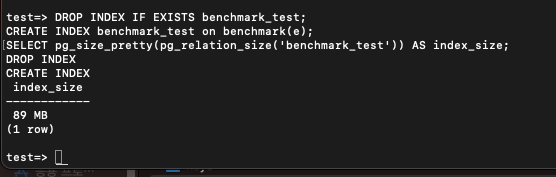
그리고 단순한 LIMIT 쿼리와 COUNT 쿼리를 실행해봤다.
EXPLAIN(ANALYZE) SELECT *
FROM benchmark
WHERE 1=1
AND e > 500000
AND e < 5000000
LIMIT 1000;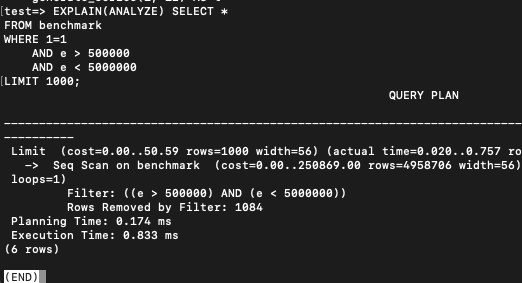
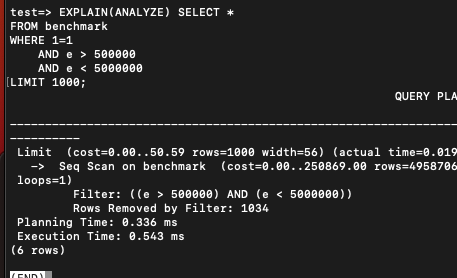 LIMIT 쿼리는 부분적으로 가져오니 500-900마이크로초 정도가 걸렸고
LIMIT 쿼리는 부분적으로 가져오니 500-900마이크로초 정도가 걸렸고
EXPLAIN(ANALYZE) SELECT COUNT(1)
FROM benchmark
WHERE 1=1
AND e > 500000
AND e < 5000000;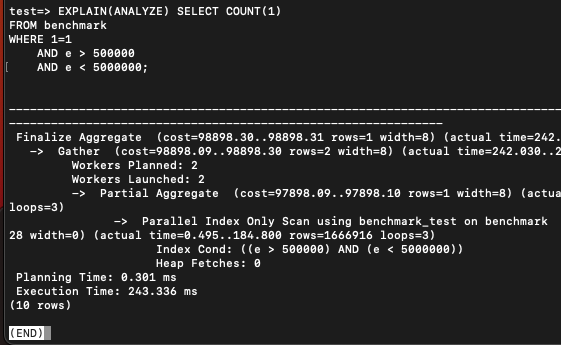 COUNT는 인덱스에 대한 해당 범위 풀스캔을 하니 200밀리초로 좀 느렸다.
COUNT는 인덱스에 대한 해당 범위 풀스캔을 하니 200밀리초로 좀 느렸다.
그리고는 커버링 인덱스를 또 달아봤다.
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(e, c);
SELECT pg_size_pretty(pg_relation_size('benchmark_test')) AS index_size;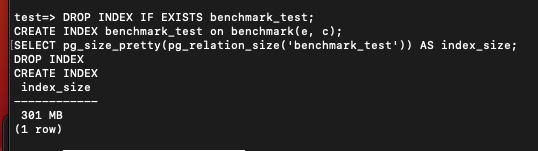 크기는 이전보다 좀 커졌다.
크기는 이전보다 좀 커졌다.
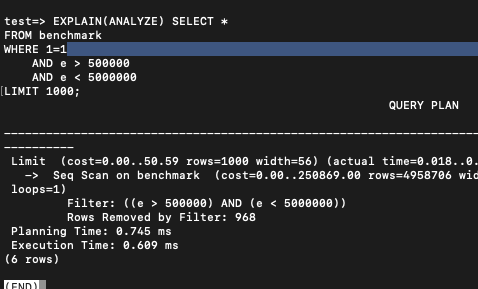 LIMIT SELECT의 경우에는 별다른 차이가 나지 않았다. 컬럼 한두개 차이로는 일반적인 성능 차이가 잘 발생하지는 않는 것이다.
LIMIT SELECT의 경우에는 별다른 차이가 나지 않았다. 컬럼 한두개 차이로는 일반적인 성능 차이가 잘 발생하지는 않는 것이다.
