binary encoding 구현해보기 (with Rust)
자체 프로토콜이나 파일 저장 규격 같은 것을 구현한다면, 직접 바이너리 전송/저장 규격을 정의해야할 때가 종종 있다.
그냥 무지성으로 JSON 같은걸 쓰거나 flatbuffer 같은 타사 구현체를 쓸 수도 있지만, 때로는 직접 만들어서 쓰고 싶을 수도 있을 테다.
여기서는 바이너리 인코딩 구현체를 적당히 간단하게 만들어보는 법을 다뤄본다.
STEP 1: 기초 설계
바이너리 포맷은 보통 어떤 식으로 구현할까?
이런 형태의 구조체가 있다고 가정해보겠다.
{ a: "foo", b: "bar", c: "asdf" }
그럼 그냥 순서대로 적당히 구분자 두고 압축하면 어떨까?
"foo bar asdf"
정말 간단한 사용사례에서는 이렇게 처리해도 충분할 수 있을 것이다.
그런데 저 구분자와 동일한 값이 각 element에 들어가면 어떻게 해야할까?
결국 구분자를 위한 이스케이프 처리가 필요하게 될 것이다. 근데 이것도 이스케이스 예외처리를 하다보면 끝도 없고, 완전하게 구현하기도 매우 어려운 편이다.
그래서 보편적으로 사용하는 방법은, 각 필드마다 값 앞에 Length 태그를 넣는 것이다.
Length 영역의 4바이트를 앞에 배치하고, 그 길이만큼의 값을 뒤에 배치하고의 반복으로 설계하는 것이다.
그러면 읽을 때도 먼저 4바이트를 읽은 다음에 그 길이만큼만 가져와서 처리를 한다거나 할 수 있다.
STEP 2: 인코딩/디코딩 구현해보기
자, 구조체를 하나 만들고, 방금 설계안에 따라서 패킷 인코딩/디코딩 로직을 구현해보겠다.
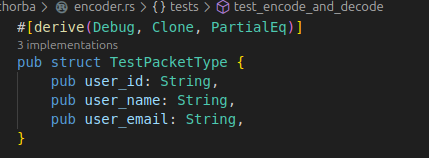 단순성을 위해서 필드의 타입은 문자열만 고려하겠다.
단순성을 위해서 필드의 타입은 문자열만 고려하겠다.
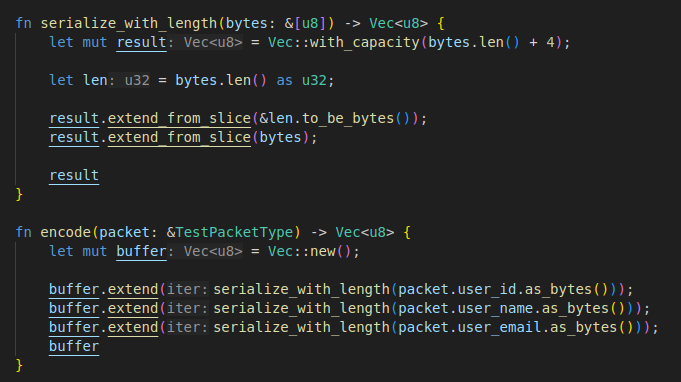 직렬화 로직은 아까 이야기했던대로 데이터의 길이를 고정 4바이트로 집어넣고, 바로 이어서 값을 집어넣도록 했다.
직렬화 로직은 아까 이야기했던대로 데이터의 길이를 고정 4바이트로 집어넣고, 바로 이어서 값을 집어넣도록 했다.
저 길이 태그로 인해서 각 필드를 구분할 수 있기 때문에, 요소들을 다 딱 붙여서 최종 encode 값을 생성하도록 했다. 구현 자체는 매우 단순하다.
이번에는 디코딩 로직이다.
