cuda
 cuda는 현대 머신러닝 환경의 핵심이 되는 기능요소 중 하나다.
cuda는 현대 머신러닝 환경의 핵심이 되는 기능요소 중 하나다.
cuda가 대체 뭔가?
그래픽카드, GPU는 원래 진짜 그래픽 연산을 위한 장치였다. 모니터 렌더링하고 그런거 말이다.
하지만 근래에 와서 GPU의 병렬 처리 능력이 주목받게 되었다.
GPU는 하드웨어적으로 수백 수천개의 작은 코어로 구성되는데, 코어 하나하나의 단일 성능은 CPU보다 낮아서 범용으로 사용하기에는 비효율적이다.
하지만 여러개의 숫자(특히 float)로 구성되는 벡터/행렬간의 연산에 대해서는 매우 뛰어난 성능을 보여줄 수 있다. CPU는 하나하나 루프 돌면서 처리해야하는 것을 GPU는 한번에 밀어넣고 병렬처리를 해버릴 수 있는 것이다.
 .PNG?type=w800)
CUDA는 GPU를 그런 연산들을 지원하기 위한 인터페이스 라이브러리라고 보면 된다.
.PNG?type=w800)
CUDA는 GPU를 그런 연산들을 지원하기 위한 인터페이스 라이브러리라고 보면 된다.
C/C++로 작성되어있는데, 이거 자체는 너무 raw하게 되어있어서 보통은 torch 같은 추상화된 환경을 통해서 간접 호출을 하는게 일반적인 사용 형태다.
CUDA와, CUDA 기반으로 구축된 개발환경이야말로 엔비디아의 주가를 지탱하는 가장 큰 기둥이라 할 수 있다.
다른 GPU 개발사들이 성능이 떨어져서 밀리는게 아니라, 이 소프트웨어 환경 때문에 밀리는 것이다.
사용해보기
당연히 엔비디아 그래픽카드를 사용할 수 있는 환경이어야 한다.
내 경우에는 AWS EC2의 GPU 타입을 사용했다.
정보를 조회해서, 이런 식으로 나오면 사용 가능한 환경이다.
lspci | grep -i nvidia
드라이버 구성은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223867488688
Python torch로 cuda 써보기
pytorch를 통해서 cuda를 설치하고 사용해보겠다.
설치하고, import해서 실행해본다.
import torch
torch.cuda.is_available()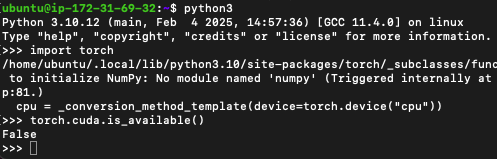 드라이버 구성이 제대로 되어있지 않다면 이렇게 False가 날 것이다.
드라이버 구성이 제대로 되어있지 않다면 이렇게 False가 날 것이다.
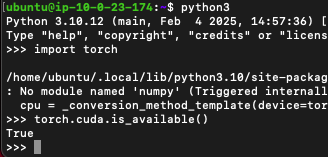 구성이 되어있다면 True가 나온다. 이래야 cuda를 쓸 수 있다.
구성이 되어있다면 True가 나온다. 이래야 cuda를 쓸 수 있다.
torch를 통해 cuda 메타데이터도 이것저것 조회할 수 있다.
print(f"CUDA 버전: {torch.version.cuda}")
print(f"GPU 개수: {torch.cuda.device_count()}")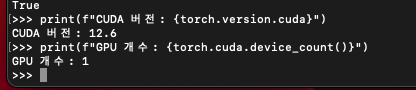
사용법은 대략 이렇다. 다음 코드는 1000x1000 행렬을 랜덤으로 만들어서 행렬곱을 돌리는 예제다.
x = torch.randn(1000, 1000).cuda()
y = torch.randn(1000, 1000).cuda()
z = x @ y # 행렬 곱셈
print("GPU 연산 성공")
print(z)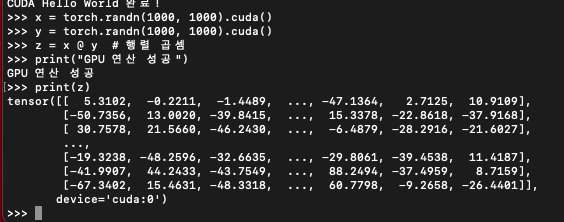 그럼 이렇게 잘 동작한다.
그럼 이렇게 잘 동작한다.
간단한 성능 비교도 한번 해보자.
import torch
import time
def bench():
# CPU에서 텐서 생성
print("\n=== CPU vs GPU 성능 비교 ===")
size = 5000
print(f"{size}x{size} 행렬 곱셈 수행 중...")
# CPU 연산 수행 및 시간 측정
start_time = time.time()
a_cpu = torch.randn(size, size)
b_cpu = torch.randn(size, size)
c_cpu = torch.matmul(a_cpu, b_cpu)
cpu_time = time.time() - start_time
print(f"CPU 연산 완료: {cpu_time:.4f}초")
# GPU 연산 수행 및 시간 측정
start_time = time.time()
a_gpu = torch.randn(size, size, device='cuda')
b_gpu = torch.randn(size, size, device='cuda')
c_gpu = torch.matmul(a_gpu, b_gpu)
# GPU 연산이 완료될 때까지 대기
torch.cuda.synchronize()
gpu_time = time.time() - start_time
print(f"GPU 연산 완료: {gpu_time:.4f}초")
# 결과 검증 (CPU와 GPU 결과가 일치하는지)
c_gpu_cpu = c_gpu.cpu() # GPU 텐서를 CPU로 이동
is_close = torch.allclose(c_cpu, c_gpu_cpu, rtol=1e-3, atol=1e-3)
print(f"CPU/GPU 결과 일치: {is_close}")
# 속도 비교
speedup = cpu_time / gpu_time
print(f"GPU 속도 향상: {speedup:.2f}배 빠름")
print("\n=== 간단한 GPU 메모리 테스트 ===")
# GPU 메모리 사용 현황 확인
print(f"메모리 할당 전 사용량: {torch.cuda.memory_allocated() / 1e6:.2f} MB")
# 큰 텐서 생성으로 GPU 메모리 사용
large_tensor = torch.ones((1000, 1000, 100), device='cuda')
print(f"메모리 할당 후 사용량: {torch.cuda.memory_allocated() / 1e6:.2f} MB")
# 메모리 해제
del large_tensor
torch.cuda.empty_cache()
print(f"메모리 해제 후 사용량: {torch.cuda.memory_allocated() / 1e6:.2f} MB")
print("\nCUDA Hello World 완료!")
bench()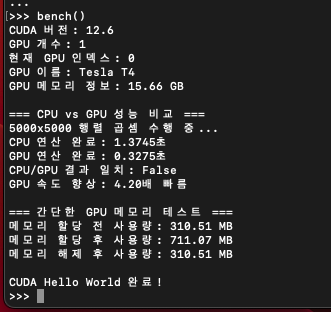 5000x5000을 돌렸을 때는 CPU로 돌릴 때보다 4배 정도 빨랐다.
5000x5000을 돌렸을 때는 CPU로 돌릴 때보다 4배 정도 빨랐다.
실제 사용사례에서는 더 크고 많은 데이터를 다루기 때문에, 이것보다 더 벌어지는 경우가 많을 것이다.