[Database] 데이터의 분산: 샤드와 레플리카
데이터베이스는 그 구조의 한계상, 사용 형태나 크기가 일정 범위를 넘어서면 단순한 단일 머신 사용 구조로는 감당하는 것이 거의 불가능해진다.
그냥 MySQL에 테이블 하나 만들고 집어넣어서 쓰는 구조에는 분명한 한계가 존재하는 것이다.
그래서 확장을 염두에 둬야 하거나, 분산 구조를 가진 데이터베이스를 사용한다면 알아야할 것들이 몇가지 있다.
관련된 기본 용어 정리다.
Clustering와 Node
클러스터, 클러스터링이란 여러개의 머신을 연결해서 하나의 군집형 시스템을 만드는 것을 말한다.
보통 DB 수준에서 여러개의 머신을 연결해서 사용하는 것을 클러스터라고 표현한다.
그림으로 표현하면 이렇다. 별건 없다.
 각각의 머신 단위는 보통 노드라고 부른다.
각각의 머신 단위는 보통 노드라고 부른다.
클러스터를 구성하는 목적은 한가지가 아닐 수 있다.
단순히 동일 데이터를 복제해서 가용성을 증가시키기 위함일 수도 있고, 매우 큰 데이터를 잘게 쪼개서 저장하기 위한 것일 수도 있다.
혹은 전부일 수도 있다. 이건 사용사례에 따라 다르다.
상세한 것은 아래에서 이어서 다루겠다.
Replication
이건 클러스터에서 노드마다 데이터를 복제시켜놓는 것을 말한다. 이 경우 각각의 복제본을 replica라고 한다.
약간 유의할 점은, replica 자체는 데이터를 쪼개는게 아니라 복사본을 만드는 것일 뿐이란 것이다.
replication을 구성하는 것도 목적이 한가지가 아닐 수도 있다.
1. 가용성
공통되는 목적은 가용성의 증가다.
replica 노드 중에 하나가 뻗더라도, 남아있는 replica들을 통해 데이터를 보존하고 동작을 유지할 수 있다.
이건 기본적으로 가져가는 부분이다.
2. 읽기 처리량 증가
단순히 읽기 전용 replica를 여러개 만들어서 읽기 처리량을 병렬적으로 증가시키는 용도로 쓰일 수도 있다.
RDB의 master-slave 구성이나 MongoDB 같은 데이터베이스들이 이러한 접근법을 취한다.
3. 쓰기 처리량 증가
혹은, 읽기와 쓰기를 모두 분산하는 용도로 replica를 구성할 수도 있다.
CassandraDB 같은 일부 데이터베이스들이 이러한 방식을 취한다.
참조
https://m.blog.naver.com/sssang97/223038029971
Sharding
샤딩은 큰 데이터를 효율적으로 처리하기 위한 분할 저장 기법이다.
파티셔닝(partitioning)이란 용어로 불리기도 한다. 정확히는 horizontal partitioning이라고 하는데, 굳이 이렇게 엄밀하게 따질 필요까지는 없을거같다. 파티션이라고 하면 다 알아먹는다.
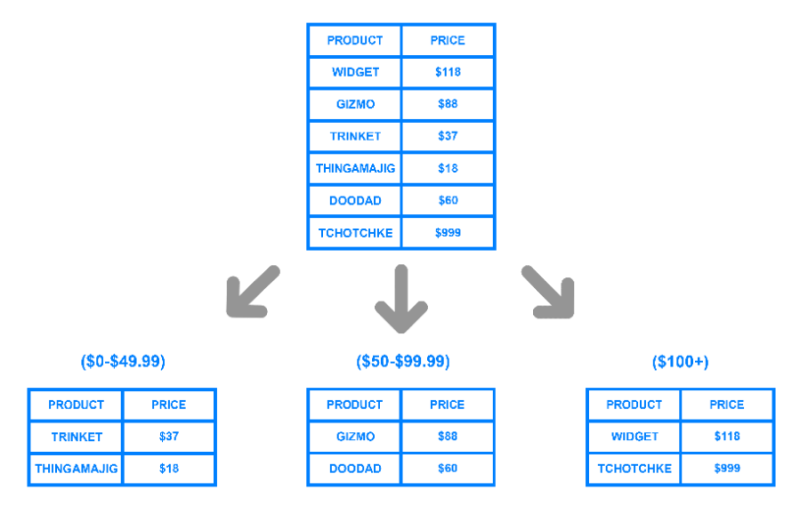 https://www.digitalocean.com/community/tutorials/understanding-database-sharding
https://www.digitalocean.com/community/tutorials/understanding-database-sharding
샤딩은 하나의 데이터를, 특정 기준을 세워서 별도로 저장하는 것으로 이점을 취하는 방법론이다.