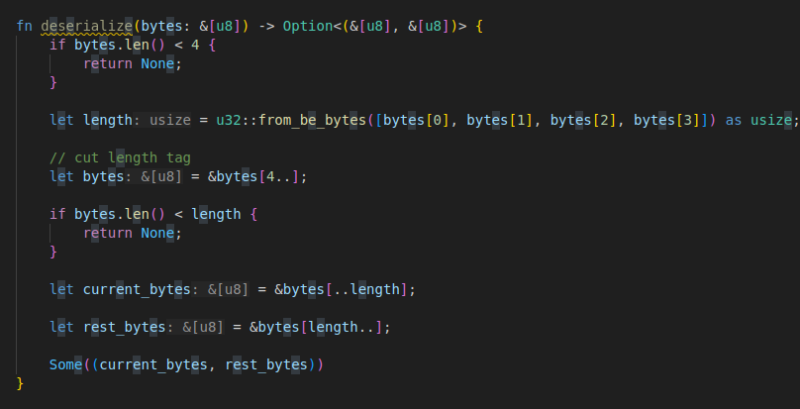 인코딩보다는 조금 복잡한데, 잘 보면 그 역순에 불과하다.
인코딩보다는 조금 복잡한데, 잘 보면 그 역순에 불과하다.
약간 재귀적으로 해체할 수 있게끔 만들어놔서 조금 비직관적으로 보일 수 있다.
4바이트를 먼저 읽고, 그만큼만 데이터로서 슬라이싱한 다음에, 바로 획득한 데이터와 그 나머지를 반환하게 했다.
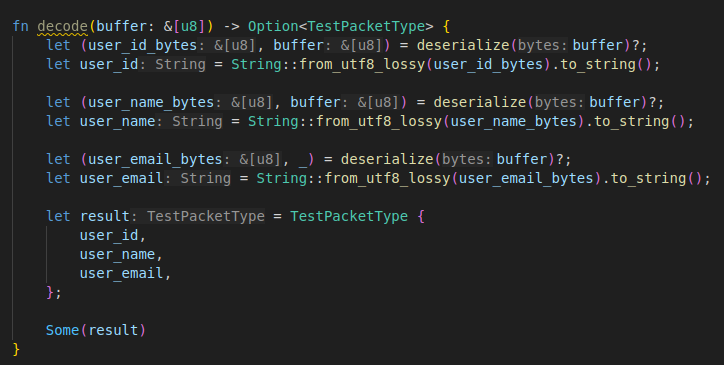 구조체 전체 파싱에서는 그걸 연달아 호출하기만 하면 된다.
구조체 전체 파싱에서는 그걸 연달아 호출하기만 하면 된다.
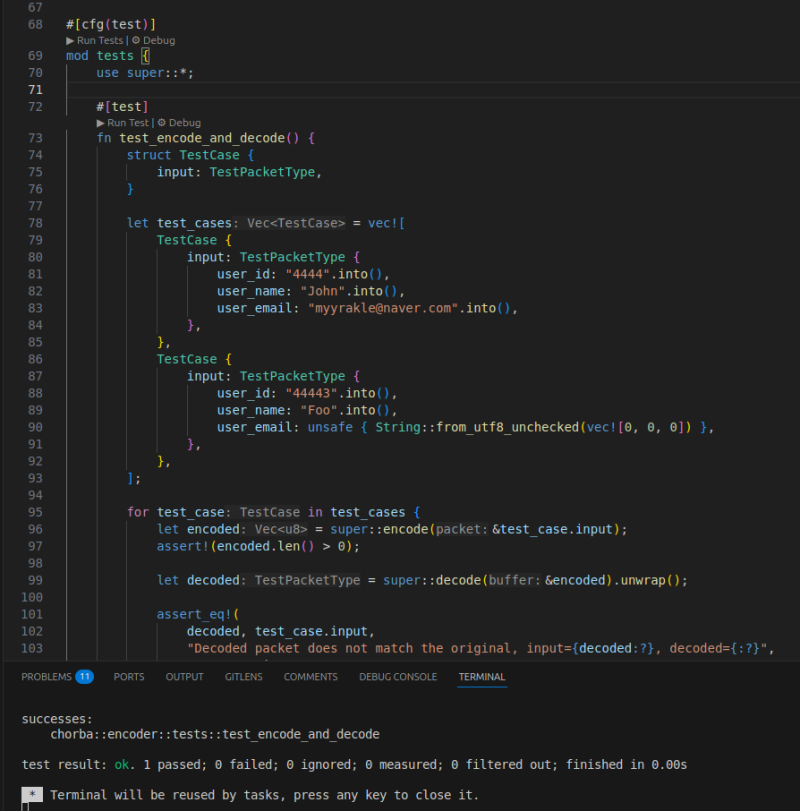 자, 의도한대로 잘 동작했다.
