[Milvus] 스칼라 필드 인덱스 (메타데이터 인덱스)
Milvus는 벡터 필드 이외에도, 일반 스칼라 필드에 대해서도 효율적인 인덱싱을 지원한다.
용어가 좀 일관성 없이 와리가리한다. 스칼라 필드 인덱스라고 하기도 하고, 그냥 메타데이터라고 부르기도 하더라.
스칼라 인덱스의 동작 매커니즘은, 여타 컬럼베이스 DB들과 크게 다르지 않다.
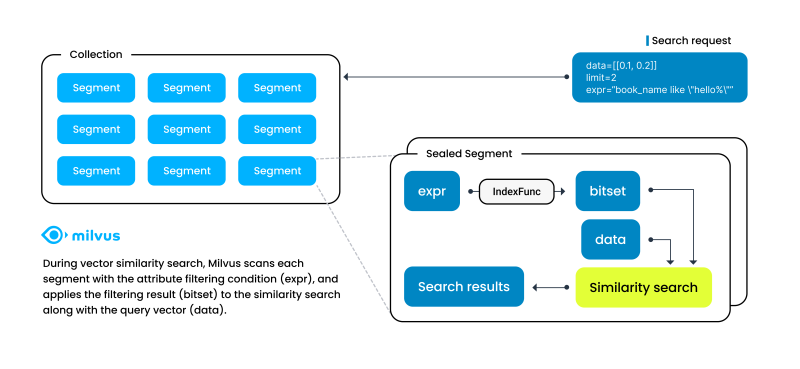 각 필드에 대한 값을 읽고, bitset 단위로 조건 캐시를 관리하면서 필터링을 수행하는 것이다.
각 필드에 대한 값을 읽고, bitset 단위로 조건 캐시를 관리하면서 필터링을 수행하는 것이다.
그래서 복잡한 필터 조건에 대해서도 효율적으로 동작하고, 빠르다.
인덱스 추가
milvus는 스키마에 정의되어있는 필드에 한해서만 인덱스 추가가 된다. 근데 스키마 필드 추가가 동적으로 되지도 않아서 관리상 불편함이 좀 있는 편이다.
이런 식으로 개별 필드에 대한 인덱스를 생성할 수 있다.
###
POST http://{{HOST}}:{{PORT}}/v2/vectordb/indexes/create
Content-Type: application/json
{
"dbName": "default",
"collectionName": "test_collection",
"indexName": "idx_brand_name",
"indexParams": [
{
"indexType": "",
"fieldName": "brand_name",
"indexName": "idx_brand_name"
}
]
}
###indexType를 따로 지정하지 않으면 타입을 따라서 알아서 인덱스를 구성해준다.
벡터 검색과 스칼라 필드 필터링
milvus는 벡터 검색에 사전 필터링을 적용하는 것을 지원한다. 그러니까, 먼저 필터 조건에 맞는 값만 거른 다음에 그 목록을 기준으로 벡터 유사도 검색을 돌려주는 것이다.
milvus의 벡터 검색 필터링에는 2가지 동작 방식이 존재한다. 둘다 뭔가 심오한 방식을 쓰거나 한건 아니고, 순진한 방식으로 구현되어 있다.
첫번째 동작 방식은 Standard filtering이라고 부르는데, 매우 간단하다.
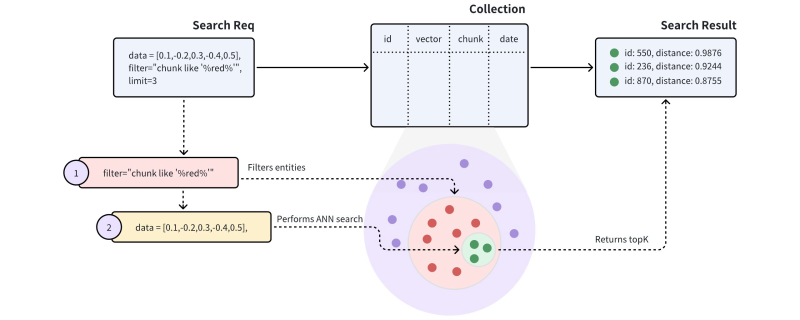
먼저 조건에 따라서 값을 전부 필터링하고, 필터링된 값들을 메모리에 로드한 다음에 거기서 벡터 유사도 연산을 돌리는 것이다.
그래서 이 방식은 필터링된 기반 데이터의 크기가 크다면 성능 효율성이 떨어질 수 있다.
두번째 동작 방식은 Iterative filtering라고 부른다.
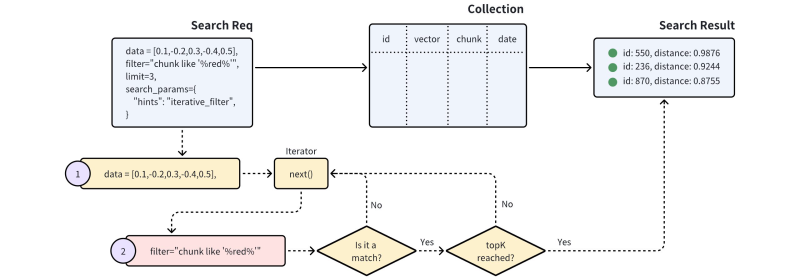 이것도 사실 그렇게 복잡한건 아니다.
이것도 사실 그렇게 복잡한건 아니다.
그래프 순회 중에 필터링을 할 때의 단점은, 너무 빠르게 순회가 중단되어서 원하는 값을 얻기가 어렵다는 것이다.
그래서 Iterative filtering은 그냥, 원하는 데이터 개수만큼을 얻을때까지 계속 뺑뺑이를 돌리는 것이다.
이게 더 훌륭한 선택인지는 잘 모르겠지만, 이런 부분에 있어서는 qdrant가 filterable index를 포함해서 기술적으로 좀 도전을 더 한거같다.
참조
https://milvus.io/docs/index-scalar-fields.md
https://milvus.io/api-reference/restful/v2.5.x/v2/Index%20(v2)/Create.md
https://www.reddit.com/r/vectordatabase/comments/1fj94ps/what_vector_database_support_proper_filtering/
https://milvus.io/docs/single-vector-search.md#Filtered-search
https://zilliz.com/blog/what-is-new-with-metadata-filtering-in-milvus
https://milvus.io/docs/filtered-search.md
https://github.com/milvus-io/milvus/discussions/35221
https://milvus.io/docs/scalar_index.md