[Qdrant] 사전 필터링과 Payload Index
qdrant는 Payload 필드들에 대한 필터 연산도 꽤 괜찮은 성능을 제공한다.
아래는 데이터 1000만개에 대한 복합 필터 쿼리다.
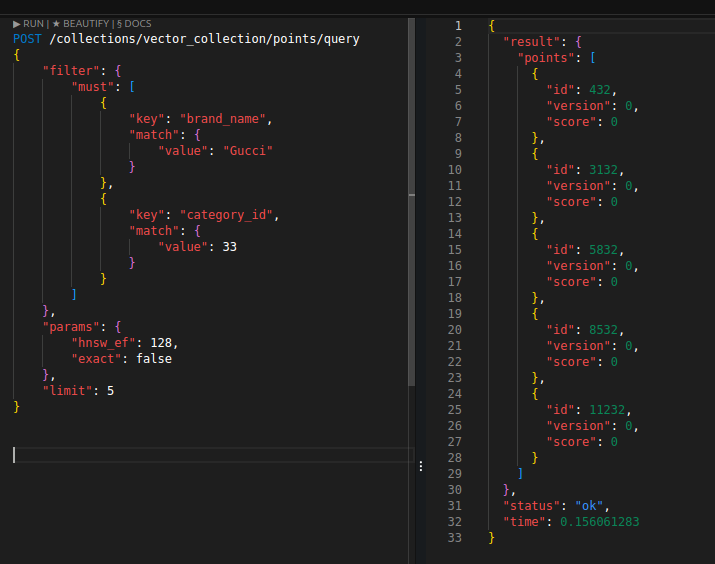 밀리초 단위로 꽤 빠르게 처리가 됐다.
밀리초 단위로 꽤 빠르게 처리가 됐다.
그리고 벡터 검색에 대해서도 필터링을 거는 것이 가능하다.
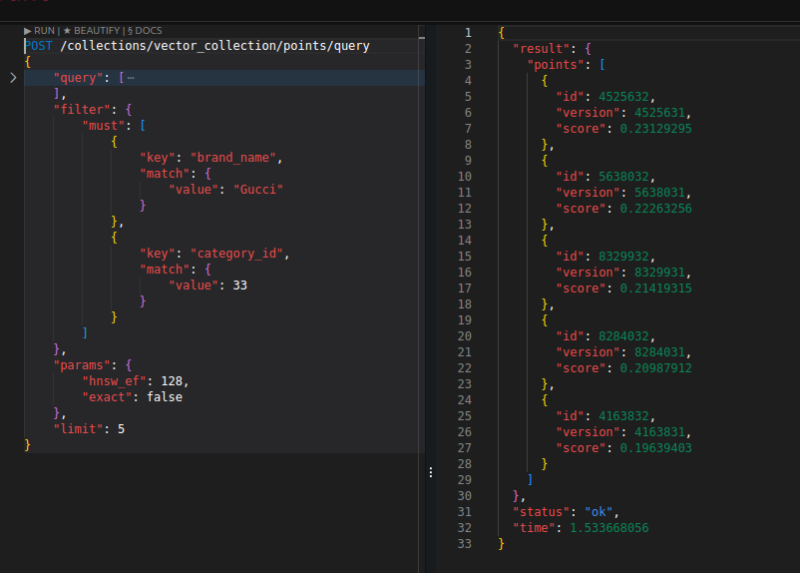 하지만 추가 인덱스 구성 없이는 좀 느릴 수 있다.
하지만 추가 인덱스 구성 없이는 좀 느릴 수 있다.
초 단위로 느리게 처리됐다.
페이로드는 컬렉션에 추가 설정을 하지 않으면 RocksDB 기반으로 디스크 저장을 해서 그렇다.
이 경우를 최적화하려면, 페이로드를 통째로 메모리에 띄우게 하거나, 필터링을 적용할 필드마다 인덱스를 구성해줘야 한다. 권장되는 것은 필요한 값에 대해서만 선택적으로 인덱스를 구성하는 것이다.