자, 의도한대로 잘 동작했다.
다음은 전체 코드다.
#[derive(Debug, Clone, PartialEq)]
pub struct TestPacketType {
pub user_id: String,
pub user_name: String,
pub user_email: String,
}
fn serialize_with_length(bytes: &[u8]) -> Vec<u8> {
let mut result = Vec::with_capacity(bytes.len() + 4);
let len = bytes.len() as u32;
result.extend_from_slice(&len.to_be_bytes());
result.extend_from_slice(bytes);
result
}
fn encode(packet: &TestPacketType) -> Vec<u8> {
let mut buffer = Vec::new();
buffer.extend(serialize_with_length(packet.user_id.as_bytes()));
buffer.extend(serialize_with_length(packet.user_name.as_bytes()));
buffer.extend(serialize_with_length(packet.user_email.as_bytes()));
buffer
}
fn deserialize(bytes: &[u8]) -> Option<(&[u8], &[u8])> {
if bytes.len() < 4 {
return None;
}
let length = u32::from_be_bytes([bytes[0], bytes[1], bytes[2], bytes[3]]) as usize;
// cut length tag
let bytes = &bytes[4..];
if bytes.len() < length {
return None;
}
let current_bytes = &bytes[..length];
let rest_bytes = &bytes[length..];
Some((current_bytes, rest_bytes))
}
fn decode(buffer: &[u8]) -> Option<TestPacketType> {
let (user_id_bytes, buffer) = deserialize(buffer)?;
let user_id = String::from_utf8_lossy(user_id_bytes).to_string();
let (user_name_bytes, buffer) = deserialize(buffer)?;
let user_name = String::from_utf8_lossy(user_name_bytes).to_string();
let (user_email_bytes, _) = deserialize(buffer)?;
let user_email = String::from_utf8_lossy(user_email_bytes).to_string();
let result = TestPacketType {
user_id,
user_name,
user_email,
};
Some(result)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_encode_and_decode() {
struct TestCase {
input: TestPacketType,
}
let test_cases = vec![
TestCase {
input: TestPacketType {
user_id: "4444".into(),
user_name: "John".into(),
user_email: "myyrakle@naver.com".into(),
},
},
TestCase {
input: TestPacketType {
user_id: "44443".into(),
user_name: "Foo".into(),
user_email: unsafe { String::from_utf8_unchecked(vec![0, 0, 0]) },
},
},
];
for test_case in test_cases {
let encoded = super::encode(&test_case.input);
assert!(encoded.len() > 0);
let decoded = super::decode(&encoded).unwrap();
assert_eq!(
decoded, test_case.input,
"Decoded packet does not match the original, input={decoded:?}, decoded={:?}",
test_case.input
);
}
}
}문자열 외 다른 타입으로 확장하는 것도 어렵지 않다.
그냥 하면 된다.
STEP 3: trait과 매크로 활용하기
근데 위처럼 그냥 무식하게 구현하는 것은 실제로 폭넓게 운영하기는 어렵다. 패킷 형식이 추가되고 변경될때마다 저 노가다를 반복할 수도 없는 일 아닌가?
