[Pytorch] 모델 만들어보기
모델을 간단하게나마 말아보면서 그 구조를 파악해보겠다.
모델 클래스 정의
대부분의 모델은 nn.Module을 상속하는 클래스를 정의하는 것으로 시작한다.
nn.Module는 신경망(Neural Network)에 대한 기본 기능 구조를 제공하는 클래스다.
한번 하나 정의해보자
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 3)
def forward(self, x):
return self.linear(x)
model = SimpleModel()
print(model)자. 여기서 nn.Linear(4, 8) 이 부분이 레이어를 정의하는 부분이다.
여기서 4가 입력에 대한 값이고, 8이 출력에 대한 값이다.
다시 말해 입력으로는 길이 4짜리 텐서(float array), 출력으로는 길이 8짜리 텐서를 반환하는 것이다. 여기서는 간결함을 위해 짧은 값을 정의했지만, 실제 사례에서는 훨씬 길 것이다.
forward는 실제로 모델에 입력이 들어올때 어떻게 동작할지를 정의한다.
이 경우에는 linear의 기본 동작을 타도록 포워딩했다.
아무튼 저대로 실행해보면
 모델 정보가 나온다.
모델 정보가 나온다.
학습 돌려보기
입력/출력 쌍을 4개 정도만 정의해서 학습을 시켜보겠다.
x = torch.tensor([[1.0, 1.0], [2.0, 2.0], [3.0, 3.0], [4.0, 4.0]])
y = torch.tensor([[3.0, 5.0, 7.0], [5.0, 7.0, 9.0], [7.0, 9.0, 11.0], [9.0, 11.0, 13.0]])x가 입력, y가 출력이다.
이 2차원 배열을 tensor라고 부르고, 안에 들어있는 작은 배열들을 row나 sample이라고 부른다.
위에서 정의한 입력과 출력에 대한 크기 정의는 이 row에 대한 것이었다.
그리고 입력 텐서의 길이와 출력 텐서의 길이는 같아야 한다.
x[0]와 y[0]이 각각 한 쌍의 입출력 쌍이 되는 것이기 때문이다.
그러면 저 입/출력 값을 집어넣고 돌려보자.
criterion = nn.MSELoss() # 평균제곱오차
optimizer = optim.SGD(model.parameters(), lr=0.01) # 확률적 경사하강법
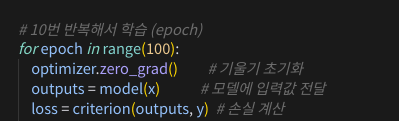
# 10번 반복해서 학습 (epoch)
for epoch in range(1000):
optimizer.zero_grad() # 기울기 초기화
outputs = model(x) # 모델에 입력값 전달
loss = criterion(outputs, y) # 손실 계산
loss.backward() # 역전파
optimizer.step() # 파라미터 업데이트
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/1000], Loss: {loss.item():.4f}')
# 결과 확인
print("학습된 가중치:", model.linear.weight.tolist())
print("학습된 편향:", model.linear.bias.tolist())조금 뭐가 이것저것 복잡하긴 한데, 얼개만 훑어보겠다.
분명히 값 세트 하나만을 넣어서 돌리는데도 뭔가 거창하다. 무슨 오차 범위에 대한 대응을 하는데다, 루프를 1000번이나 돌리고 있다.
이건 ML 매커니즘 자체의 근본적인 한계에서 기인하는 처리 방식이다.
일반적으로 입출력 값을 넣어서 학습을 시키더라도, 항상 손실이 발생하기 때문이다. 그래서 여러번 집어넣어서 돌려야 손실을 최소화할 수 있고, 이 여러번 돌리는 횟수를 epoch라고 부른다.
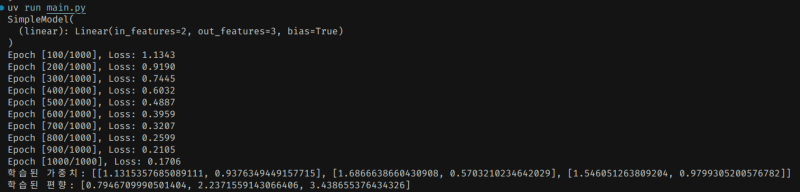 실제로 돌리면 돌릴수록 손실(Loss)이 줄어드는 것을 볼 수 있다.