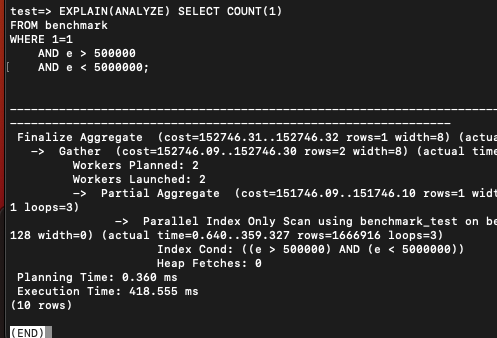 그리고 인덱스 전체 스캔인 COUNT의 경우에는 차이가 좀 났다. 거의 2배 정도였다.
그리고 인덱스 전체 스캔인 COUNT의 경우에는 차이가 좀 났다. 거의 2배 정도였다.
컬럼이 5-6개 정도로 많아지면 더 차이가 날까?
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(e, a, b, c, d, f);
SELECT pg_size_pretty(pg_relation_size('benchmark_test')) AS index_size;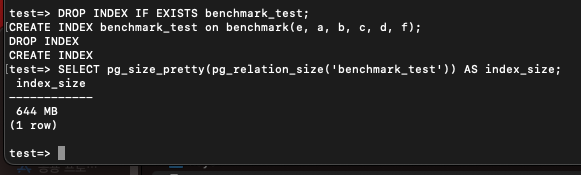 인덱스 크기도 꽤 커지고
인덱스 크기도 꽤 커지고
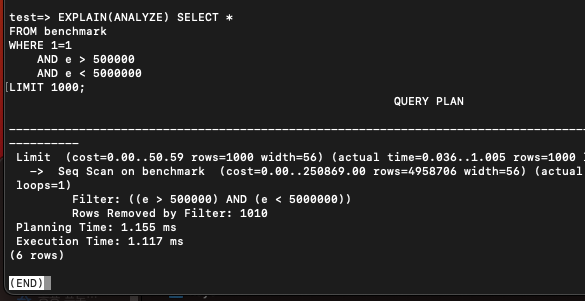 LIMIT 걸고 부분적으로 가져오는 경우에도 인덱스를 타지 못하고 풀스캔을 해버렸다.
LIMIT 걸고 부분적으로 가져오는 경우에도 인덱스를 타지 못하고 풀스캔을 해버렸다.
컬럼 깊이가 지나치게 깊은 경우에는 커버링 인덱스가 그보다 적은 컬럼 필터에 적용되지 못할 수 있는 것이다.
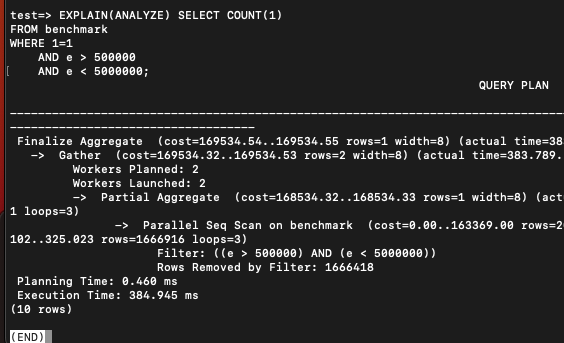 COUNT(1)도 마찬가지다.
COUNT(1)도 마찬가지다.
그리고 이 실험은 리소스가 넉넉한 머신에서 실행한 것이라서, 다양한 변수들이 고려되지는 못했다.
-
커버링 인덱스는 단일 컬럼 인덱스보다 크기가 더 크고, 메모리에 통째로 올리기 어려워진다. 이러면 생각보다 더 느릴 수 있다.
-
커버링 인덱스는 단일 컬럼 인덱스보다 Tree 깊이가 깊어진다. 그래서 디스크 접근량이 늘고, 캐시에도 친화적이지 않을 수 있다.
중소규모의 테이블에서, (a) 스캔에 (a,b) 인덱스를 쓰는 정도의 성능 차이는 감수할 만한 것 같다.
하지만 테이블 규모가 크거나, 커버링 컬럼의 깊이가 깊어지면 잘 타지 않을 수 있다.
이건 사실 데이터나 환경에 따라서 판단 기준이 달라질 수 있어서, 결국 명쾌한 기준을 제시하기는 어려울 것 같다. 직접 돌려보고 판단하라.
인덱스의 순서
순서도 꽤 중요한 부분이다. 같은 컬럼들로 구성이 되어있더라도 컬럼 순서에 따라서 성능이 급격하게 갈리고, 아예 인덱스가 걸리지 않을 확률도 높다.