다행히 Rust는 매크로와 trait 기반의 확장을 이용해서 성능 손실 없이 이러한 반복적인 코드 생성을 자동화할 수가 있다. serde 기반의 라이브러리들이 그러한 존재들인데, 여기서는 서드파티 배제하고 직접 깎아보겠다.
핵심 원리는 그렇게 어려울 것이 없다.
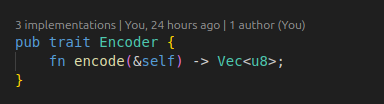
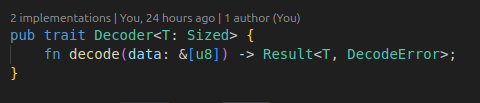 일단 동작의 정의를 위해서 인코딩/디코딩에 대한 트레잇을 만든다.
일단 동작의 정의를 위해서 인코딩/디코딩에 대한 트레잇을 만든다.
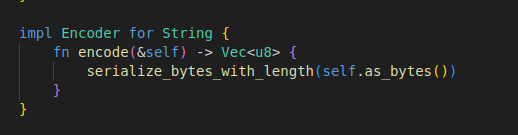
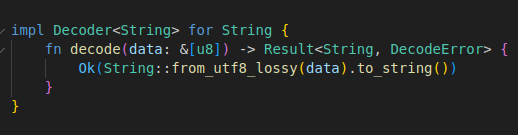 문자열에 대한 변환만 정의해두겠다.
문자열에 대한 변환만 정의해두겠다.
정수나 boolean 같은걸 정의하는 것도 사실 쉽지만, 일단은 지나친다.
그리고 이제 아까 했던 구조체 수준의 필드 값 조합을, 매크로를 통해 할 수 있도록 해보겠다.
Rust에서는 매크로 정의를 별도 crate으로 빼야하기 때문에, 불가피하게 구조를 좀 분리했다.
디펜던시는 이 정도만 넣으면 된다.
[dependencies]
syn = { version = "2", features = ["full", "extra-traits"] }
quote = "1.0"
[lib]
proc-macro=true
[lints]
workspace = true그리고... 코드 생성을 derive 매크로를 통해 할 수 있도록 적당히 노가다를 친다.
use std::str::FromStr;
use proc_macro::TokenStream;
use quote::ToTokens;
#[proc_macro_derive(Encode)]
pub fn derive_encode(item: TokenStream) -> TokenStream {
let mut new_code = "".to_string();
let ast = syn::parse_macro_input!(item as syn::ItemStruct);
let struct_name = ast.ident.to_string();
new_code += format!(r#"impl chorba::Encoder for {struct_name} {{"#).as_str();
{
new_code += r#"fn encode(&self) -> Vec<u8> {"#;
{
new_code += r#"let mut buffer = Vec::new();"#;
for field in ast.fields.iter() {
let field_name = field.ident.as_ref().unwrap().to_string();
new_code +=
format!(r#"let bytes = chorba::Encoder::encode(&self.{field_name});"#).as_str();
new_code += format!(r#"buffer.extend(bytes);"#).as_str();
}