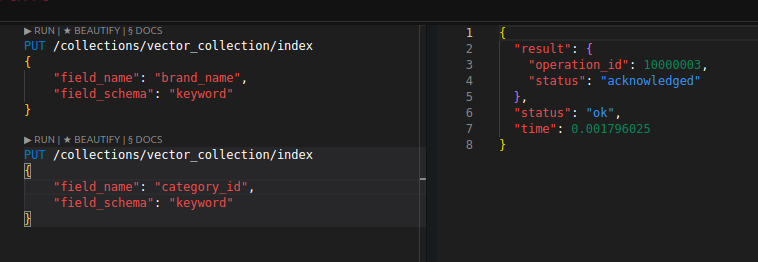 복합 인덱스같은건 없고, column base 구조라서 필드마다 하나씩 만들어놓으면 서로 cross 인덱싱을 해서 적절히 처리한다.
복합 인덱스같은건 없고, column base 구조라서 필드마다 하나씩 만들어놓으면 서로 cross 인덱싱을 해서 적절히 처리한다.
그리고 인덱스를 만들때마다 메모리 사용량이 증가한다. 마구잡이로 만드는것보단 필요한 것만 추가하는 것을 권장한다.
그러고 다시 돌려보면
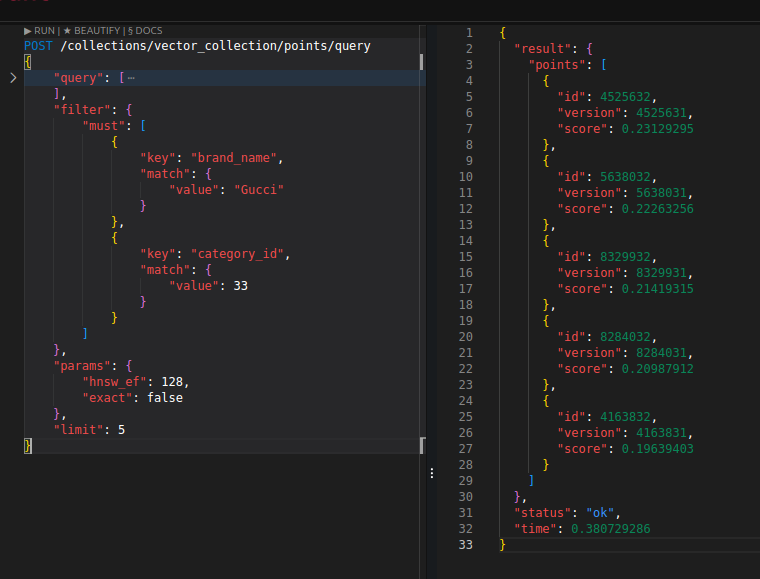 이제 다시 밀리초 단위 연산이 된다.
이제 다시 밀리초 단위 연산이 된다.
참고로, 인덱스는 해당 필드에 분포한 값이 다양할 수록 - 카디널리티가 높을수록 좋은 성능을 보일 수 있다.
인덱스 타입
인덱스 타입에는 몇가지 변형이 있다.
현재 지원되는 인덱스 타입은 이 정도다.
keyword, integer, float, bool, geo, datetime, text, uuid
대표적인 것 몇가지만 대략 정리해보겠다.
keyword
위에서 사용했던 keyword는 가장 기본적인 인덱스 형태다.
a = 'asdf' 같은 동등 match에 대해 인덱스 최적화를 제공하며, 거의 모든 타입에 대해서 적용된다.
예외적으로 배열에 대해서도 인덱싱이 된다. [1,2,3,4]으로 넣어두면 각 요소에 대해서도 인덱싱이 되는 것이다. 그러니까 includes 연산이 된다.
integer
정수 값에 최적화된 인덱스 구조다.
이건 일치 검색 외에도, 정수 값의 범위 검색에 대해서도 인덱싱을 제공한다.
float
부동소수점에 최적화된 인덱스 구조다.
일치 검색 외에도 실수 값 범위 검색에 대한 인덱스를 제공한다.
datetime
날짜 형식에 최적화된 인덱스 구조다.
일치 검색 외에도, 날짜 기반의 범위 검색에 대해서 인덱스를 제공한다.
text
텍스트 형태에 최적화된 인덱스 구조다.
이건 tokenizer 설정을 할 수 있고, inverted index에 기반한 텍스트 포함 검색을 지원한다.
요구사항이 아주 복잡한게 아니라면, Elasticsearch의 텍스트 검색을 어느 정도 대체할 수 있다.
이 기능에 대한 상세는 추후 별도 포스트로 정리해보겠다.
참조
https://qdrant.tech/documentation/concepts/indexing/
https://github.com/orgs/qdrant/discussions/4816