Tree 검색 구조에서는 첫번째 컬럼 스캔에서 최대한 적게 가져온 뒤에, 이후 컬럼에서 걸러내는 것이 일반적으로 검색 성능이 우월하다.
이 경우에는 c 컬럼(1만가지)의 유일성이 높고 a 컬럼(100가지)의 유일성이 낮다고 할 수 있다.
이럴때 c 컬럼이 카디널리티가 높다고 말한다.
우리는 이 쿼리를 실행해보려 한다.
EXPLAIN(ANALYZE) SELECT COUNT(1)
FROM benchmark
WHERE 1=1
AND d IN (100, 200, 300)
AND a IN (1);실제로 분포를 보면
SELECT COUNT(1)
FROM benchmark
WHERE 1=1
AND a IN (1);
SELECT COUNT(1)
FROM benchmark
WHERE 1=1
AND d IN (100, 200, 300);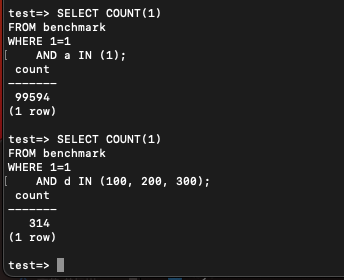 이렇다. d가 훨씬 적은 데이터를 스캔한다.
이렇다. d가 훨씬 적은 데이터를 스캔한다.
한번 나쁜 형태로 인덱스를 먼저 걸어보겠다.
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(a, d);
SELECT pg_size_pretty(pg_relation_size('benchmark_test')) AS index_size;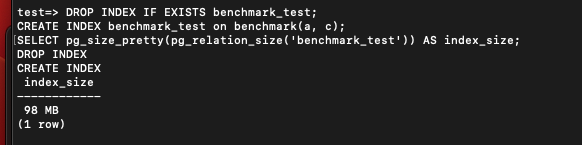 인덱스 크기는 비교적 작으나
인덱스 크기는 비교적 작으나
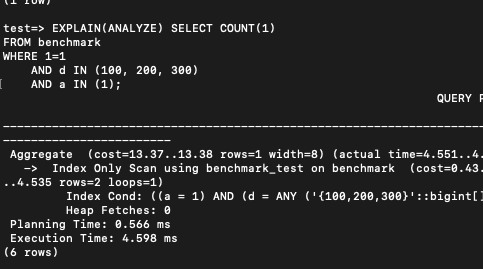 4.5 밀리초 정도가 걸렸다. 사실 아주 느리진 않다.
4.5 밀리초 정도가 걸렸다. 사실 아주 느리진 않다.
그리고 d가 앞에 오는 형태로 다시 인덱스를 만들어봤다.
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(d, a);
SELECT pg_size_pretty(pg_relation_size('benchmark_test')) AS index_size;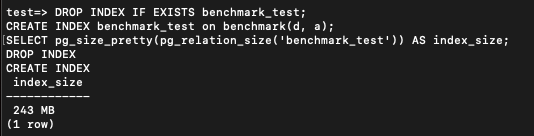
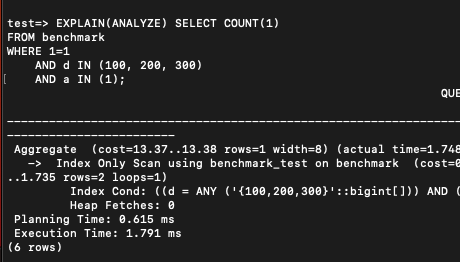 이전보다 2-3배 정도 빨라지긴 했다.
이전보다 2-3배 정도 빨라지긴 했다.
데이터 분포에 차이가 더 난다면 이보다 벌어지거나, 아예 인덱스를 타고 타지 않는 것으로 나뉠 수도 있다.
커버링 인덱스와 Partial Index
쿼리를 짜다보면, 특정 필드를 기준으로 아예 하드코딩된 배제를 하는 조건도 종종 걸게 된다.
예를 들어, deleted_at IS NULL로 삭제되지 않은 것만 조회한다거나 하는 것은 고정형으로 들어가기 마련이다.
이런 경우에는 Partial Index를 우선적으로 고려해볼만하다.
https://blog.naver.com/sssang97/223498028986
단순 복합 인덱스를 걸면 NOT NULL을 조건으로 Tree를 검색하는데, Partial Index로 배제를 할 경우에는 애초에 인덱스에도 들어가지 않기 때문이다. 스캔이 훨씬 줄어들고, 배제가 되는 것을 확실히 보장할 수 있다.