new_code += r#"buffer"#;
}
new_code += r#"}"#;
}
new_code += "}";
return TokenStream::from_str(new_code.as_str()).unwrap();
}
#[proc_macro_derive(Decode)]
pub fn derive_decode(item: TokenStream) -> TokenStream {
let mut new_code = "".to_string();
let ast = syn::parse_macro_input!(item as syn::ItemStruct);
let struct_name = ast.ident.to_string();
new_code += format!(r#"impl chorba::Decoder<{struct_name}> for {struct_name} {{"#).as_str();
{
new_code +=
format!(r#"fn decode(buffer: &[u8]) -> Result<{struct_name}, chorba::DecodeError> {{"#)
.as_str();
{
let mut field_names = vec![];
for field in ast.fields.iter() {
let field_name = field.ident.as_ref().unwrap().to_string();
let field_type = field.ty.to_token_stream().to_string();
field_names.push(field_name.clone());
new_code +=
format!(r#"let ({field_name}_bytes, buffer) = chorba::deserialize(buffer).ok_or(chorba::DecodeError::InvalidLength)?;"#)
.as_str();
new_code +=
format!(r#"let {field_name} = <{field_type} as chorba::Decoder::<{field_type}>>::decode({field_name}_bytes)?;"#)
.as_str();
}
new_code += format!(r#"Ok({struct_name} {{"#).as_str();
for field_name in field_names.iter() {
new_code += format!(r#"{field_name},"#).as_str();
}
new_code += "})";
}
new_code += r#"}"#;
}
new_code += "}";
return TokenStream::from_str(new_code.as_str()).unwrap();
}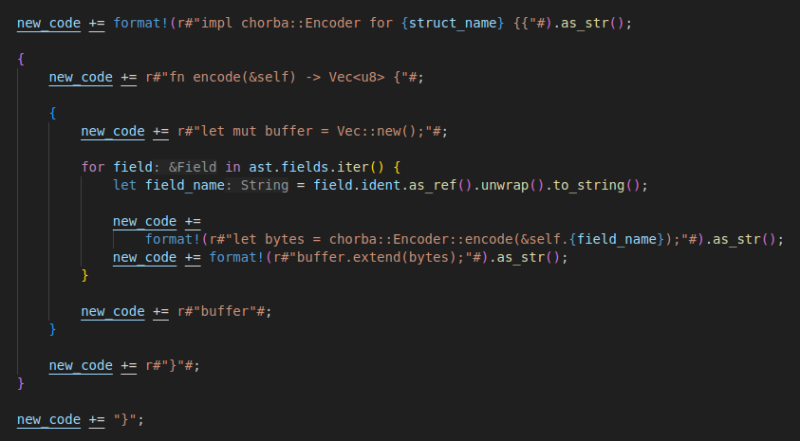
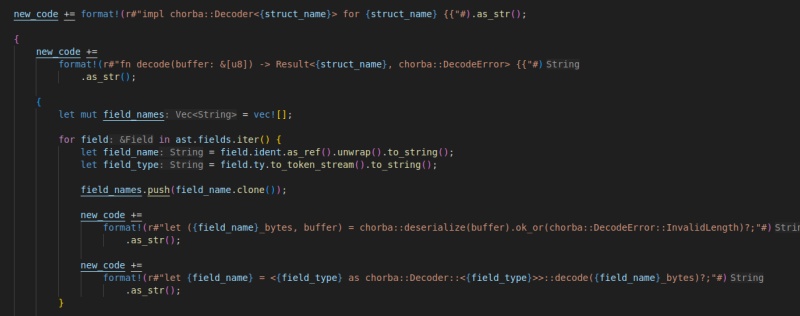 좀 번잡해보이는데, 핵심은 단순하다.
좀 번잡해보이는데, 핵심은 단순하다.
구조체의 필드들을 정적으로 파싱해서 구조체 자체에 대한 Encoder와 Decoder를 구현하는 것이 다다.