예를 들어, 몇억개의 데이터를 쌓아서 사용해야 한다고 하면, 그걸 RDB 단일 머신 단일 테이블로 잘 관리하는 것은 거의 불가능한 일이다.
결국 분할해서 관리하는 수 밖에 없고, 그 분할 방법론을 샤드라고 부르는 것이다.
샤드는 단일 노드에만 쪼개서 저장할 수도 있고, 멀티노드에서 각각의 노드에 물리적으로 분산할 수도 있다.
샤드 자체가 그렇게 엄밀한 개념은 아니라서 상세한 분할 매커니즘은 구현 방식에 따라 많이 다르다.
A. 단일 노드에서의 샤딩
가장 고전적인 방식은, 그냥 RDB 테이블을 직접 하나하나 만들어서 라우팅하는 것이 있다.
예를 들어, 로그 데이터를 쌓을때 날짜별로 테이블을 만들어서 따로 쌓는 것이다.
요즘에는 이보단 발전해서 굳이 테이블을 손으로 만들기보다는, 대부분 파티션 키(혹은 샤드 키)를 설정해서 그 값을 기반으로 파티션이 자동으로 나뉘도록 구성을 한다.
PostgreSQL의 경우에는 자동화되는 파티션 옵션을 제공한다.
https://blog.naver.com/sssang97/222907546000
장점
장점은 파티션 단위에서의 읽기와 쓰기가 매우 효율화될 수 있다는 것이다. 당연히 큰 데이터 덩어리보다는 작은 파티션 단위로 풀스캔이나 인덱스 스캔을 하는 것이 훨씬 리소스를 적게 사용하고 빠르다.
단점
단점은 여러 파티션에 결치는 혹은 전체에 가까운 넓은 범위에 대한 조회 처리가 어려워진다는 것이다.
사용사례에 맞춰서 파티션 범위를 매우 잘 조정해야 하고, 아무리 잘 조정하더라도 넓은 범위를 조회하는 능력은 현저히 떨어질 수밖에 없다.
B. 멀티 노드에서의 샤딩
샤딩의 모든 힘을 끌어내는 것은 멀티 노드 환경이다.
머신 하나에서 아무리 데이터를 쪼갠다고 하더라도 하드웨어 수준의 제약이 가해지기 때문이다.
하지만 머신이 여러개인 상황에서 샤딩을 구성한다면, 동시에 여러개의 노드에 쿼리를 병렬로 실행해서 더 빠른 처리속도를 이끌어낼 수 있다.
이런 접근방법을 잘 사용하는 것이 대표적으로 Elasticsearch다.
https://blog.naver.com/sssang97/223664367009
CassandraDB 같은 분산 데이터베이스들도 당연히 이러한 접근법을 취한다. 파티션 키를 기준으로 파티션을 여러 노드에 적절히 분산해서 저장한다.
https://blog.naver.com/sssang97/223706344662
장점
이 방식의 장점 중 하나는 매우 큰 데이터를 관리하기 쉽다는 것이다. 머신 하나에 몇테라짜리 데이터를 박을 수도 없는 노릇 아니겠는가?
그래서 Clickhouse, Hbase, ScyllaDB, CassandraDB 같은 대규모 데이터를 제어하기 위한 목적의 데이터베이스들은 멀티노드 샤딩이 기본 동작이다.
단점
단점 중 하나는 데이터의 유실 가능성이 존재한다는 것이다. 노드가 많아질수록, 넓게 분산될수록 부분적으로 파괴될 확률이 증가한다. 그래서 대부분의 분산 데이터베이스들은 각 샤드마다 replica를 설정할 수 있게 해서 가용성을 보장할 수 있게 한다.
그리고 이것도 마찬가지로 여러 파티션에 결치는, 혹은 전체에 가까운 넓은 범위에 대한 조회 처리가 비효율적인건 마찬가지다. 병렬처리를 통해서 최종 성능을 좀 낮출 수 있을 뿐이다.
참조
https://stackoverflow.com/questions/20771435/database-sharding-vs-partitioning