실제로 돌리면 돌릴수록 손실(Loss)이 줄어드는 것을 볼 수 있다.
학습을 돌리고 나면, 모델을 찔러서 그 결과를 확인해볼 수 있다.
학습했던 데이터를 그대로 또 밀어넣어서 뭐가 나오는지 보자
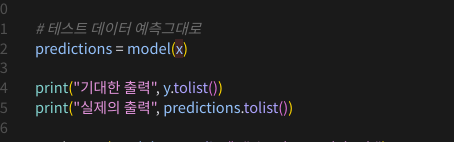
 그럼 비슷하긴 한데 뭔가 다른 값이 나온다.
그럼 비슷하긴 한데 뭔가 다른 값이 나온다.
 게다가 동일한 횟수로 학습을 돌려도, 돌릴때마다 다른 값이 나온다.
게다가 동일한 횟수로 학습을 돌려도, 돌릴때마다 다른 값이 나온다.
학습 과정 자체는 결정적으로 이루어지지 않는다.
하지만 학습 횟수를 줄여서 손실량이 늘어나면
 그만큼 출력값의 정밀도는 확실히 낮아진다. 전보다 동떨어진 값이 떨어진 것을 볼 수 있다.
그만큼 출력값의 정밀도는 확실히 낮아진다. 전보다 동떨어진 값이 떨어진 것을 볼 수 있다.
모델 파일 완성하기
학습이 끝났다면, 이제 바로 모델 파일을 생성할 수 있다.
 이 방법은 state_dict 방식의 모델이라고 하는데, 이거 말고도 몇가지 더 있으나 별도 포스트에서 다루겠다.
이 방법은 state_dict 방식의 모델이라고 하는데, 이거 말고도 몇가지 더 있으나 별도 포스트에서 다루겠다.
 그럼 이렇게 파일이 생성된다.
그럼 이렇게 파일이 생성된다.
이 경우에는 뭣도 없어서 크기가 굉장히 작은데, 보통은 거의 N~NN기가급으로 나온다.
그러면 이걸 그대로 가져다가 쓸 수 있다.
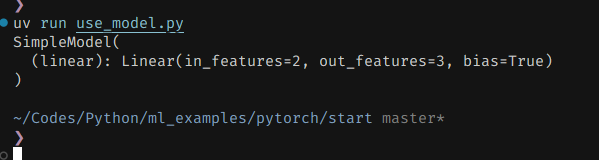 로드해보면, 모델 정보와 함께 모델이 초기화될 것이고
로드해보면, 모델 정보와 함께 모델이 초기화될 것이고
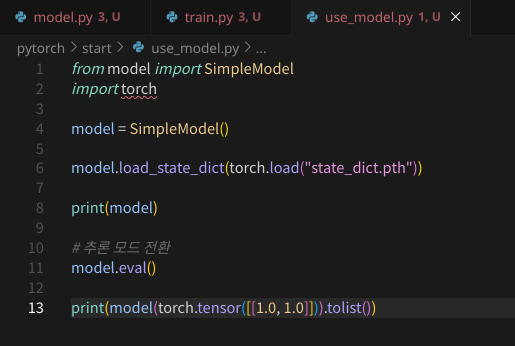
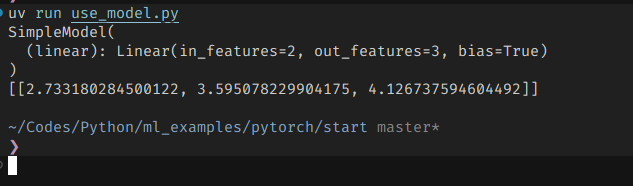 바로 입력을 때려넣어서 출력값을 받아올 수도 있다.
바로 입력을 때려넣어서 출력값을 받아올 수도 있다.
일반적인 흐름은 이렇다. 중간에 이런저런 변주나 잡기술들이 들어갈 수 있지만, 이 근간에서 벗어나지 않는다.