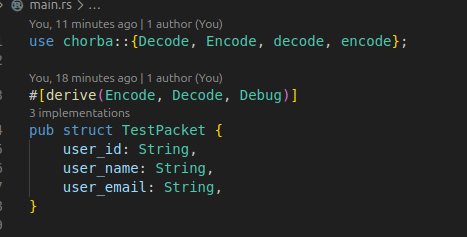 그러면 이렇게 derive를 통해서 trait 구현을 주입할 수 있고
그러면 이렇게 derive를 통해서 trait 구현을 주입할 수 있고
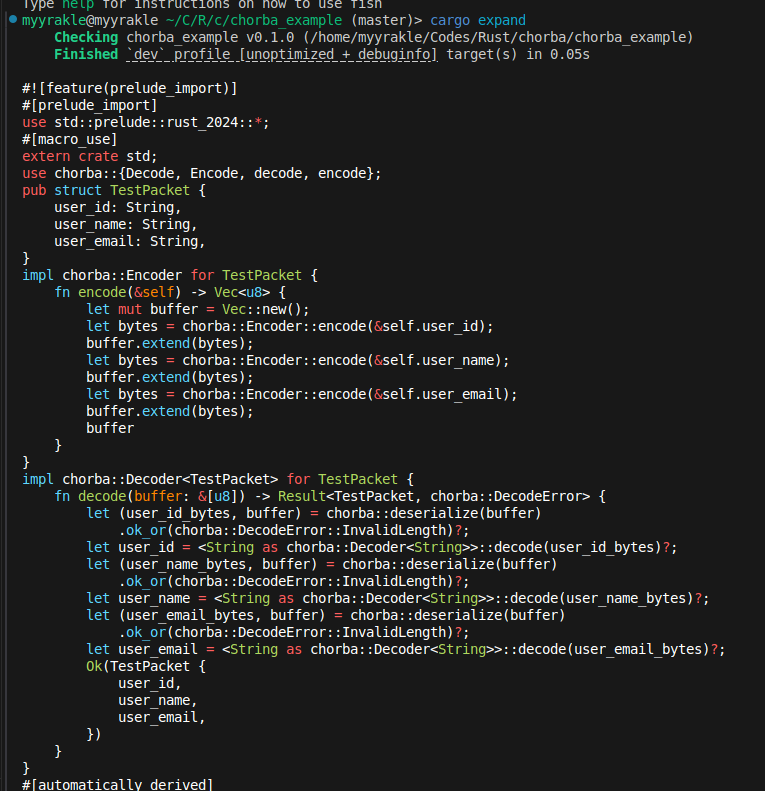 매크로가 확장되면 이런 식으로 trait 구현이 주입된다.
매크로가 확장되면 이런 식으로 trait 구현이 주입된다.
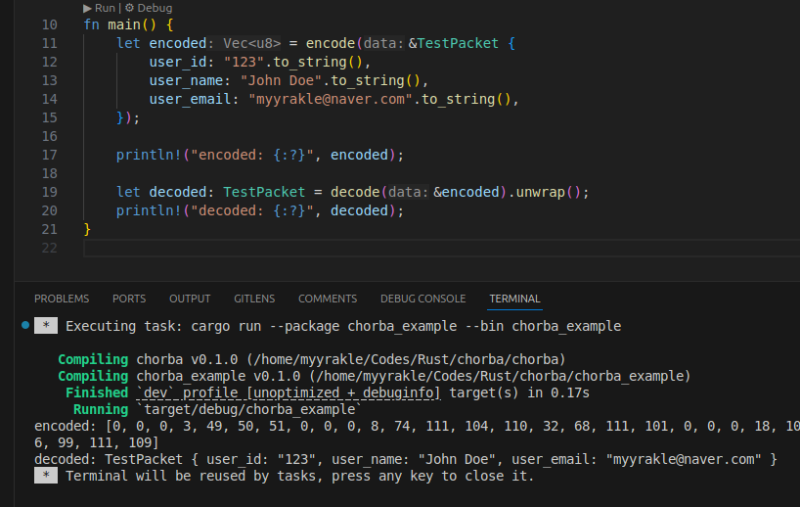 그럼 이제 적당히 가져다가 encode, decode 딸깍 눌러서 쓰면 되는 것이다.
그럼 이제 적당히 가져다가 encode, decode 딸깍 눌러서 쓰면 되는 것이다.
TODO
조금 보면 알겠지만, 여기에는 단점들이 꽤 있다.
순서가 중요해서 실수로 순서가 섞이면 꼬일 수도 있고, 중간에 필드들이 추가될 경우의 하위호환을 보장할 수 없기도 하다.
게다가 압축 같은 것을 고려하지 않아서 데이터 전송에는 유리하지 않을 수도 있다.
직접 만들어서 실제 시스템에 사용할 생각이 있다면, 이런 부분들도 보완해보면 좋을 것이다.
프로젝트 전체 구성과 코드는 깃헙에 있다.
https://github.com/myyrakle/chorba/tree/v0.1.0