한번 실험해보자.
먼저 커버링 인덱스를 만들었다.
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(a, f);SELECT pg_size_pretty(pg_relation_size('benchmark_test')) AS index_size; 크기는 69mb 정도다.
크기는 69mb 정도다.
그리고 적당히 집계를 날려봤다.
EXPLAIN(ANALYZE) SELECT COUNT(1)
FROM benchmark
WHERE 1=1
AND a < 500000
AND f IS NOT NULL;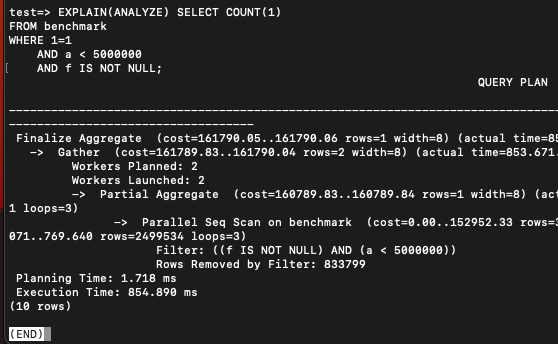 이 경우에는 꽤 느렸다. 인덱스가 걸려있음에도 인덱스를 잘 타지 못한 것이다.
이 경우에는 꽤 느렸다. 인덱스가 걸려있음에도 인덱스를 잘 타지 못한 것이다.
a로 먼저 들어간 다음에 NOT NULL 배제를 하는 것이 비효율적이라 판단하고 그냥 풀스캔을 한 것이다.
인덱스 컬럼 순서를 바꾸면 좀 달라질까?
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(f, a);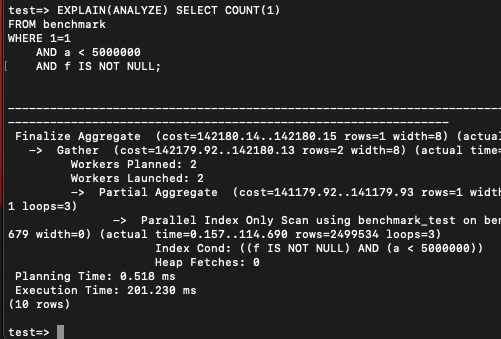 다행히 이렇게 하면 의도한대로 인덱스를 타서 빠르게 동작하긴 한다.
다행히 이렇게 하면 의도한대로 인덱스를 타서 빠르게 동작하긴 한다.
이번에는 Partial 인덱스를 사용해보자.
DROP INDEX IF EXISTS benchmark_test;
CREATE INDEX benchmark_test on benchmark(a) WHERE f IS NOT NULL;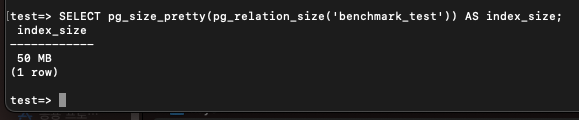
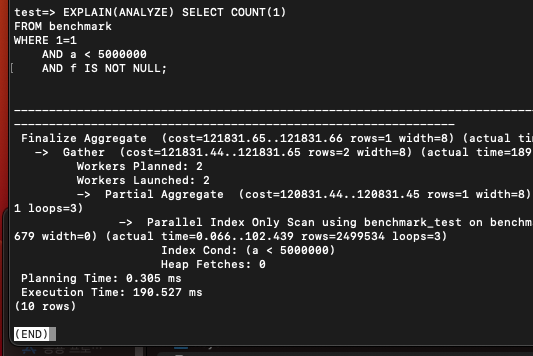 이 경우에는 10~20ms 정도의 속도 향상이 있었다. 예상한 것보다 적긴 했는데 속도가 좀 더 빠르긴 하다.
이 경우에는 10~20ms 정도의 속도 향상이 있었다. 예상한 것보다 적긴 했는데 속도가 좀 더 빠르긴 하다.
하지만 데이터 분포와 관계없이 명확하게 배제를 통한 인덱스 성능 향상이 보장된다는 것, 인덱스 크기가 줄어들고 INSERT/UPDATE 비용이 줄어든다는 장점들이 있기 때문에 사용사례가 부합한다면 Partial Index가 최적의 선택이라고 할 수 있을 것 같다.